
Part 2: Exploring Advanced Functionalities in Databricks
Welcome back to our Databricks journey! In this second installment (check out Part 1 here), we’re diving deeper into the tool’s arsenal, leveraging Python and PySpark to tackle Data Definition Language (DDL) commands, unravelling the mysteries of Databricks Time travel, and uncovering nifty tricks for performance optimisation.
First, let’s compare how we handle basic DDL operations with Spark SQL and Python.
DELTA LAKE DDL/DML: UPDATE, DELETE, INSERT, ALTER TABLE
One of the key features of Delta Lake is its support for Data Definition Language (DDL) and Data Manipulation Language (DML) operations, allowing for efficient management and manipulation of data within tables. Databricks allows us to execute DDL commands directly on Delta Lake tables. Here’s a rundown of common operations:
- Updates: Tweaking specific rows based on conditions, like switching ‘clk’ events to ‘click’
- Deletes: Bid farewell to rows older than a set date
- Inserts: Insert new data into tables either directly or via another table
- Alter Table: Modify the structure of a Delta Lake table, such as adding constraints.
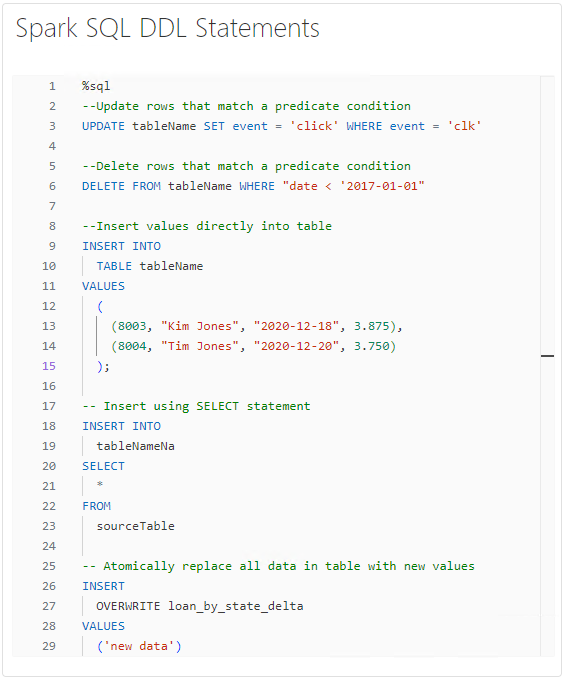
Spark SQL Updates, Inserts, Deletes:
With Spark SQL, you’re in familiar SQL territory. Spark SQL allows us to execute SQL commands directly on Delta Lake tables, providing a familiar interface for users accustomed to SQL syntax. Here are some common operations:
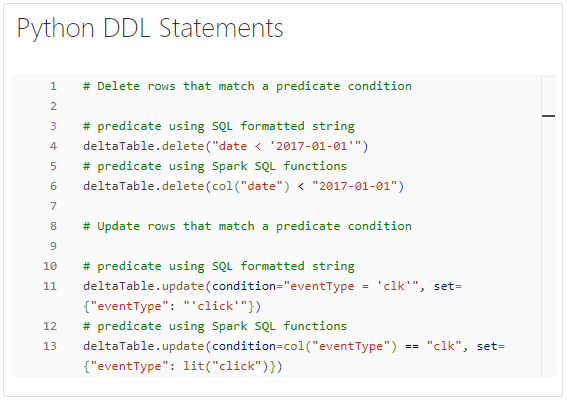
Python DELTA LAKE DDL/DML: UPDATE, DELETE, INSERT, ALTER TABLE
Python offers a flexible and programmable approach to perform Delta Lake operations. Data engineers may prefer Python for its ability to integrate with other data processing libraries and frameworks. For instance, they can incorporate Delta Lake operations within larger data pipeline scripts written in Python. Here’s an example of how we can achieve the same results using Python.
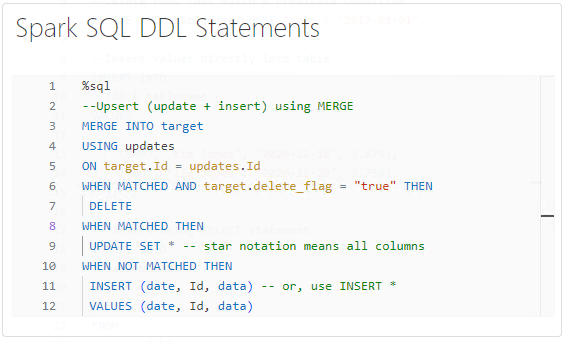
SparkSQL Upsert Operations using MERGE
Upsert operations are the magic sauce for handling updates and inserts simultaneously. That can be efficiently executed using the MERGE statement in Spark SQL. This feature simplifies the process of synchronising data between different sources and maintaining data integrity.
