Topic models are built using unsupervised learning and their purpose is to assist with text summarisation and understanding as they can align unseen documents to predefined lists of terms, known as topics, thereby highlighting the key content of that document. The strength of a topic model comes from its ability to generalise a group of training documents into a fixed number of topics with the assumption that new documents are made up of a mix of a small number of topics. The algorithm covered in this blog is known as Latent Dirichlet Allocation (LDA) however other topic modelling algorithms exist such as the BERT model developed by Google and Latent Semantic Analysis (LSA). One issue with topic models is that they need to be trained on large amounts of content and this can be difficult when working on local machines. This blog will use Azure Databricks to process the text, train and save the LDA topic model and classify a new, unseen document in a distributed way.
When building an LDA model there are some challenges to overcome,
1. The first challenge when building an LDA model is the text pre-processing. All documents will contain words that are semantically the same but have some pluralisation, tense transformation or other forms of word variation and these should be dealt with to ensure consistency in the topics and avoid duplication of terms that carry the same meaning.
2. The next challenge is the abundance of noise in documents, words that are used to enhance the flow and structure of sentences but do not contribute to the core meaning. These are often referred to as stopwords and should also be removed.
3. Finally, the model needs to be evaluated and given the unsupervised nature of topic models, this can present some challenges.
1. Setting up the Environment
This blog walks through the creation of an LDA model using Azure Databricks, which provides excellent scalability over working on a local machine when training against large amounts of content, although this also introduces some challenges.
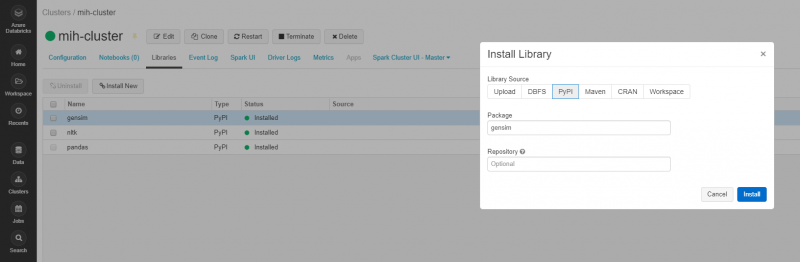
Assuming you are already familiar with databricks and the concept of clusters (if not, go here), you will need to install some python libraries onto the cluster so that an LDA model can be built. The libraries required are Gensim, pyLDAvis, and NLTK. To install these navigate to the cluster window, click “Libraries”, “Install New” and then type the name of the PyPI package to be installed. The below image shows the install for the genism package.
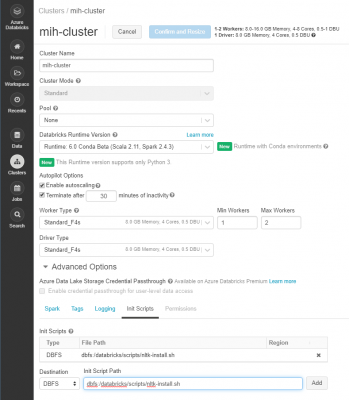
Once you have the libraries installed you also need to add an initialisation script for NLTK so that the library can be installed on each node of the cluster. To do so, open a new notebook and use the following code to put an install script into the cluster.
dbutils.fs.mkdirs("dbfs:/databricks/scripts/")
dbutils.fs.put("/databricks/scripts/nltk-install.sh",""" #!/bin/bash python -m pip install nltk python -m pip install --upgrade pip python -m nltk.downloader all """, True)
display(dbutils.fs.ls("/databricks/scripts/nltk-install.sh"))
Once the notebook has completed, copy the path shown and navigate back to cluster window. Click “Edit”, choose “Advanced Options” and open the “Init Scripts” tab at the bottom. Paste the path into the text box and click “Add”. Once the cluster restarts each node will have NLTK installed on it.
2. Create a notebook
Open the Databricks workspace and create a new notebook. The first cmd of this notebook should be the imports that are required for model building, these are shown below:
#spark from pyspark.sql.types import * from pyspark.sql.function import * # gensim import gensim from gensim.utils import simple_preprocess from gensim.parsing.preprocessing import STOPWORDS from gensim.models.coherencemodel import CoherenceModel from gensim.test.utils import datapath from gensim import corpora, models # nltk import nltk from nltk.corpus import stopwords from nltk.stem import WordNetLemmatizer, SnowballStemmer from nltk.stem.porter import *
Run this cell and ensure it completes successfully. If there are errors here it is likely due to an issue with the library installs covered above.
