
If like me, you’ve been keeping tabs on what Microsoft has been up to on the Power Platform world, you would have noticed that there are two concepts that are regularly referenced in their architectures and generally associated to each other – Azure Data Lake Storage (ADLS) Gen 2 and Common Data Model (CDM).
As my colleague, Francesco Sbrescia, referenced in his blog, Microsoft’s ultimate goal is for the CDM to be the de facto standard data model. However, although there is a fair amount of resources talking about the capabilities and features, it can be a bit confusing to understand how you can actually store your data in the CDM format in ADLS and use it to run data analytics such as data warehousing, Power BI reporting and Machine Learning.
In this blog series I’ll cover 6 different ways to instantiate a CDM model in ADLS:
- Export to data lake (Common Data Service) – Legacy
- Power BI Dataflows
- Azure Data Services – Databricks
- Azure Data Services – Data Factory Data Flows
- Synapse Link for Dataverse – Delta Lake Export
- Dataverse integration with Microsoft Fabric
As John Macintyre brilliantly summarised back in late 2018, “Azure Data Services enable advanced analytics that let you maximize the business value of data stored in CDM folders in the data lake. Data engineers and data scientists can use Azure Databricks and Azure Data Factory dataflows to cleanse and reshape data, ensuring it is accurate and complete. Data from different sources and in different formats can be normalized, reformatted, and merged to optimize the data for analytics processing. Data scientists can use Azure Machine Learning to define and train machine learning models on the data, enabling predictions and recommendations that can be incorporated into BI dashboards and reports, and used in production applications. Data engineers can use Azure Data Factory to combine data from CDM folders with data from across the enterprise to create an historically accurate, curated enterprise-wide view of data in Azure SQL Data Warehouse. At any point, data processed by any Azure Data Service can be written back to new CDM folders, to make the insights created in Azure accessible to Power BI and other CDM-enabled apps or tools.”
In my previous blog, I demonstrated how to ingest, expand and write CDM entities to ADLS using Azure Databricks. This time, I will show how to achieve similar results with Azure Data Factory Data Flow and cover a few limitations and workarounds. Mapping data flows are visually designed data transformations in Azure Data Factory that allows data engineers to apply data transformations without writing code.
First, we create a new Data Flow transformation in Data Factory and configure the Integration Runtime. When enabling data flow debug, we can interactively see the results of each transformation step while building and debugging the data flow.
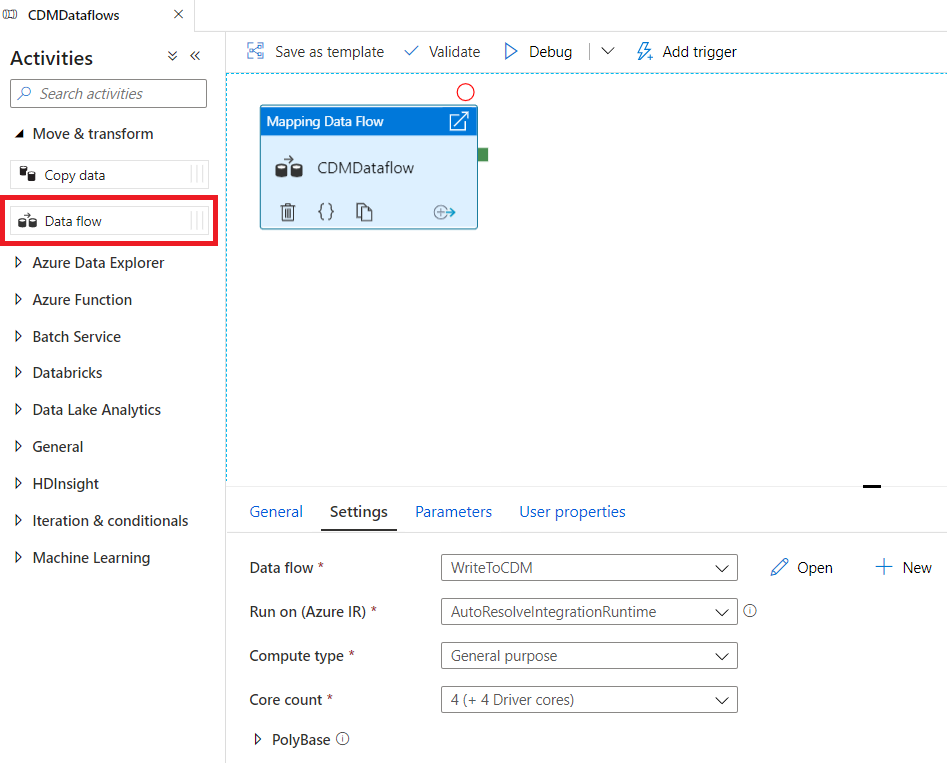
The CDM public preview connector can read CDM entity files, using manifest files and model.json, however, it can only write using manifest files. The other caveat is that the writing operation will only work if the entity definition is already available. It is not possible, at time of writing, to create new CDM entities using this method, as opposed to the CDM library available in Azure Databricks.
