
If like me, you’ve been keeping tabs on what Microsoft has been up to on the Power Platform world, you would have noticed that there are two concepts that are regularly referenced in their architectures and generally associated to each other – Azure Data Lake Storage (ADLS) Gen 2 and Common Data Model (CDM).
As my colleague, Francesco Sbrescia, referenced in his blog, Microsoft’s ultimate goal is for the CDM to be the de facto standard data model. However, although there is a fair amount of resources talking about the capabilities and features, it can be a bit confusing to understand how you can actually store your data in the CDM format in ADLS and use it to run data analytics such as data warehousing, Power BI reporting and Machine Learning.
In this blog series I’ll cover 6 different ways to instantiate a CDM model in ADLS:
- Export to data lake (Common Data Service) – Legacy
- Power BI Dataflows
- Azure Data Services – Databricks
- Azure Data Services – Data Factory Data Flows
- Synapse Link for Dataverse – Delta Lake Export
- Dataverse integration with Microsoft Fabric
As John Macintyre brilliantly summarised back in late 2018, “Azure Data Services enable advanced analytics that let you maximize the business value of data stored in CDM folders in the data lake. Data engineers and data scientists can use Azure Databricks and Azure Data Factory dataflows to cleanse and reshape data, ensuring it is accurate and complete. Data from different sources and in different formats can be normalized, reformatted, and merged to optimize the data for analytics processing. Data scientists can use Azure Machine Learning to define and train machine learning models on the data, enabling predictions and recommendations that can be incorporated into BI dashboards and reports, and used in production applications. Data engineers can use Azure Data Factory to combine data from CDM folders with data from across the enterprise to create an historically accurate, curated enterprise-wide view of data in Azure SQL Data Warehouse. At any point, data processed by any Azure Data Service can be written back to new CDM folders, to make the insights created in Azure accessible to Power BI and other CDM-enabled apps or tools.”
Since I last wrote about the CDM library for Azure Databricks, a couple of things have changed and because of that, I decided to update the content of the blog. You can find the original post here.
This blog will demonstrate how to create, consume and expand CDM entities in Azure Databricks using the most recent CDM-Spark-Connector.
After some disappointing results obtained while using the previous CDM connector for Azure Databricks, I was pleased to find the release of a new connector that actually delivers what promises. Although in it’s early days and not suitable for production environments, this new connector for use with Azure Databricks and Apache Spark for Azure Synapse, allows Spark dataframes to read and write entities in a CDM folder. Before showing how to use it, it’s important to highlight a couple of points.
This new library can read CDM entities based on the traditional model.json and the new manifest approach. The *.manifest.cdm.json file contains information about the content of the CDM folder, the entities comprising the folder, relationships and links to the underlying data files. The main difference to the model.json is the possibility to create multiple manifests stored in a single folder, providing the ability to scope data for different data consuming solutions. More details here.

On the other hand, and at the time of writing this blog, the library only supports writing new entities to ADLS using the manifest approach. This is a blocker for users that would like to explore the data in Power BI using Dataflows, since the later only supports the model.json approach. The Power BI CDM connector currently in beta, also did not work, but in this case, it even failed for the model.json entity.
The first thing to do while in Databricks is to install the library, that can be found in Maven. The version I used for this demo was v0.16 and it is not supported on clusters running Spark 3.0. My instance is using Premium tier, which means, I could enable credential passthrough for user-level data access (more details here). With this enabled, I didn’t have to specify the AppID, AppKey and Tenant ID.
First, I provide the account details of two data lakes, one storing entities from Power Apps and another from Power BI Dataflows.