3. Access the content
The simplest method to access data outside of databricks is to mount the storage drive, although this does introduce some security concerns it is perfect for the purposes of this blog. Use the following code to mount a simple blob storage account to the databricks cluster. Note, this uses a kay vault backed secret scope, to find out more about this setup, go here.
try:
dbutils.fs.mount(
source = "wasbs://lda-documents@ldablogstorage.blob.core.windows.net",
mount_point = "/mnt/docs",
extra_configs = {"fs.azure.account.key.ldablogstorage.blob.core.windows.net":dbutils.secrets.get(scope = "mih- secret-scope", key = "AccessKey-DocStore")})
except:
print("Directory already mounted")
Whilst this provides access to the content, it does not actually read it in to the notebook. To do so you should create a readDoc function that can extract the content from a simple .txt file. More complex file types could be used however you would need custom libraries such as PyPDF or pyton-docx in order to do so. The following code creates a readDoc custom function and then uses it to read in each file in the mounted storage area.
def readDoc(path):
fixedPath = path.replace('dbfs:', '/dbfs')
f = open(fixedPath, 'r')
content = f.read()
return content
contentList = [readDoc(path[0]) for path in dbutils.fs.ls("mnt/docs") if path[0][-3:] == 'txt']
df = spark.createDataFrame(sc.parallelize(contentList), StringType())
display(df)
The output of this code is a spark dataframe with a row for each document’s content
4. Pre-process the content
Before the LDA model can be trained, the content needs to be processed in order to deal with challenges one and two mentioned above. The first step here is to tokenize each document, meaning to turn each word of the document into an item in a list, and reduce the word to its lemma with lemmatization. Following this we have to remove the stopwords so that they do not interfere with the words that actually denote the meaning of the document. To do all of this processing we can write a simple user defined function which can then be run over the dataframe, giving us great parallel performance for what would otherwise be quite a taxing activity. The code below defines a preprocess user defined function which returns an array of cleaned, lemmatized tokens.
def preprocess(text):
result = []
if text is not None:
for token in gensim.utils.simple_preprocess(text):
if token not in gensim.parsing.preprocessing.STOPWORDS and len(token) > 3:
result.append(SnowballStemmer("english").stem(WordNetLemmatizer().lemmatize(token, pos='v')))
return result or ["null"]
preprocess = udf(preprocess, ArrayType(StringType()))
This function can then be invoked for each document in the dataframe by calling the below command.
dfCleaned = df.withColumn("cleanContent", preprocess(col("value")))
5. Create LDA specific artifacts
So that the LDA model can be built, there are some objects that need to be created as these are used throughout the model training process. The first of these is a dictionary, which maps each word to an identifier, and then a bag of words, that shows a count for each word across each document. To create the bag of words you must transpose the spark dataframe back into a python list and then turn this into the dictionary.
In addition, at this stage you can specify filters on this dictionary to remove the extreme values, meaning those terms that do not appear in enough documents and those that appear in too many documents. This is useful as it ensures the terms that make up each topic are used broadly across the documents but not used in every document, therefore avoiding words that do not help to segment the content into isolated topics.
Finally, the bag of words can be created from the processed content and the filtered dictionary just created. The below code takes care of each of these steps.
processedDocs = dfCleaned.rdd.map(lambda x: x[1]).collect() dict = gensim.corpora.Dictionary(processedDocs) dict.filter_extremes(no_below=4, no_above=0.8, keep_n=10000) bowCorpus = [dict.doc2bow(doc) for doc in processedDocs]
To preview the bag of words for a document you can run the following code. This will print each word and the number of occurrences in the given document.
bow_doc_1 = bowCorpus[0]
print("Showing bag of words for doc 0")
for i in range(len(bow_doc_1)):
print(f"Word {bow_doc_1[i][0]} (\"{dict[bow_doc_1[i][0]]}\") appears {bow_doc_1[i][1]} time.")
6. Train the LDA Model
When training the LDA model it is best to start simple and gradually increase complexity as your understanding grows. The key parameter to start with is the number of topics (num_topics) which in the below scenario is 7. The full set of training parameters is documented here but to initially train the model use the following code,
ldaModel = gensim.models.LdaMulticore( bowCorpus, num_topics=7, id2word=dict )
Once you have a trained model we need to gather the evaluation metrics so that we can solve the third challenge listed above. The metrics we will use are,
Perplexity score: This metric captures how surprised a model is of new data and is measured using the normalised log-likelihood of a held-out test set.
Topic Coherence: This metric measures the semantic similarity between topics and is aimed at improving interpretability by reducing topics that are inferred by pure statistical inference.
