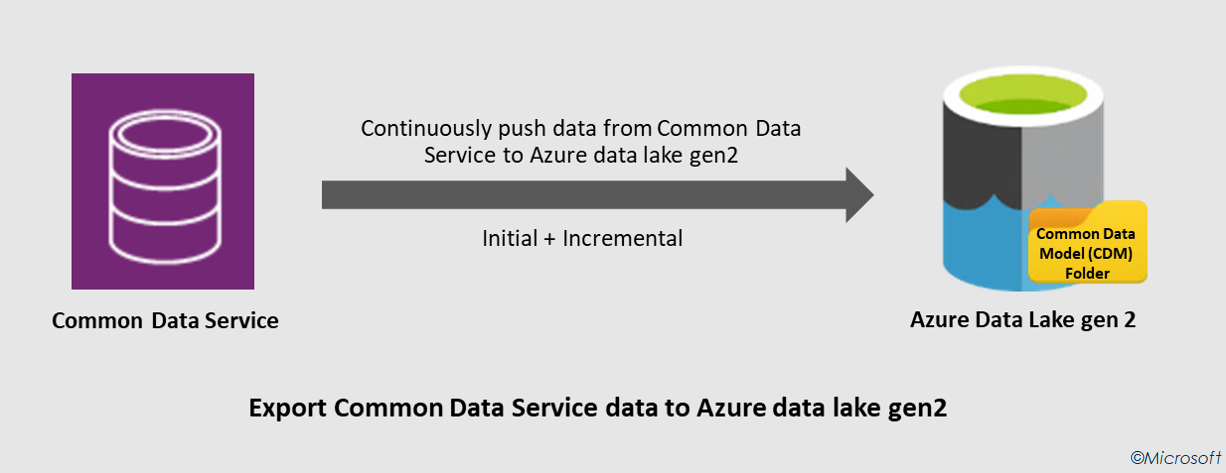
If like me, you’ve been keeping tabs on what Microsoft has been up to on the Power Platform world, you would have noticed that there are two concepts that are regularly referenced in their architectures and generally associated to each other – Azure Data Lake Storage (ADLS) Gen 2 and Common Data Model (CDM).
As my colleague, Francesco Sbrescia, referenced in his blog, Microsoft’s ultimate goal is for the CDM to be the de facto standard data model. However, although there is a fair amount of resources talking about the capabilities and features, it can be a bit confusing to understand how you can actually store your data in the CDM format in ADLS and use it to run data analytics such as data warehousing, Power BI reporting and Machine Learning.
In this blog series I’ll cover 6 different ways to instantiate a CDM model in ADLS:
- Export to data lake (Common Data Service)
- Power BI Dataflows
- Azure Data Services – Databricks
- Azure Data Services – Data Factory Data Flows
- Synapse Link for Dataverse – Delta Lake Export
- Dataverse integration with Microsoft Fabric
Let’s start by having a look at the first option and understand how it works.
Export to data lake (code name Athena) is a Power Apps service that allows Common Data Service (CDS) customers to continuously push their data to ADLS in the CDM format (further details here). The greatest thing about this service is the ability to incrementally replicate the CUD operations (create, update, delete) in ADLS without having to run manual/scheduled triggers. Any data or metadata changes in CDS are automatically pushed to ADLS without any additional action. Read-only snapshots are created every hour in ADLS, allowing data analytics consumers to reliably consume the data.
There are two major aspects to bear in mind before attempting to use this service. First, the storage account must be created in the same Azure AD tenant as your Power Apps tenant and second, the storage account must be created in the same region as the Power Apps environment that will host the applications.
To test this service, I went ahead and created an application based on the CDM Contacts entity (you can follow this link to understand how to create an app using CDM).