# Specifying appid, appkey and tenanid is optional in spark-cdm-connector-assembly-0.16.jar with Premium Databricks Cluster and Synapse
#appid = spark.conf.set("fs.azure.account.key.cdmdemosaukw.dfs.core.windows.net", dbutils.secrets.get(scope = "key-vault-secrets", key = "AppID"))
#appkey = spark.conf.set("fs.azure.account.key.cdmdemosaukw.dfs.core.windows.net", dbutils.secrets.get(scope = "key-vault-secrets", key = "AppKey"))
#tenantid = spark.conf.set("fs.azure.account.key.cdmdemosaukw.dfs.core.windows.net", dbutils.secrets.get(scope = "key-vault-secrets", key = "TenantID"))
storageAccountName = "pbidataflowsdemo.dfs.core.windows.net"
container = "powerbi"
cdsStorageAccountName = "cdmdemosaukw.dfs.core.windows.net"
cdsContainer = "commondataservice-josesdevenvi-org6832e392"
Next, I create a new dataframe that will represent a new CDM entity.
# Implicit write case
from pyspark.sql.types import *
from pyspark.sql import functions, Row
from decimal import Decimal
from datetime import datetime
# Write a CDM entity with Parquet data files, entity definition is derived from the dataframe schema
data = [
[1, "Alex", "Lai", "alex.lai@adatis.co.uk", "Consultant", "Delivery", datetime.strptime("2018-07-03", '%Y-%m-%d'), datetime.now()],
[2, "James", "Russel", "james.russel@adatis.co.uk", "Senior Consultant", "Delivery", datetime.strptime("2014-05-14", '%Y-%m-%d'), datetime.now()]
]
schema = (StructType()
.add(StructField("EmployeeId", StringType(), True))
.add(StructField("FirstName", StringType(), True))
.add(StructField("LastName", StringType(), True))
.add(StructField("EmailAddress", StringType(), True))
.add(StructField("Position", StringType(), True))
.add(StructField("Department", StringType(), True))
.add(StructField("HiringDate", DateType(), True))
.add(StructField("CreatedDateTime", TimestampType(), True))
)
df = spark.createDataFrame(spark.sparkContext.parallelize(data), schema)
display(df)
When writing to ADLS, I can either save the entity data in parquet or csv and specify whether I want to append or write. Append will only work while the dataframe and CDM schema match. If the schema differs, an overwrite is required.
# Creates the CDM manifest and adds the entity to it with parquet partitions
# with both physical and logical entity definitions
(df.write.format("com.microsoft.cdm")
.option("storage", storageAccountName)
.option("manifestPath", container + "/implicitEntity/HR/default.manifest.cdm.json")
.option("entity", "Employee")
.option("format", "parquet")
.mode("overwrite")
.save()
)
With the new entity written in CDM using the manifest files, I can now demonstrate how to combine 3 different entities, produced by 3 different data producers, Power Apps, Power BI Dataflows and Azure Databricks. Note that the only difference between reading a manifest or model.json is the path to the objects. Although the 3 json files have 3 different structures, the library does not present any issues during the reading process.
#Read HR Employee CDM Entity
employeeDf = (spark.read.format("com.microsoft.cdm")
.option("storage", storageAccountName)
.option("manifestPath", container + "/implicitEntity/HR/default.manifest.cdm.json")
.option("entity", "Employee")
.load())
display(employeeDf)
#Read Power Apps Contact Entity
contactDf = (spark.read.format("com.microsoft.cdm")
.option("storage", cdsStorageAccountName)
.option("manifestPath", cdsContainer + "/model.json")
.option("entity", "contact")
.load())
display(contactDf)
#Read PBI Dataflows Customer CDM Entity
customerDf = (spark.read.format("com.microsoft.cdm")
.option("storage", storageAccountName)
.option("manifestPath", container + "/CDMDemo/DataflowsCustomer/model.json")
.option("entity", "Customer")
.load())
display(customerDf)
In this cell I’m creating a function to union two dataframes with different structures. If a column does not exist in one of the dataframes, it will be added to the new dataframe.
