If like me, you’ve been keeping tabs on what Microsoft has been up to on the Power Platform world, you would have noticed that two concepts are regularly referenced in their architectures and generally associated with each other – Azure Data Lake Storage (ADLS) Gen 2 and Common Data Model (CDM).
As my colleague, Francesco Sbrescia, referenced in his blog, Microsoft’s ultimate goal is for the CDM to be the de facto standard data model. However, although there is a fair amount of resources talking about the capabilities and features, it can be a bit confusing to understand how you can actually store your data in the CDM format in ADLS and use it to run data analytics such as data warehousing, Power BI reporting, and Machine Learning.
As John Macintyre brilliantly summarised back in late 2018, “Azure Data Services enables advanced analytics that let you maximise the business value of data stored in CDM folders in the data lake. Data engineers and data scientists can use Azure Databricks and Azure Data Factory dataflows to cleanse and reshape data, ensuring it is accurate and complete. Data from different sources and in different formats can be normalised, reformatted, and merged to optimise the data for analytics processing. Data scientists can use Azure Machine Learning to define and train machine learning models on the data, enabling predictions and recommendations that can be incorporated into BI dashboards and reports, and used in production applications. Data engineers can use Azure Data Factory to combine data from CDM folders with data from across the enterprise to create a historically accurate, curated enterprise-wide view of data in Azure SQL Data Warehouse. At any point, data processed by any Azure Data Service can be written back to new CDM folders, to make the insights created in Azure accessible to Power BI and other CDM-enabled apps or tools.”
It’s fair to say there have been some considerable changes in the Azure landscape over recent years.
This blog will show you how to configure Synapse Link to export D365 data in the Delta Lake format – an open-source data and transaction storage file format used in Lakehouse implementations.
Before you start considering using this approach, you will need to ensure you meet the following prerequisites (Microsoft documentation).
- Dataverse: You must have the Dataverse system administrator security role. Additionally, tables you want to export via Synapse Link must have the Track Changes property enabled.
- Azure Data Lake Storage Gen2: You must have an Azure Data Lake Storage Gen2 account and Owner and Storage Blob Data Contributor role access. Your storage account must enable Hierarchical namespace and public network access for both initial setup and delta sync. Allow storage account key access is required only for the initial setup.
- Synapse workspace: You must have a Synapse workspace and Owner role in access control(IAM) and the Synapse Administrator role access within the Synapse Studio. The Synapse workspace must be in the same region as your Azure Data Lake Storage Gen2 account. The storage account must be added as a linked service within the Synapse Studio.
- A Spark Pool in the connected Azure Synapse workspace with Apache Spark Version 3.1 using this recommended Spark Pool configuration.
- The Microsoft Dynamics 365 minimum version requirement to use this feature is 9.2.22082.
Process Overview
Synapse Link facilitates the export of chosen Dataverse tables in CSV format using the specified time intervals. After landing the data in the data lake, the entities are converted to a Delta Lake format using a Synapse Analytics Spark job. Once the operation is complete, the CSV files are cleaned up, resulting in storage savings. Finally, a set of routine maintenance tasks are automatically scheduled to execute on a daily basis to perform compaction and vacuuming processes that merge and clean up data files. This data management process not only optimises storage utilisation but also enhances query performance significantly.
The process may seem a bit convoluted, given the many steps required to get the data in the target format, however, one positive way to look at it is that all that you have to worry about is setting the right configuration and “let Microsoft do the hard work”.
Assuming you went over the prerequisites, let’s dive into the process.