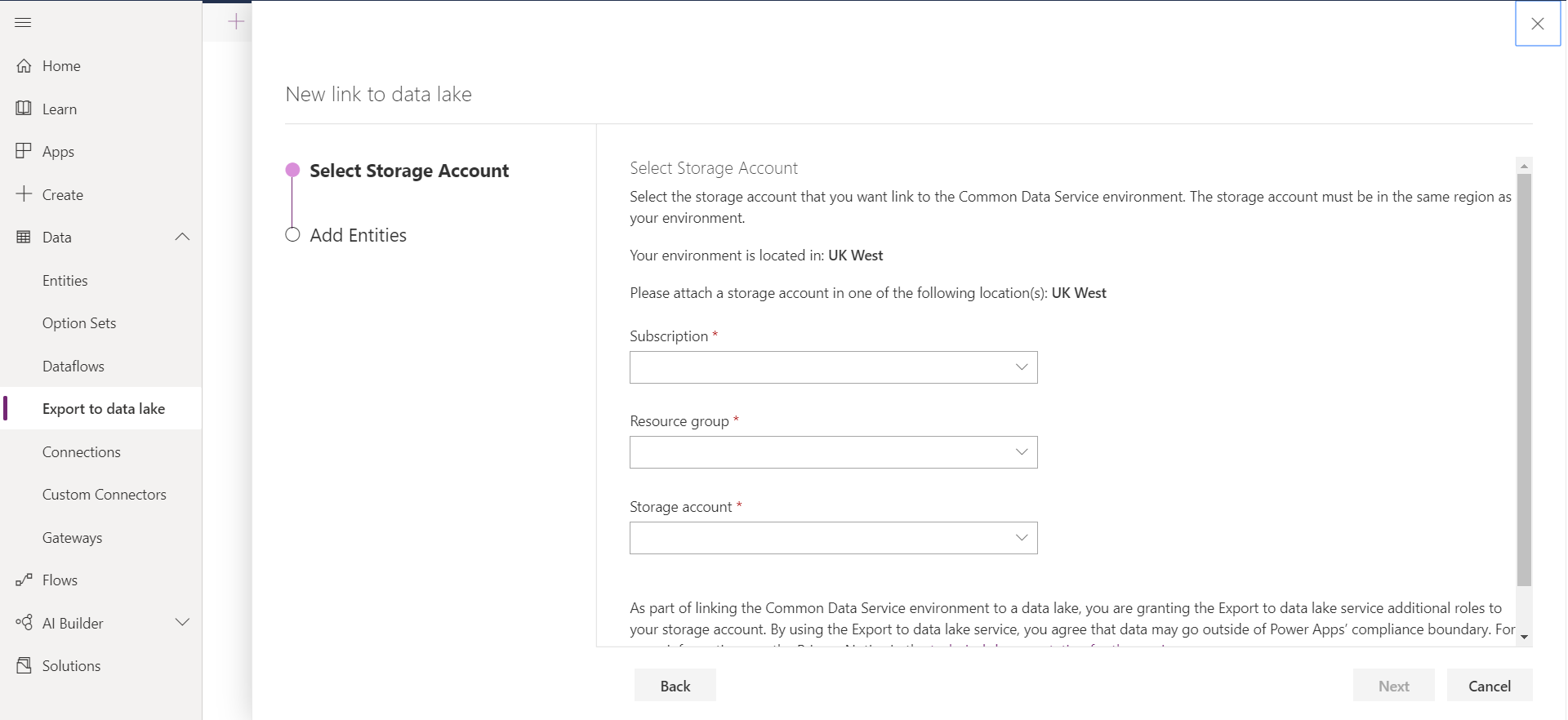
The next step is to create a new link to the data lake and select which entities you want to export. As previously mentioned, you will be asked to attach a storage account in the same location of the Power Apps tenant. You will also need to be the Owner of the storage account and the administrator of the CDS.