from pyspark.sql.functions import lit
def __order_df_and_add_missing_cols(df, columns_order_list, df_missing_fields):
""" return ordered dataFrame by the columns order list with null in missing columns """
if not df_missing_fields: # no missing fields for the df
return df.select(columns_order_list)
else:
columns = []
for colName in columns_order_list:
if colName not in df_missing_fields:
columns.append(colName)
else:
columns.append(lit(None).alias(colName))
return df.select(columns)
def __add_missing_columns(df, missing_column_names):
""" Add missing columns as null in the end of the columns list """
list_missing_columns = []
for col in missing_column_names:
list_missing_columns.append(lit(None).alias(col))
return df.select(df.schema.names + list_missing_columns)
def __order_and_union_d_fs(left_df, right_df, left_list_miss_cols, right_list_miss_cols):
""" return union of data frames with ordered columns by left_df. """
left_df_all_cols = __add_missing_columns(left_df, left_list_miss_cols)
right_df_all_cols = __order_df_and_add_missing_cols(right_df, left_df_all_cols.schema.names,
right_list_miss_cols)
return left_df_all_cols.union(right_df_all_cols)
def union_d_fs(left_df, right_df):
""" Union between two dataFrames, if there is a gap of column fields,
it will append all missing columns as nulls """
# Check for None input
if left_df is None:
raise ValueError('left_df parameter should not be None')
if right_df is None:
raise ValueError('right_df parameter should not be None')
# For data frames with equal columns and order- regular union
if left_df.schema.names == right_df.schema.names:
return left_df.union(right_df)
else: # Different columns
# Save dataFrame columns name list as set
left_df_col_list = set(left_df.schema.names)
right_df_col_list = set(right_df.schema.names)
# Diff columns between left_df and right_df
right_list_miss_cols = list(left_df_col_list - right_df_col_list)
left_list_miss_cols = list(right_df_col_list - left_df_col_list)
return __order_and_union_d_fs(left_df, right_df, left_list_miss_cols, right_list_miss_cols)
In this cell I’m combining the data from the PBI Dataflows entity with the Power Apps entity and only selecting the structure provided by the first.
#Union Contact and Customer Dataframes
contactCustomerDf = (union_d_fs(customerDf, contactDf)
.select(customerDf.contactId
,customerDf.NameStyle
,customerDf.Title
,customerDf.firstName
,customerDf.middleName
,customerDf.lastName
,customerDf.suffix
,customerDf.CompanyName
,customerDf.SalesPerson
,customerDf.EMailAddress1
,customerDf.mobilePhone
,customerDf.passwordHash
,customerDf.PasswordSalt
,customerDf.rowguid
,customerDf.modifiedOn
,customerDf.customerSizeCode
,customerDf.customerSizeCode_display
,customerDf.customerTypeCode
,customerDf.customerTypeCode_display
,customerDf.preferredContactMethodCode
,customerDf.preferredContactMethodCode_display
,customerDf.leadSourceCode
,customerDf.leadSourceCode_display
,customerDf.owningBusinessUnit
,customerDf.owningUser
,customerDf.paymentTermsCode
,customerDf.paymentTermsCode_display
,customerDf.shippingMethodCode
,customerDf.shippingMethodCode_display
,customerDf.accountId
,customerDf.participatesInWorkflow
,customerDf.isBackofficeCustomer
,customerDf.salutation
,customerDf.jobTitle
,customerDf.department
,customerDf.nickName