First, I decided to read an entity that was populated in ADLS via the Export to Data Lake service from Power Apps. When selecting a source type, we select the inline dataset Common Data Model.
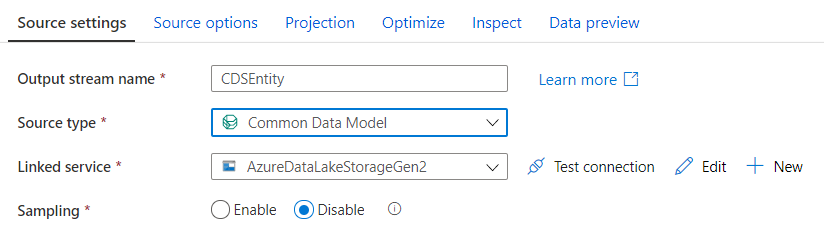
Next, we need to select Model.json as the Metadata format and populate the Root Location and Entity. When exporting from CDS, the model.json file is stored in the root folder. This caused issues to many people trying to use Data Flows to transform the data since the folder path can’t be left empty. This solution worked for me, but, I can’t guarantee it’ll work for everyone. Simply add / to the File Path, as shown below.
Because we are using an inline dataset, we have to manually import the schema to apply further mappings and transformations, as opposed to using datasets. This can easily be done by importing the projection.
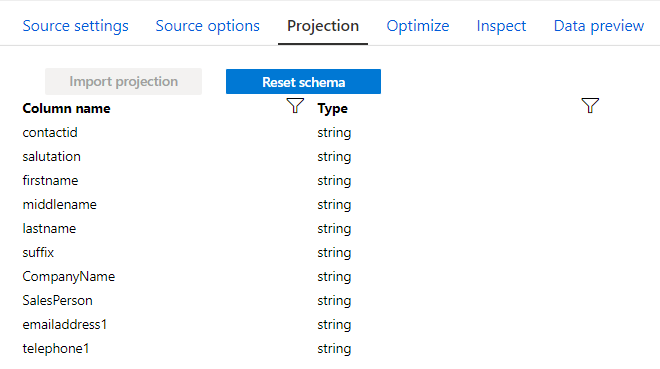
When opening Data preview, we can see all conditions were set accordingly, because we can visualise the data stored in ADLS.
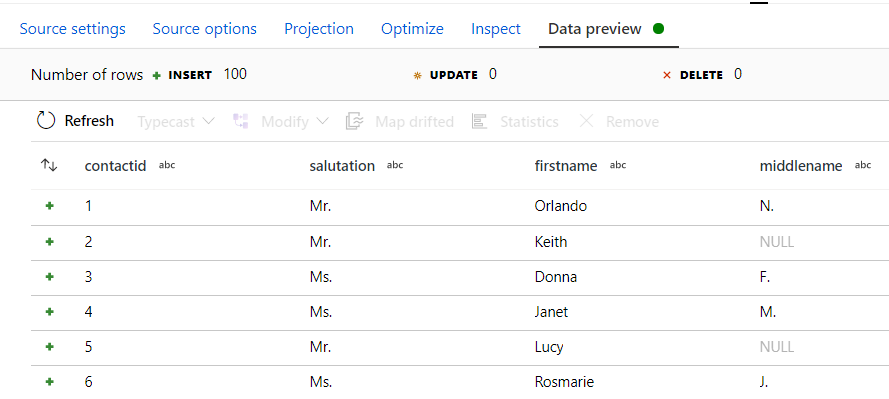
In the second test I decided to try and load a CDM entity produced by Power BI Dataflows. In terms of configuration, the only difference is that this time the model.json is not stored in the root folder and I could provide a folder path.