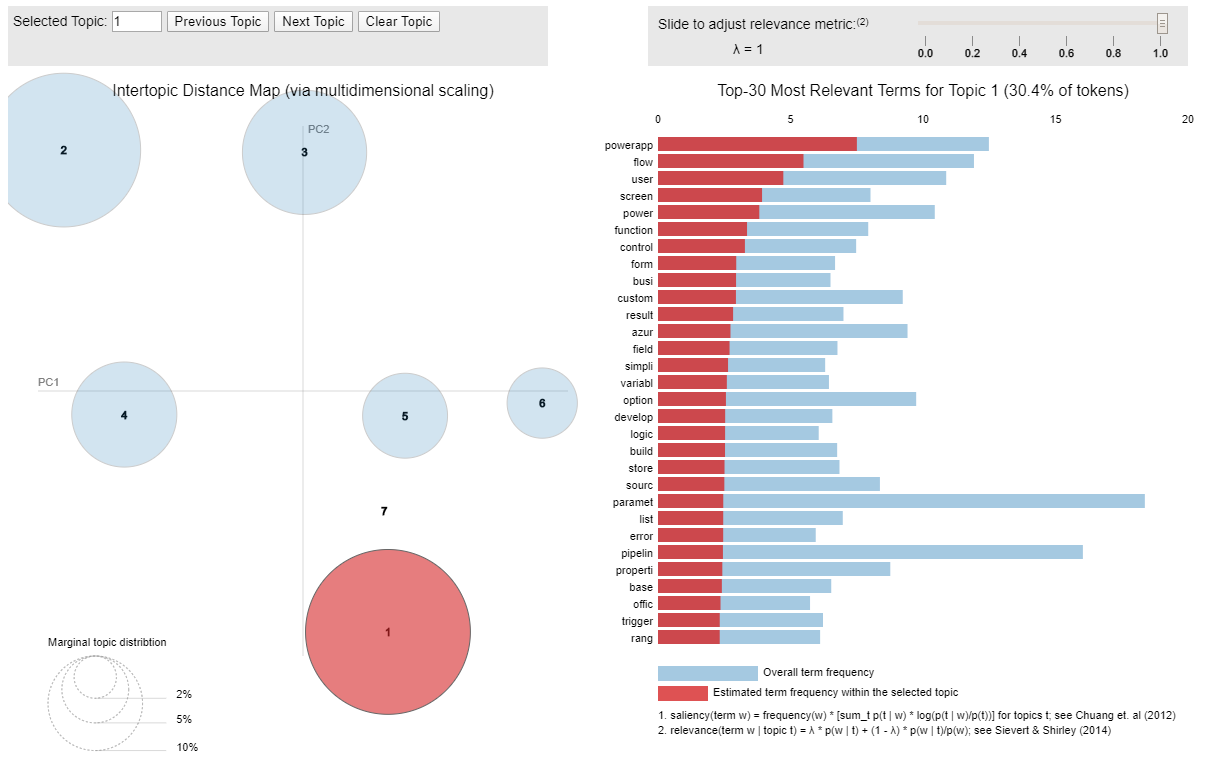
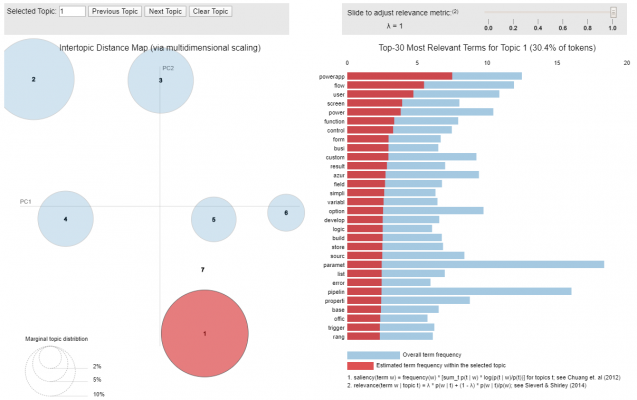
Additionally, the topics and topic terms can be visualised to help assess how interpretable the topic model is. The following code prints the perplexity and coherence scores followed by the visualisation plot.
# Compute Perplexity
print('LDA Perplexity: ', ldaModel.log_perplexity(bowCorpus)) # a measure of how good the model is. lower the better.
# Compute Coherence Score
coherenceModelLda = CoherenceModel(model=ldaModel, texts=processedDocs, dictionary=dict, coherence='c_v')
coherenceLda = coherenceModelLda.get_coherence()
print('LDA Coherence Score: ', coherenceLda)
import pyLDAvis.gensim
pyLDAvis.enable_notebook()
import warnings
warnings.filterwarnings("ignore", category=DeprecationWarning)
pyLDAvis.gensim.prepare(ldaModel, bowCorpus, dict, mds='mmds')
After reviewing the topics above and the evaluation metrics, you may decide to refine the LDA model with some additional parameters. By adding the below configurations to the training function, a more coherent model can be achieved.