,customerDf.yomiFirstName
,customerDf.fullName
,customerDf.yomiMiddleName
,customerDf.yomiLastName
,customerDf.anniversary
,customerDf.birthDate
,customerDf.governmentId
,customerDf.yomiFullName
,customerDf.description
,customerDf.employeeId
,customerDf.genderCode
,customerDf.genderCode_display
,customerDf.annualIncome
,customerDf.hasChildrenCode
,customerDf.hasChildrenCode_display
,customerDf.educationCode
,customerDf.educationCode_display
,customerDf.webSiteUrl
,customerDf.familyStatusCode
,customerDf.familyStatusCode_display
,customerDf.ftpSiteUrl
,customerDf.spousesName
,customerDf.assistantName
,customerDf.EMailAddress2
,customerDf.assistantPhone
,customerDf.EMailAddress3
,customerDf.doNotPhone
,customerDf.managerName
,customerDf.managerPhone
,customerDf.doNotFax
,customerDf.doNotEMail
,customerDf.doNotPostalMail
,customerDf.doNotBulkEMail
,customerDf.doNotBulkPostalMail
,customerDf.accountRoleCode
,customerDf.accountRoleCode_display
,customerDf.territoryCode
,customerDf.territoryCode_display
,customerDf.creditLimit
,customerDf.createdOn
,customerDf.creditOnHold
,customerDf.createdBy
,customerDf.modifiedBy
,customerDf.numberOfChildren
,customerDf.childrensNames
,customerDf.versionNumber
,customerDf.pager
,customerDf.telephone1
,customerDf.telephone2
,customerDf.telephone3
,customerDf.fax
,customerDf.aging30
,customerDf.stateCode
,customerDf.stateCode_display
,customerDf.aging60
,customerDf.statusCode
,customerDf.statusCode_display
,customerDf.aging90
,customerDf.parentContactId
,customerDf.address1AddressId
,customerDf.address1AddressTypeCode
,customerDf.address1AddressTypeCode_display
,customerDf.address1Name
,customerDf.address1PrimaryContactName
,customerDf.address1Line1
,customerDf.address1Line2
,customerDf.address1Line3
,customerDf.address1City
,customerDf.address1StateOrProvince
,customerDf.address1County
,customerDf.address1Country
,customerDf.address1PostOfficeBox
,customerDf.address1PostalCode
,customerDf.address1UTCOffset
,customerDf.address1FreightTermsCode
,customerDf.address1FreightTermsCode_display
,customerDf.address1UPSZone
,customerDf.address1Latitude
,customerDf.address1Telephone1
,customerDf.address1Longitude
,customerDf.address1ShippingMethodCode
,customerDf.address1ShippingMethodCode_display
,customerDf.address1Telephone2
,customerDf.address1Telephone3
,customerDf.address1Fax
,customerDf.address2AddressId
,customerDf.address2AddressTypeCode
,customerDf.address2AddressTypeCode_display
,customerDf.address2Name
,customerDf.address2PrimaryContactName
,customerDf.address2Line1
,customerDf.address2Line2
,customerDf.address2Line3
,customerDf.address2City
,customerDf.address2StateOrProvince
,customerDf.address2County
,customerDf.address2Country
,customerDf.address2PostOfficeBox
,customerDf.address2PostalCode
,customerDf.address2UTCOffset
,customerDf.address2FreightTermsCode
,customerDf.address2FreightTermsCode_display
,customerDf.address2UPSZone
,customerDf.address2Latitude
,customerDf.address2Telephone1
,customerDf.address2Longitude
,customerDf.address2ShippingMethodCode
,customerDf.address2ShippingMethodCode_display
,customerDf.address2Telephone2
,customerDf.address2Telephone3
,customerDf.address2Fax
,customerDf.ownerId
,customerDf.preferredSystemUserId
,customerDf.masterId
,customerDf.preferredAppointmentDayCode