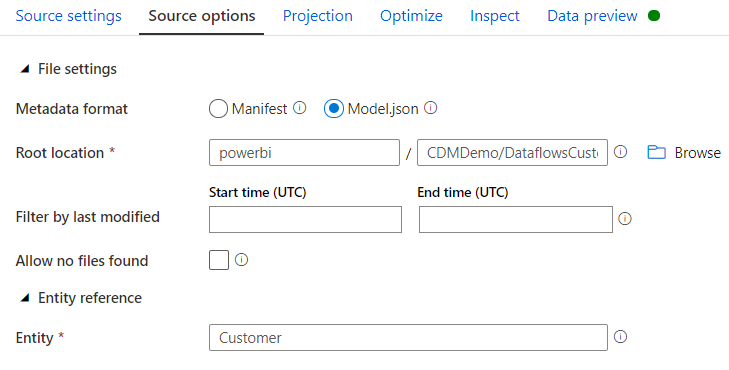
All seemed very promising until I attempted to preview the data. Although I could import the projection no data was actually being consumed. After some digging, I found that consuming entities produced by Power BI Dataflow is still not possible as they are not compatible.
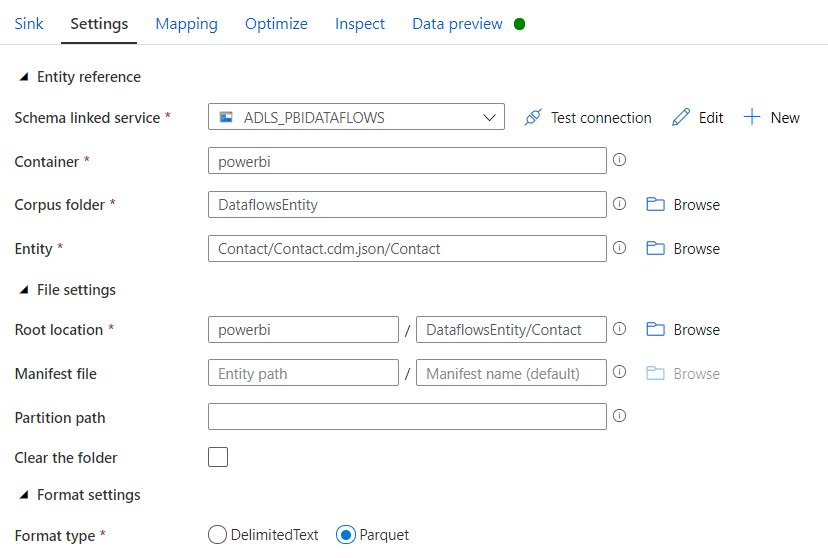
In the third test, I attempted to load a CDM entity produced by Azure Databricks. Loading entities based on the manifest file require more details, so before jumping into the configuration, let’s have a quick look at the entity structure in ADLS.
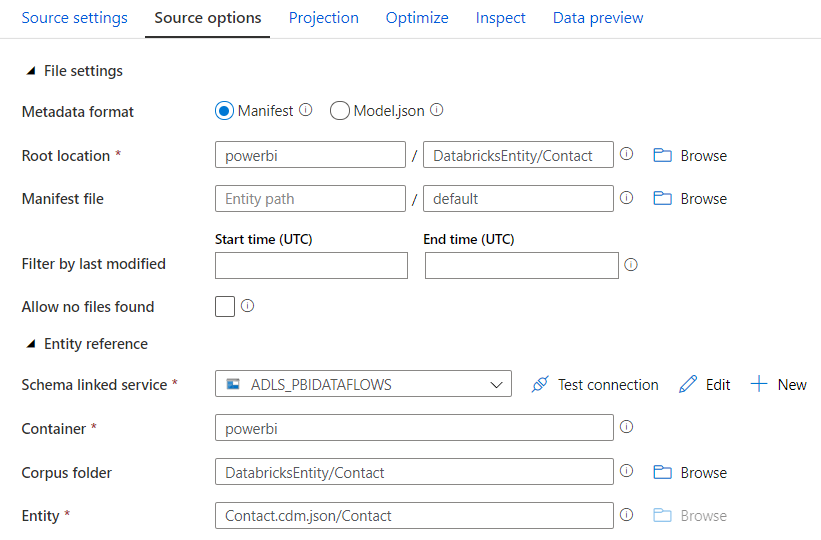
The mandatory fields are Root Location, Schema linked service, Container, Corpus Folder and Entity. Although not marked as required, if the corpus folder is not provided, you’ll get an error when trying to import projection or visualise the data. In my scenario, the manifest file was saved with the default name. If it had a different name then the details would have to be provided as well.