Alpha: The alpha parameter essentially provides a value for the likelihood that an unseen document will fall into each topic. A lower alpha will make new documents fit closer to topics, instead of being a blend of several topics
Eta: This parameter affects how many terms belong to a topic. A lower value here will mean topics have fewer words
Offset: The offset parameter slows down the first steps of the first few iterations and is useful when working with smaller sets.
ldaModel = gensim.models.LdaMulticore( bowCorpus, num_topics=7, id2word=dict, alpha=0.01, eta=0.5, offset=8 )
7. Save your model and classify new documents
Once you are happy the model is trained sufficiently it can be saved into your mounted storage area so that it can be used in other notebooks or functions. The code for this is shown below:
ldaModel.save('/dbfs/mnt/docs/model')
Now you have a completed model, unseen documents can be evaluated with this trained topic model, producing an array of float values that represent the topic probability distribution for the document.
The following code loads the previously saved model and then scores an unseen document, highlighting which topic the new document belongs to.
lda = ldaModel.load('/dbfs/mnt/docs/model')
print(lda)
# Read new doc
contentList = [readDoc(path[0]) for path in dbutils.fs.ls("mnt/docs/test/") if path[0][-3:] == 'txt']
df = spark.createDataFrame(sc.parallelize(contentList), StringType())
# Clean new doc
dfCleaned = df.withColumn("cleanContent", preprocess(col("value")))
# Produce artifact
processedUnseenDocs = dfCleaned.rdd.map(lambda x: x[1]).collect()
bowCorpus = [dict.doc2bow(doc) for doc in processedUnseenDocs]
# Predict topic
topics = lda.get_document_topics(bowCorpus, 0.5)
# Display topics
i = 0
for topic in topics[i]:
print(f"Topic {i + 1}: {topic} Words: {lda.show_topic(topic[0], 10)}")
i += 1
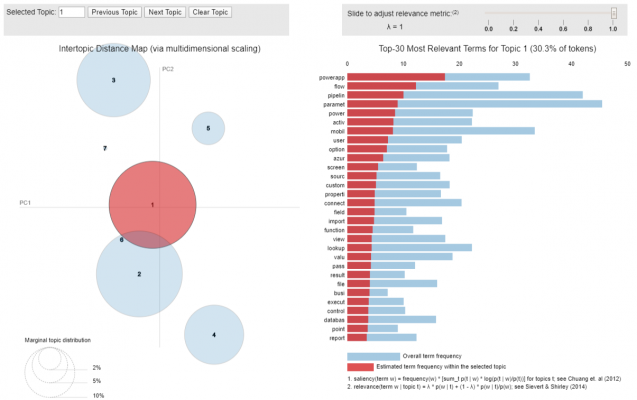
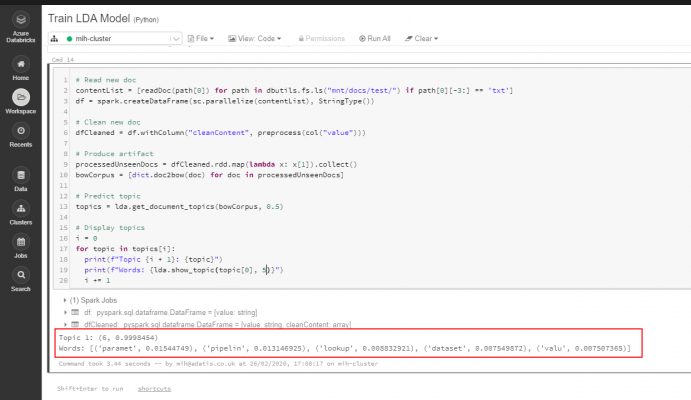
The below screen shot shows the predicted topic of an unseen document. In this case the LDA model correctly identified that the document contained content related to Azure Data Factory, due to the fact it assigned topic 6 as the most prominent topic, that contained terms such as “parameter”, “pipeline”, “lookup”, “dataset” and “value”.








Hi Matt,
I’m having a lot of trouble getting nltk set up on the cluster, i keep running into an issue where Resource wordnet cannot be found please use the nltk downloader to obtain the resource.
This is after registering the init scripts and even manually running the shell command.
Not sure if you’ve encountered this but if you’ve got any ideas of how to get past this i’d really appreciate it 🙂
Thanks!