- Login to Power Apps, ensuring that you append ?athena.deltaLake=true. E.g.
https://make.powerapps.com/environments/<guid>/exporttodatalake?athena.deltaLake=true
- On the left menu, open Synapse Link. If not visible, select More and Discover All
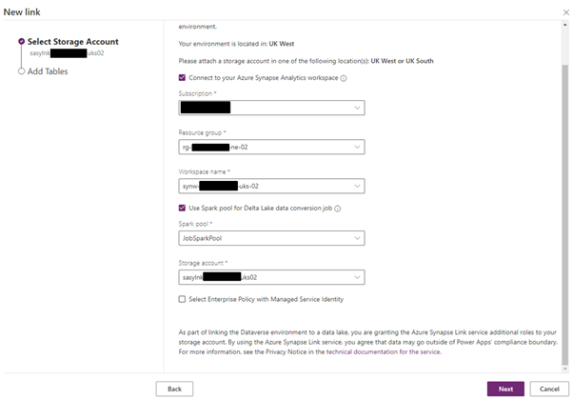
- Select New Link and enter the required information, as shown below. Ensure you tick the boxes Connect to your Azure Synapse Analytics workspace and Use Spark pool for Delta Lake data conversion job. See below:
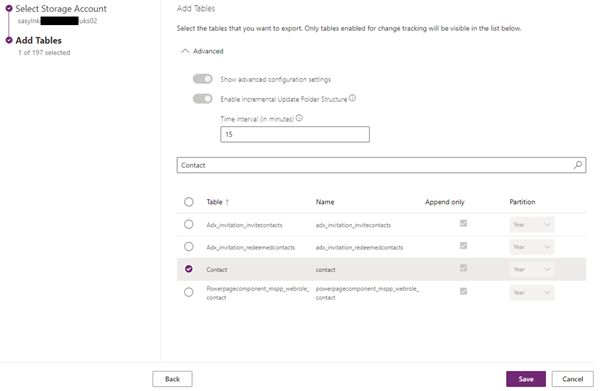
- In the next screen, select which entities you would like to add. You will notice that a few options are not available, such as Append only and Partition. This dictates how the data is written and partitioned in the lake. The hope is that eventually Microsoft will allow you to partition at a lower granularity (although this did not change since I first started writing about this topic in 2020). Before proceeding, ensure you update the Time Interval. This will define how often the incremental updates will be captured (15 min is the lowest you can go). For example, entering 15 will create incremental update folders every 15min, which will contain the changes that occurred within the time interval. Be aware of two points. 1) The data will still be exported to the data lake in near real-time; 2) Once the link is created, this value can’t be updated, unless you re-create the link. See below:
Once the setup is completed, the entities will be synced to the data lake. Synapse link will create a new container with the Dynamics environment GUID and a set of folders. The timestamp folder will contain the csv files with the exported data. After the synapse spark job completes, the files are deleted and a new folder named delta lake containing the new data in the delta lake format is created. The timestamp folders are only created if new data is added to the entities in dynamics.
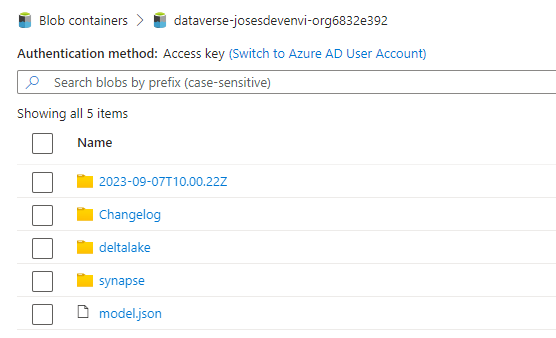
Above: Root folder structure after the data has been converted to delta lake
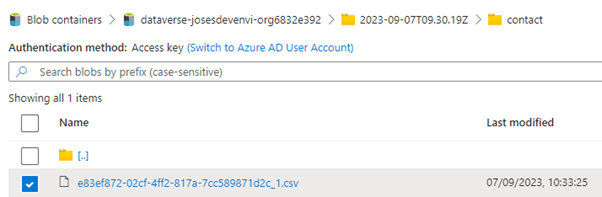
Above: Contact entity exported as csv. The file is deleted after the conversion process is completed.