As an example, in a real-time analytics environment, where data is constantly flowing in, upsert operations are crucial for updating existing records and inserting new ones. The MERGE statement provides a powerful mechanism for handling such scenarios seamlessly.
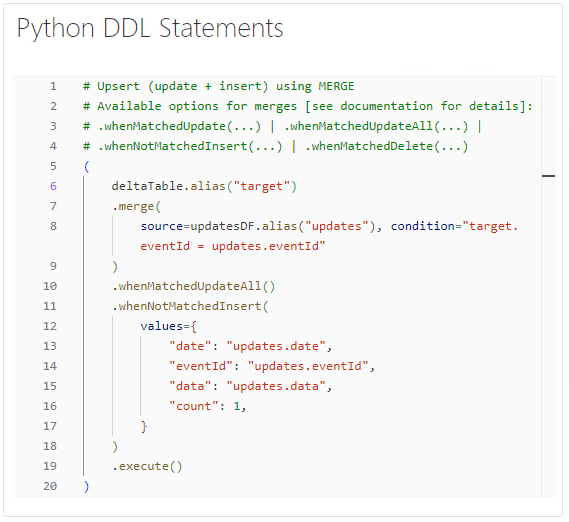
Python Upsert Operation
Depending on your preference, you can also use the Python version of the merge statement. By leveraging Python-based upsert operations, you can efficiently process these updates and seamlessly integrate them into your Delta Lake table, ensuring that it remains up-to-date with minimal overhead.
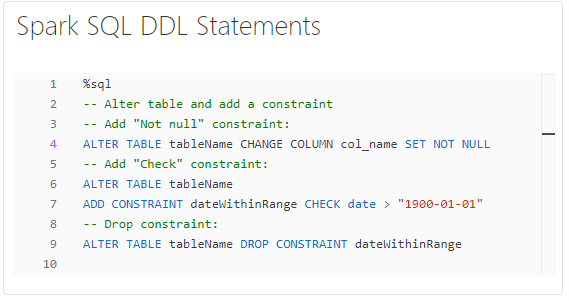
Spark SQL Alter Table Add Constraints Commands
Adding constraints to Delta Lake tables helps enforce data integrity and improve data quality by preventing the insertion of invalid or inconsistent data. Constraints such as NOT NULL and CHECK provide guardrails to ensure that only valid data is stored in the table, thereby reducing the risk of error and ensuring the reliability of downstream analytics processes.
Suppose you have a Delta Lake table that stores customer information, including their age. To ensure data consistency and accuracy, you decide to add a CHECK constraint to enforce that the age column contains only positive values. This constraint helps maintain the integrity of the data and prevents the insertion of erroneous age values into the table.
DELTA LAKE TIME TRAVEL
Delta Lake’s Time Travel feature enables users to query historical versions of tables, view transaction logs, and rollback tables to previous states. Let’s explore how Spark SQL and Python can be employed for Time Travel operations…
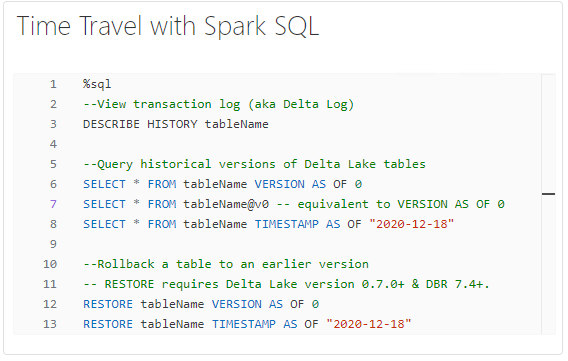
Time Travel with Spark SQL
You’re the time traveller in the Spark SQL realm, flipping through historical table versions and logs effortlessly. In other words, Spark SQL provides powerful capabilities for accessing historical versions of Delta Lake tables, viewing transaction logs, and performing table rollbacks. With Spark SQL, you can seamlessly navigate through different versions of your data, allowing you to analyse changes over time and troubleshoot issues efficiently.
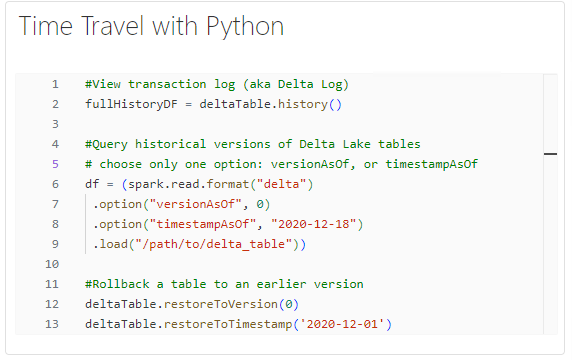
Time Travel with Python
In Python, you can retrieve the transaction log, also known as the Delta Log, using the history() method of DeltaTable objects. This method returns a DataFrame containing detailed information about each transaction performed on the Delta Lake table, including timestamps, actions, and metadata changes.
