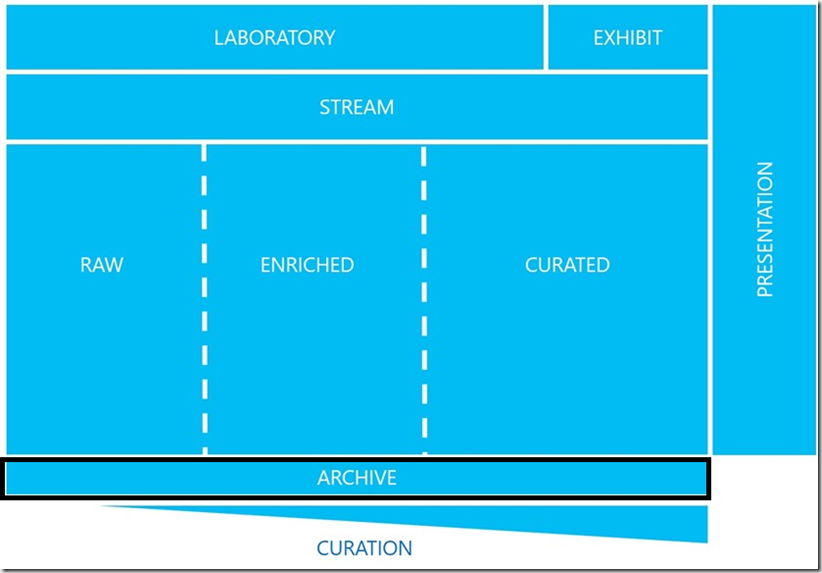
In a blog introducing the Data Lake Framework, keen readers will be aware that in the diagram there’s a box titled “ARCHIVE” but it has not been brought up since. The reason why the Archive layer in the data lake has not been discussed is because we’ve been waiting for the Archive Tier in Blob Storage.
To remind readers of the framework and where the archive layer sits in it, here it is again with the archive layer highlighted.

The Archive Blob
The Archive access tier in blob storage was made generally available today (13th December 2017) and with it comes the final piece in the puzzle to archiving data from the data lake.
Where Hot and Cool access tiers can be applied at a storage account level, the Archive access tier can only be applied to a blob storage container. To understand why the Archive access tier can only be applied to a container, you need to understand the features of the Archive access tier. It is intended for data that has no or low SLAs for availability within an organisation and the data is stored offline (Hot and Cool access tiers are online). Therefore, it can take up to 15 hours for data to be made online and available. Brining Archive data online is a process called rehydration (fitting for the data lake). If you have lots of blob containers in a storage account, you can archive them and rehydrate them as required, rather than having to rehydrate the entire storage account.
Archive Pattern
An intended use for the Archive access tier is to store raw data that must be preserved, even after it has been fully processed, and does not need to be accessed within 180 days.
Data gets loaded into the RAW area of the data lake, is fully processed through to CURATED, and a copy of the raw data is archived off to a blob container with a Cool access tier applied to it. When the archive cycle comes about, a new Cool access tiered blob container is created and the now old container has its access tier changed to Archive.
For example, our Archive cycle is monthly and we have a Cool access tiered blob container in our storage account called “December 2017”. When data has finished being processed in the Azure Data Lake, the Raw data is archived to this blob container. January comes around, we create a new blob container called “January 2018” with Cool access tier settings and change the access tier of “December 2017” from Cool to Archive.
This data has now been formally achieved and is only available for disaster recovery, auditing or compliance purposes.
Introduction to Data Wrangler in Microsoft Fabric
What is Data Wrangler? A key selling point of Microsoft Fabric is the Data Science
Jul
Autogen Power BI Model in Tabular Editor
In the realm of business intelligence, Power BI has emerged as a powerful tool for
Jul
Microsoft Healthcare Accelerator for Fabric
Microsoft released the Healthcare Data Solutions in Microsoft Fabric in Q1 2024. It was introduced
Jul
Unlock the Power of Colour: Make Your Power BI Reports Pop
Colour is a powerful visual tool that can enhance the appeal and readability of your
Jul
Python vs. PySpark: Navigating Data Analytics in Databricks – Part 2
Part 2: Exploring Advanced Functionalities in Databricks Welcome back to our Databricks journey! In this
May
GPT-4 with Vision vs Custom Vision in Anomaly Detection
Businesses today are generating data at an unprecedented rate. Automated processing of data is essential
May
Exploring DALL·E Capabilities
What is DALL·E? DALL·E is text-to-image generation system developed by OpenAI using deep learning methodologies.
May
Using Copilot Studio to Develop a HR Policy Bot
The next addition to Microsoft’s generative AI and large language model tools is Microsoft Copilot
Apr