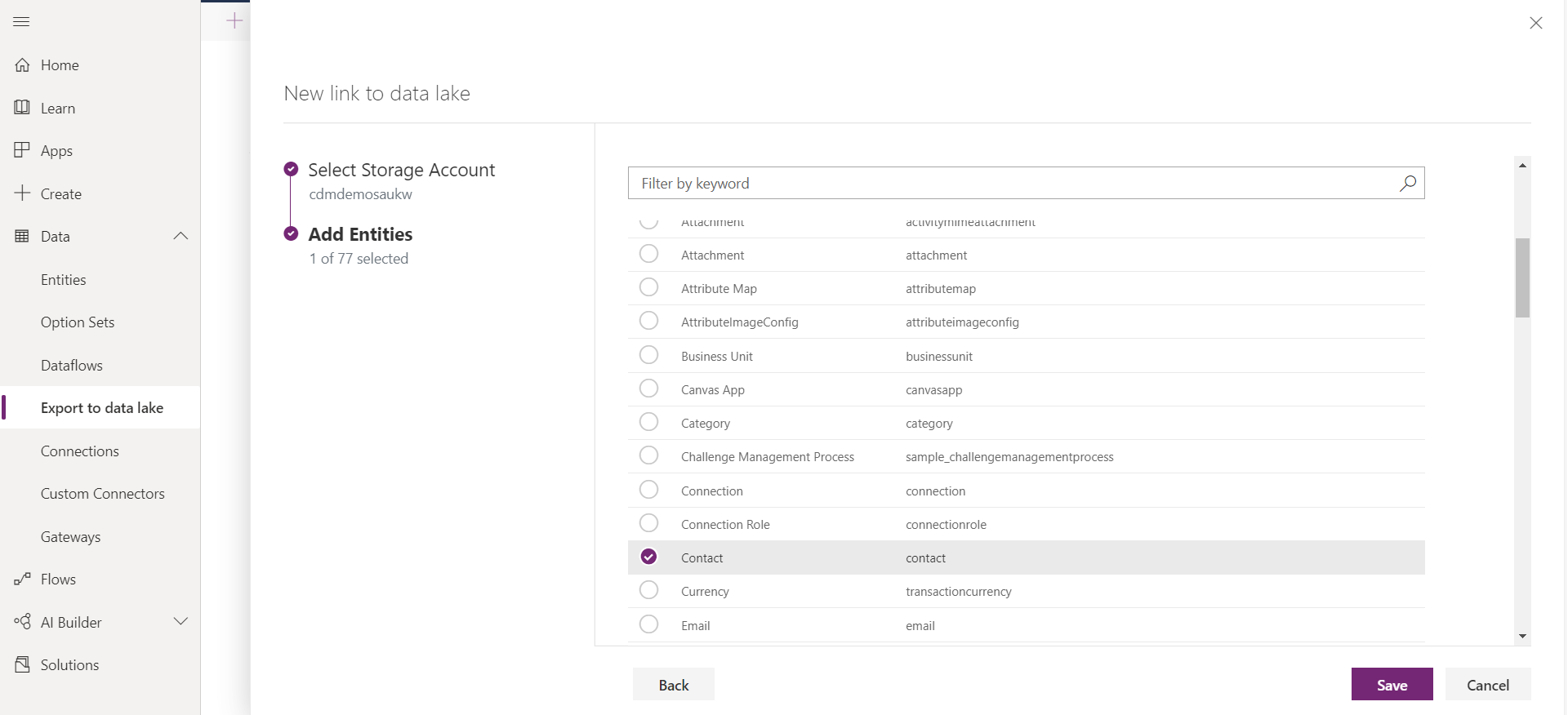
Once you press save, the CDS environment is linked to ADLS and the selected entities are replicated to the storage account.
On the Power Apps portal you will see a dashboard showing the status (Initial sync and Last sync status), the last synchronised timestamp and the count of records for each selected entity.
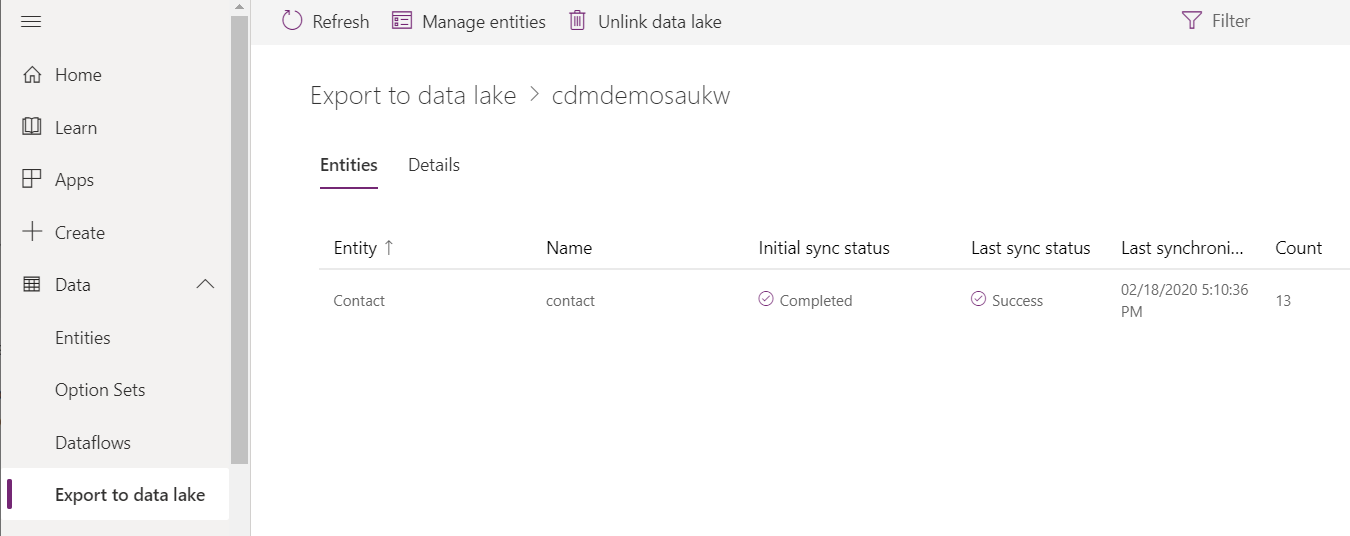
On the storage account, you will see two new containers, one for the link you just created and another for the power platform dataflows. Within the first container, you will have a model.json file, a folder for the Trickle Feed Service and a folder for each selected entity.