,customerDf.preferredAppointmentDayCode_display
,customerDf.preferredAppointmentTimeCode
,customerDf.preferredAppointmentTimeCode_display
,customerDf.doNotSendMM
,customerDf.parentCustomerId
,customerDf.merged
,customerDf.externalUserIdentifier
,customerDf.lastUsedInCampaign
,customerDf.transactionCurrencyId
,customerDf.overriddenCreatedOn
,customerDf.exchangeRate
,customerDf.importSequenceNumber
,customerDf.timeZoneRuleVersionNumber
,customerDf.UTCConversionTimeZoneCode
,customerDf.annualIncomeBase
,customerDf.creditLimitBase
,customerDf.aging60Base
,customerDf.aging90Base
,customerDf.aging30Base
,customerDf.createdOnBehalfBy
,customerDf.modifiedOnBehalfBy
,customerDf.owningTeam
,customerDf.stageId
,customerDf.processId
,customerDf.address2Composite
,customerDf.address1Composite
,customerDf.entityImageId
,customerDf.traversedPath
,customerDf.SLAId
,customerDf.SLAInvokedId
,customerDf.onHoldTime
,customerDf.lastOnHoldTime
,customerDf.followEmail
,customerDf.timeSpentByMeOnEmailAndMeetings
,customerDf.address3Country
,customerDf.address3Line1
,customerDf.address3Line2
,customerDf.address3Line3
,customerDf.address3PostalCode
,customerDf.address3PostOfficeBox
,customerDf.address3StateOrProvince
,customerDf.address3City
,customerDf.business2
,customerDf.callback
,customerDf.company
,customerDf.home2
,customerDf.address3AddressId
,customerDf.address3Composite
,customerDf.address3Fax
,customerDf.address3FreightTermsCode
,customerDf.address3FreightTermsCode_display
,customerDf.address3Latitude
,customerDf.address3Longitude
,customerDf.address3Name
,customerDf.address3PrimaryContactName
,customerDf.address3ShippingMethodCode
,customerDf.address3ShippingMethodCode_display
,customerDf.address3Telephone1
,customerDf.address3Telephone2
,customerDf.address3Telephone3
,customerDf.address3UPSZone
,customerDf.address3UTCOffset
,customerDf.address3County
,customerDf.address3AddressTypeCode
,customerDf.address3AddressTypeCode_display
,customerDf.createdByExternalParty
,customerDf.modifiedByExternalParty
,customerDf.marketingOnly
,customerDf.defaultPriceLevelId
,customerDf.originatingLeadId
,customerDf.preferredEquipmentId
,customerDf.preferredServiceId
,customerDf.adxCreatedByIPAddress
,customerDf.adxCreatedByUsername
,customerDf.adxModifiedByIPAddress
,customerDf.adxModifiedByUsername
,customerDf.adxOrganizationName
,customerDf.adxTimeZone
,customerDf.managingPartner
,customerDf.disableWebTracking
,customerDf.isMinor
,customerDf.isMinorWithParentalConsent
,customerDf.portalTermsAgreementDate
,customerDf.preferredLanguage
,customerDf.profileAlert
,customerDf.profileAlertDate
,customerDf.profileAlertInstructions
,customerDf.adxProfileIsAnonymous
,customerDf.adxProfileLastActivity
,customerDf.profileModifiedOn
,customerDf.publicProfileCopy
,customerDf.accessFailedCount
,customerDf.emailConfirmed
,customerDf.lastSuccessfulLogin
,customerDf.localLoginDisabled
,customerDf.lockoutEnabled
,customerDf.lockoutEndDate
,customerDf.loginEnabled
,customerDf.mobilePhoneConfirmed
,customerDf.securityStamp
,customerDf.twoFactorEnabled
,customerDf.userName
,customerDf.originatingEvent
,customerDf.sourceCustomerJourney
,customerDf.sourceEmail
,customerDf.sourceForm
,customerDf.sourceLandingPage
,customerDf.rememberMe
,customerDf.insightsPlaceholder
,customerDf.portalInvitationCode
,customerDf.portalInvitationURL