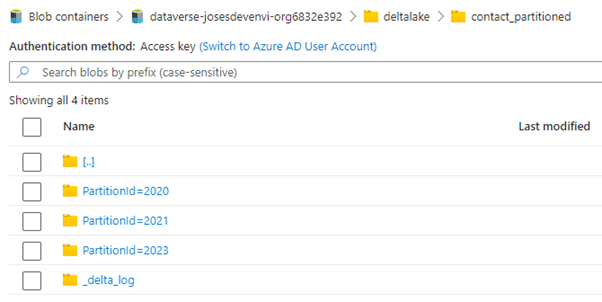
Above: The delta lake files are partitioned by year.
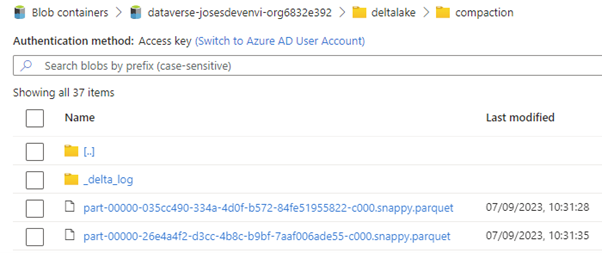
Above: Parquet files are stored in the compaction folder once the data management spark job executes.
If we check the synapse workspace, we can see the list of spark jobs. You do not control when a spark job is triggered and can’t run ad-hoc jobs to convert the data outside the expected timeframes.

Once a day, the data management process is executed.

Data Exploration
To start exploring the data, we can use the newly created Lake Database and use Serverless SQL Pools or Spark Pools.
Besides the entity tables, a series of system tables are also available. Looking at the image below, you will notice that for each entity, there is a partitioned equivalent table, however, only the main table can be queried using SQL. Opposite to the main table, which is updated in near real-time, the partitioned table is updated less frequently. Having 2 tables per entity ensures there are no file locks during the read/write operations.
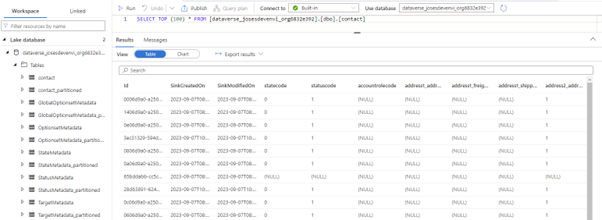
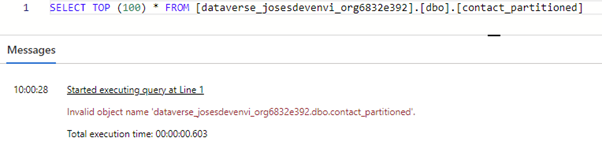
If you try to query the partitioned table, you get an error message.
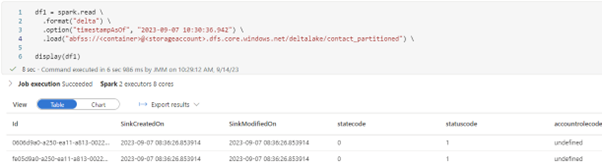
If you try to time-travel over a table, you will have to use the Spark pool, since the Serverless SQL Pool will only provide the latest version of the data.
Final thoughts
Having the data in the delta lake format is a long waited feature, however, it comes with the extra cost of having the spark cluster converting the csv files to delta lake format. If before ingesting the data to a warehouse you were using Data Factory Mapping Data Flows to copy the data from the CDM format to parquet, then this could be more cost effective. If you were consuming directly from the CDM folders, than it’s obviously an added cost. In the end, you should assess your needs and see which scenario is better suited.
If you enjoyed this blog, you can check out my other blogs in the series:
- Export to data lake (Common Data Service) – Legacy
- Power BI Dataflows
- Azure Data Services – Databricks
- Azure Data Services – Data Factory Data Flows
- Dataverse Integration with Microsoft Fabric








Thanks for the detailed steps and the information, Can you please also share how to identify the change from Delta Lake/ Parquet files ? Since it will keep changing, what if we wanted to keep monitor the changes for the data warehouse.