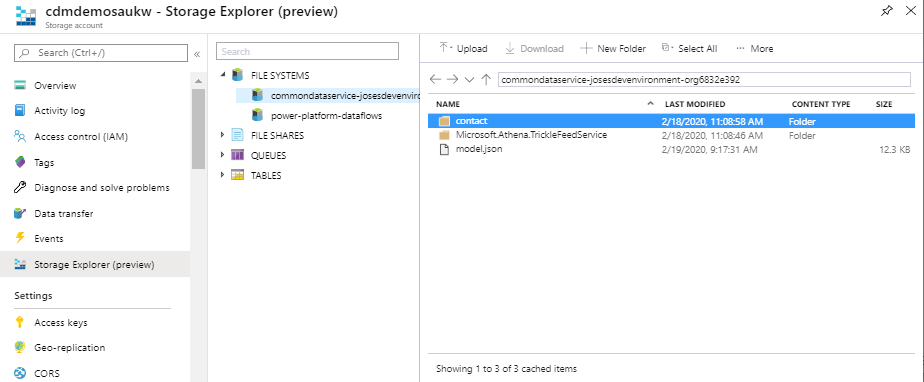
Model.json
The model.json file describes the data in the CDM folders, metadata and location (further details here). The file allows data consumers to easily understand which entities exist in the storage account and how they are structured and partitioned. The file also contains annotations that provide details about the initial sync status and completed time.
The entities replicated to the data lake are partitioned by year in order to make it more efficient for the consumer applications to consume the files. As per Microsoft, the plan is to eventually partition based on the amount of the data.
The model.json file will only include the location of the latest snapshot. Whenever a new entity snapshot is created, a new model.json snapshot is taken to ensure that the original snapshot viewer may continue to work on the older snapshot files while newer viewers can read the latest updates.
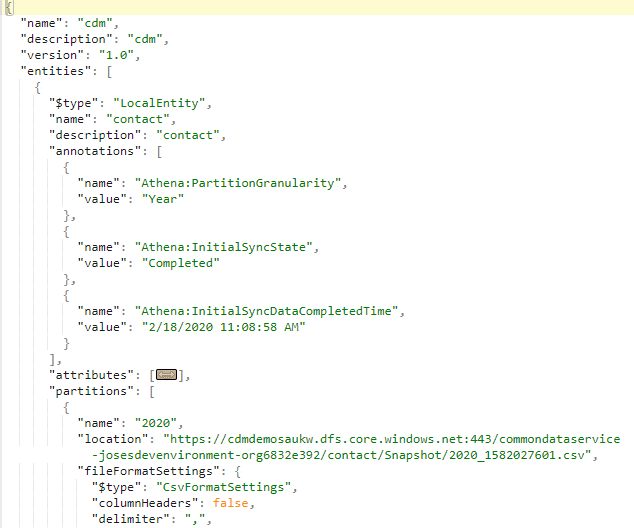
Trickle Feed Service
Trickle feed is the process of supplying continuous small amounts of something. In this scenario, changes in CDS are continuously pushed to the corresponding csv files using the trickle feed engine. Below, is the content of the TrickleFeedService folder.