,customerDf.activityStartDate
,customerDf.address1PeriodEndDate
,customerDf.address1PeriodStartDate
,customerDf.address2PeriodEndDate
,customerDf.address2PeriodStartDate
,customerDf.address3PeriodEndDate
,customerDf.address3PeriodStartDate
,customerDf.animal
,customerDf.animalBreed
,customerDf.animalGenderStatus
,customerDf.animalSpecies
,customerDf.communication1Language
,customerDf.communication1Preferred
,customerDf.communication2Language
,customerDf.communication2Preferred
,customerDf.contact1EndDate
,customerDf.contact2EndDate
,customerDf.contact1
,customerDf.contact1Relationship
,customerDf.contact1StartDate
,customerDf.contact2
,customerDf.contact2Relationship
,customerDf.contact2StartDate
,customerDf.contactType
,customerDf.contactType_display
,customerDf.deceasedDate
,customerDf.generalPractioner
,customerDf.link1
,customerDf.link1Type
,customerDf.link2
,customerDf.link2Type
,customerDf.managingOrganization
,customerDf.medicalRecordNumber
,customerDf.multipleBirth
,customerDf.name1EndDate
,customerDf.name1StartDate
,customerDf.name1Use
,customerDf.name1Use_display
,customerDf.name2
,customerDf.name2EndDate
,customerDf.name2FamilyName
,customerDf.name2GivenName
,customerDf.name2Prefix
,customerDf.name2StartDate
,customerDf.name2Suffix
,customerDf.name2Use
,customerDf.name2Use_display
,customerDf.name3
,customerDf.name3FamilyName
,customerDf.name3GivenName
,customerDf.name3NameEndDate
,customerDf.name3NameStartDate
,customerDf.name3Prefix
,customerDf.name3Suffix
,customerDf.name3Use
,customerDf.name3Use_display
,customerDf.qualification1Identifier
,customerDf.qualification1Issuer
,customerDf.qualification1PeriodEndDate
,customerDf.qualification1PeriodStartDate
,customerDf.telecom1EndDate
,customerDf.telecom1Rank
,customerDf.telecom1StartDate
,customerDf.telecom1System
,customerDf.telecom1System_display
,customerDf.telecom1Use
,customerDf.telecom1Use_display
,customerDf.telecom2EndDate
,customerDf.telecom2Rank
,customerDf.telecom2StartDate
,customerDf.telecom2System
,customerDf.telecom2System_display
,customerDf.telecom2Use
,customerDf.telecom2Use_display
,customerDf.telecom3EndDate
,customerDf.telecom3Rank
,customerDf.telecom3StartDate
,customerDf.telecom3System
,customerDf.telecom3System_display
,customerDf.telecom3Use
,customerDf.telecom3Use_display
)
)
In the next two steps, I rename some of the columns from the Employee entity and union it to the previous dataframe to finally obtain a single Contact entity.
#Re-structure Employee entity.
#Position, Department and HiringDate will be added as new columns of the new Contact entity
employeeDf = (employeeDf
.selectExpr("EmployeeId AS contactId", "FirstName AS firstName", "LastName AS lastName", "EmailAddress AS EMailAddress1",
"Position", "Department", "HiringDate", "CreatedDateTime AS CreatedOn")
)
#Union Employee Entity databricksContact = union_d_fs(contactCustomerDf, employeeDf)
#Save New Customer entity to a new CDM folder in ADLS
(databricksContact.write.format("com.microsoft.cdm")
.option("storage", storageAccountName)
.option("manifestPath", container + "/DatabricksEntity/default.manifest.cdm.json")
.option("entity", "Contact")
.option("format", "parquet")
.mode("overwrite")
.save()
)
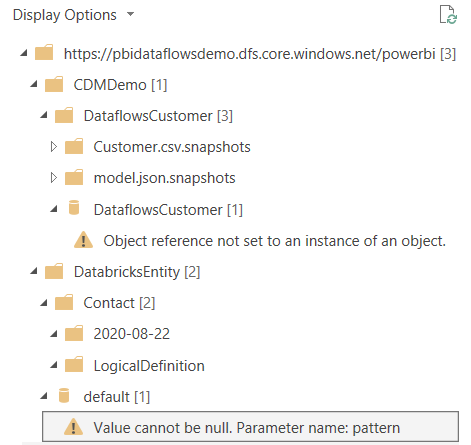
Below is the CDM structure created in the lake.