Utility Methods and Optimisations
Spark SQL and Python provide a comprehensive set of utility methods for interacting with Delta Lake tables, streamlining administrative tasks, and optimising data management processes. These methods offer flexibility and ease of use, empowering data engineers and analysts to perform various administrative tasks and optimisations seamlessly within their scripts or SQL queries. Whether you’re working with Spark SQL or Python, these utility methods enable you to gain insights into table details, facilitate data maintenance operations, and improve overall system performance. By leveraging these utility methods, you can enhance your data workflows, optimise resource utilisation, and streamline data processing tasks, ensuring efficient and reliable management of Delta Lake tables in your Databricks environment.
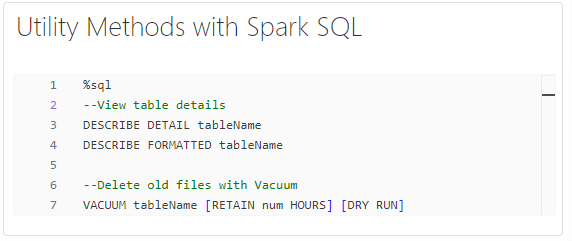
Utility Methods with Spark SQL
With Spark SQL, suppose you need to analyse the storage utilisation of your Delta Lake tables and identify any unused or obsolete data files. By utilising Spark SQL’s utility methods such as DESCRIBE DETAIL and VACUUM, you can retrieve detailed information about table storage and efficiently clean up old files, freeing up storage space and optimising resource utilisation.
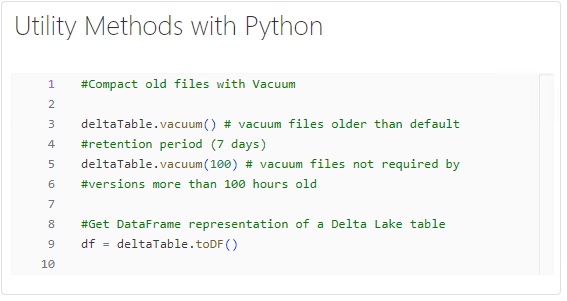
Utility Methods with Python
Using Python-based utility methods, you can invoke the vacuum() function on DeltaTable objects, compacting old files and reclaiming storage space without manual intervention.
Optimisations with Spark SQL
Optimising data processing in Databricks is vital for efficient operations. Spark SQL offers optimisation techniques to boost query speed and resource utilisation.
The OPTIMIZE command compacts files, reducing their number and optimizing layout.
Z-Ordering columns further enhance query performance by organising data for efficient retrieval. Spark SQL’s caching mechanism stores frequently queried data in Delta Cache, reducing query latency and improving overall performance by avoiding redundant computations and disk I/O. This results in faster analytics, reduced resource contention, and an enhanced user experience, empowering data analysts and business users to make confident, data-driven decisions more quickly.

Optimisations with Python
As we’ve seen previously, there’s a way to accomplish the optimisations using Python:
- File Optimisation: Python scripts compact and clean files, reducing storage overhead and improving data access efficiency
- Cache Management: Python efficiently handles cached data, optimising memory usage in Databricks clusters. It implements cache eviction policies and monitors usage to prevent memory leaks and ensure optimal cluster performance.

Conclusion
In exploring the functionalities of Databricks, we’ve seen how both Spark SQL and Python can be used effectively for various tasks. The choice between the two often depends on the user’s preference and the specific requirements of the task at hand. While SQL feels more comfortable for many users, Python’s flexibility can’t be ignored. Why not master both? Ultimately, mastering both languages can empower data engineers and analysts to tackle a wide range of challenges in data manipulation and management.
Introduction to Data Wrangler in Microsoft Fabric
What is Data Wrangler? A key selling point of Microsoft Fabric is the Data Science
Jul
Autogen Power BI Model in Tabular Editor
In the realm of business intelligence, Power BI has emerged as a powerful tool for
Jul
Microsoft Healthcare Accelerator for Fabric
Microsoft released the Healthcare Data Solutions in Microsoft Fabric in Q1 2024. It was introduced
Jul
Unlock the Power of Colour: Make Your Power BI Reports Pop
Colour is a powerful visual tool that can enhance the appeal and readability of your
Jul
Python vs. PySpark: Navigating Data Analytics in Databricks – Part 2
Part 2: Exploring Advanced Functionalities in Databricks Welcome back to our Databricks journey! In this
May
GPT-4 with Vision vs Custom Vision in Anomaly Detection
Businesses today are generating data at an unprecedented rate. Automated processing of data is essential
May
Exploring DALL·E Capabilities
What is DALL·E? DALL·E is text-to-image generation system developed by OpenAI using deep learning methodologies.
May
Using Copilot Studio to Develop a HR Policy Bot
The next addition to Microsoft’s generative AI and large language model tools is Microsoft Copilot
Apr