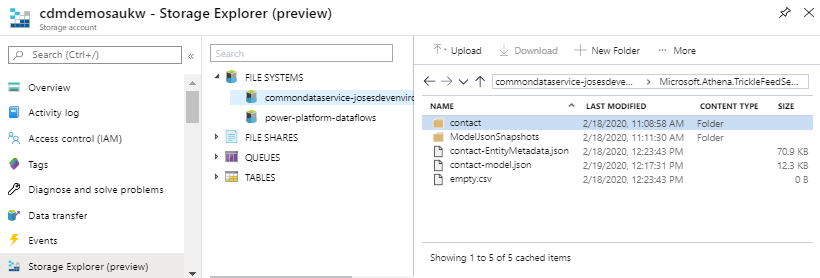
In this scenario, we have a contact folder, an EntityMetadata and a model json files. The contact folder contains files used by the Trickle Feed service, that are updated every time a CUD operation happens in CDS.
The contact-model.json file is the same as the model.json file, but, will only contain the details about the contact entity. This file is updated whenever there are structural changes in CDS, while the model.json file in the root folder, will only be updated on an hourly basis.
The contact-EntityMetadata.json file contains multiple metadata properties as demonstrated below.

The ModelJsonSnapshots folder contains the model.json snapshots. A read-only snapshot copy is taken every hour, independently of changes in CDS occur.
Entity folder
Each entity will have a folder containing the partitioned csv files and the snapshot copies (at some point, it will also support parquet files). Each file is named after it’s partition, which in this case is year. The 2020 file contains the most up to date version of the CDS data. Whenever there’s a CUD operation, this file is updated, however, the snapshot read-only copy is created only after the hour cycle is completed (as demonstrated in the below screenshots).
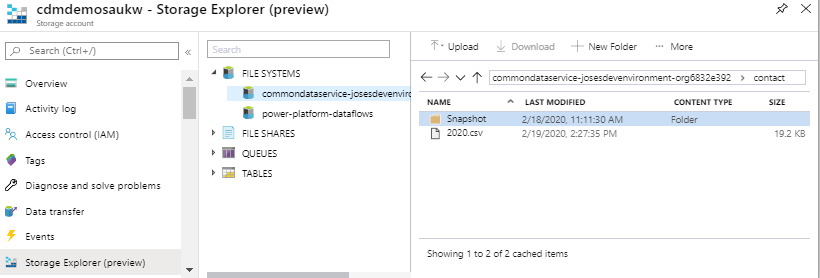
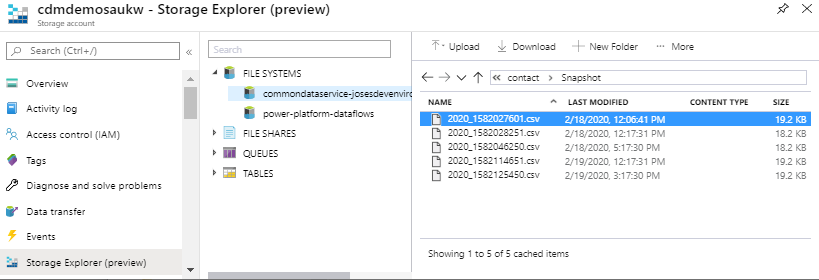








As the model.json file contains the schema definition and CSV files have no column names.
Then how to consume the Data Lake data for reporting?
Appreciate you answer
Hi Amir,
Is there a specific reporting tool you want to use?
To consume the CDM data from ADLS in Power BI you need to create a Power BI Dataflow as demonstrated in this blog (https://adatis.co.uk/the-common-data-model-in-azure-data-lake-storage-power-bi-dataflows/).
Hi Sir,
Am trying to load the on premise SQL DB tables to Azure Data lake.
i have created the corresponding linked services and exported the data from SQL DB to Azure Data Lake.
Now i need to load the incremental push records. This one also i have achieved using change tracking technology.
Now both files are seperate files.
How i need to update the incremental push records into an existing file without disturbing the other records which are not modified.
Because if am trying to merge those two files and it will create the new seperate file only. So finally extra data count occurs (data which are not modified also need to write the new file).
So is there any way to push the incremental records in the existing file without disturbing the unmodified records in existing file.
Hi Vigneshvaran,
Apologies for my late response.
I’m not sure I fully understood your question. How did you export the data from the on premise SQL DB to the Data Lake and how did you export the data from Azure SQL DB to the Data Lake? What is your final goal, migrate the data from an on premise SQL DB to Azure?