Hi @jose,
Thanks for the documentation
I am having issue while reading the cdm data with model.json
accountDf = (spark.read.format(“com.microsoft.cdm”)
4
.option(“storage”, storage)
5
.option(“manifestPath”, manifestPath)
6
.option(“entity”, “account”)
7
.option(“appId”, appId)
8
.option(“appKey”, serviceCredentialKeyName)
9
.option(“tenantId”, directoryId)
10
.load())
java.lang.StringIndexOutOfBoundsException: String index out of range: -1
—————————————————————————
Py4JJavaError Traceback (most recent call last)
in
1 manifestPath = “abfss://sse@[REDACTED].dfs.core.windows.net/raw/d365/default.manifest.cdm.json”
2 storage = “https://[REDACTED].dfs.core.windows.net”
—-> 3 accountDf = (spark.read.format(“com.microsoft.cdm”)
4 .option(“storage”, storage)
5 .option(“manifestPath”, manifestPath)
/databricks/spark/python/pyspark/sql/readwriter.py in load(self, path, format, schema, **options)
208 return self._df(self._jreader.load(self._spark._sc._jvm.PythonUtils.toSeq(path)))
209 else:
–> 210 return self._df(self._jreader.load())
211
212 def json(self, path, schema=None, primitivesAsString=None, prefersDecimal=None,
/databricks/spark/python/lib/py4j-0.10.9-src.zip/py4j/java_gateway.py in __call__(self, *args)
1302
1303 answer = self.gateway_client.send_command(command)
-> 1304 return_value = get_return_value(
1305 answer, self.gateway_client, self.target_id, self.name)
1306
/databricks/spark/python/pyspark/sql/utils.py in deco(*a, **kw)
115 def deco(*a, **kw):
116 try:
–> 117 return f(*a, **kw)
118 except py4j.protocol.Py4JJavaError as e:
119 converted = convert_exception(e.java_exception)
/databricks/spark/python/lib/py4j-0.10.9-src.zip/py4j/protocol.py in get_return_value(answer, gateway_client, target_id, name)
324 value = OUTPUT_CONVERTER[type](answer[2:], gateway_client)
325 if answer[1] == REFERENCE_TYPE:
–> 326 raise Py4JJavaError(
327 “An error occurred while calling {0}{1}{2}.\n”.
328 format(target_id, “.”, name), value)
Py4JJavaError: An error occurred while calling o3687.load.
: java.lang.StringIndexOutOfBoundsException: String index out of range: -1
at java.lang.String.substring(String.java:1967)
at shaded.databricks.azurebfs.org.apache.hadoop.fs.azurebfs.services.AbfsClient.(AbfsClient.java:90)
at shaded.databricks.azurebfs.org.apache.hadoop.fs.azurebfs.services.AbfsClient.(AbfsClient.java:120)
at shaded.databricks.azurebfs.org.apache.hadoop.fs.azurebfs.AzureBlobFileSystemStore.initializeClient(AzureBlobFileSystemStore.java:1710)
at shaded.databricks.azurebfs.org.apache.hadoop.fs.azurebfs.AzureBlobFileSystemStore.(AzureBlobFileSystemStore.java:217)
at shaded.databricks.azurebfs.org.apache.hadoop.fs.azurebfs.AzureBlobFileSystem.initialize(AzureBlobFileSystem.java:132)
at org.apache.hadoop.fs.FileSystem.createFileSystem(FileSystem.java:2669)
at org.apache.hadoop.fs.FileSystem.get(FileSystem.java:370)
at org.apache.hadoop.fs.FileSystem.get(FileSystem.java:172)
Hi Pavan,
I have been really busy with work but I will try to find some time and see if I can come back to you with an answer.
Hi Jose,
I actually am having the same issue. Maybe some diff spark configurations need to be set? As a reference, even if I try credential passthrough, I get the same exact error. However, I got the same exact code to work in synapse.
Btw, for me the issue was a wrong definition of the storageAccountName, I put the name there but it has to be the URL.