Hi Sir,
I want to load the data using ADF through common data model. I have exported the data to adls from power apps and have the same folder structure shown by you. The ms website doc converts the model.json to manifest file. The package provided are not accessible and missing in nuget as well. Can u temme how to perform data load thru ADF.
Apologies, I wasn’t notified of your first post.
Hello Jose,
How to update model.json file to accommodate snapshot details?
Hi Milind,
The model.json file is managed by the service and you should not update it. If you update the file, it will be overwritten the next time there’s a structural change in your CDS model.
Is there a particular reason for your request?
Hi Jose,
How to create the manifest.json from model.json file ?
As far as I’m aware there’s no easy straight way to make such conversion. In this series I showed how to do that by using Databricks and ADF Dataflows, but there are limitations in both approaches.
Hi Josh,
I am working on pulling ADLS v2 entities (dynamics 365 exported data to) to onprem using spark. I am not sure how metadata changes (new field addition, dropping few fields, reorder of fields in dynamics) in dynamics get reflected in ADLS data and how to handle that. for e.g. lets say 2 new field is added to contact entity, now what happens to historical data.
If you are using the Export to Data Lake feature then all metadata changes are reflected in the lake, providing such entities in Dynamics are configured accordingly. The partitioned files containing the data and the model.json will be updated shortly after the changes are applied in dynamics.
The partitioned files will always contain the most recent structure. If you require to have access to history changes then you would have to look at the snapshot folders.
If you are uncertain how often the schema will change, then you could build a process that reads the model.json file and validates the schema before you attempt to copy the data to your final destination from the lake.
Hi ,
As the model.json file contains the schema definition and CSV files have no column names.
Then how do we load data from ADLSG2 to Azure SQL (We have 2020 as one file , 2021 as another file ) . how do we load ?
Appreciate you answer
It depends how you plan to load your data in Azure SQL. If you are using ADF Data Flow, you have access to the schema due to the Common Data Model source type(as shown here).
If you are using ADF, then there will be some manual work to ensure you can map the columns accordingly.
Alternatively, you can always use the Dataverse (Common Data Service for Apps) dataset and connect directly to your dynamics application and skip the data lake.
After the initial link between Power apps and the Data lake – the model.json is incomplete and is not updating every hour as you suggest.
When i try to connect to an entity I can see a folder for in the Data lake, using ADF i get an error
Could not read ‘/sbr_area’ from the ‘cdm’ namespace. Reason ‘com.microsoft.commondatamodel.objectmodel.storage.StorageAdapterException: Could not read content at path: /logical/sbr_area
Any ideas?
Hi Matthew,
Apologies for my late response but I was OOO.
Without understanding your scenario and how it was setup, I can’t offer much support unfortunately. I would suggest to check your setup in Power Apps and see if you can find any error or if you are using a custom entity and you didn’t configured it to track the changes. Without this step, you will not see it correctly synced to the data lake.
With regards the error you are seeing in Data Factory. Please refer to this blog. As you will see, at the time I was testing, Data Factory could not read CDM entity files based on model.json, only the ones using the most recent manifest files. This could be the reason why you are having such errors.
Hi Jose,
I really like your blog and detailed description i have a challenge i need to connect to cdm via databricks can you suggest how i can achieve this
Hi Veronica,
Apologies for the delay in my response. The post has not been updated for a while, but the principle should still be there (Ingest CDM from Databricks)
I do have similar issue facing. I could see entry in the model.json for a entity but no files inside the entity folder in ADLS container. Is there way to handle if there are no files to load skip that entity for processing. I have seen property “allow no files found” on Dataflow setting but that seems not working.
Please let me know how you handled this scenario.
Hi Ram,
I have been really busy with work but I will try to find some time and see if I can come back to you with an answer.
Hi,
is it possible somehow export CDM formated files into SQL server as External Tables in the way that SQL extracts the metadata from the ‘model.json’? If yes, could you give any idea how to do that?
Hi Elshan,
Apologies for the delay getting back to you. If you want to extract the data from dynamics to Synapse, then you can use Azure Synapse Link for Dataverse
Hi Jose,
Thanks for great knowledge sharing. I am using Azure Synapse Link for Dataverse along with ADF to copy data in Azure SQL. However, on each sync there is error that Objects already exists in database. I have deleted Tables and ten executing that, but still getting the same error. I am using Copy Dataverse data into Azure SQL template to do all this.
Regards
Wajih