Similar to what happened with the previous test, I could import the projection but couldn’t preview the data. I thought it could be incompatible with the structure created by Databricks, however, that shouldn’t be a problem considering I could write to the same entity. In the next blog, I’ll populate the entity using the CDM SDK and will re-validate this scenario, but for now, it remains a mystery that might be solved once this feature goes GA.
In the final test, I tried to expand the CDS entity (the only one that was working so far) by joining Customer data extracted from Adventure Works.
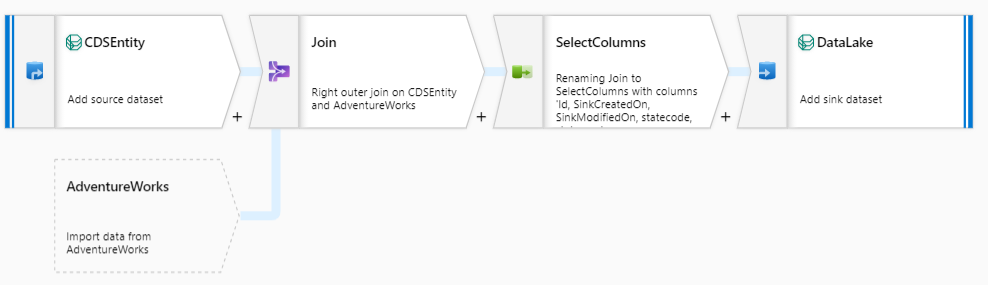
1 – Read the CDS Entity
2 – Read the Customer data from Adventure Works. In this scenario, I select the columns I needed, renamed equivalent columns according to the CDS naming convention and left with the original name the columns that I wanted to add to the CDM entity.
SELECT CAST(CustomerID AS NVARCHAR(10)) AS contactid ,Title AS salutation ,FirstName AS firstname ,MiddleName AS middlename ,LastName AS lastname ,Suffix AS suffix ,CompanyName ,SalesPerson ,EmailAddress AS emailaddress1 ,Phone AS telephone1 FROM [SalesLT].[Customer]
3 – LEFT JOIN the two sources using Contact ID. This produces 255 column (245 columns from the CDS +10 columns from Adventure Works)
4 – Aggregate the columns with the same name. This produces 247 columns (245 columns with same name + 2 new columns)
5 – Write the entity to ADLS in the parquet format. As mentioned, for this to work, we need to have the entity definition previously stored in ADLS. Although it’s impossible to write a new entity without a definition, we can still change the entity by adding/removing columns, as shown in this test.








What are the end result of above. I want to sync Azure SQL table data to data lake in CDM form. What do I need to perform. Can you please help
In this particular scenario, I extended the entity Contact with some extra columns. The structure is just like shown above.
To export from Azure SQL DB to ADLS in the CDM format using Data Flows, first you will have to create the manifest and update it to the lake. Like I mentioned, Data Flows does not have the capacity to create new entities, only update existing ones, since it requires the manifest file to exist.
To manually create a new entity you can follow this link: https://docs.microsoft.com/en-us/common-data-model/creating-schemas
If you don’t want to manually create the manifest, then you can always use Power BI Dataflows (will write using model.json and not manifest) or Databricks (not advisable for production environments)
I have configured the data lake to export data from power apps. Similar folder structure is present, manifest file is missing and i am trouble in accessing data when i manifest is selected. Can you provide the sample manifest used. Also, the sample entity.cdm.json file and the folder structure to write this data to adls or any power apps entity using cdm.
When you export the data from Power Apps using the Export to Data Lake service, you will not have a manifest file but a model.json (here). Please refer to this paragraph in the blog:
“Next, we need to select Model.json as the Metadata format and populate the Root Location and Entity. When exporting from CDS, the model.json file is stored in the root folder. This caused issues to many people trying to use Data Flows to transform the data since the folder path can’t be left empty. This solution worked for me, but, I can’t guarantee it’ll work for everyone. Simply add / to the File Path, as shown below.”. The folder structure from the Power Apps entity is shown in this (blog)
Thanks for the quick response. You have also mentioned without manifest file we cant write to adls using cdm. Can you please tell on how to create manifest file. I tried following the MS article and the nuget packages for cdm are not accessible. so unable to proceed further. TIA.
I haven’t gone through the process of creating a new manifest file yet, but considering ADF just needs an existing manifest in the lake you could try a workaround. ADF does not let you create a new file but lets you change the structure of an existing one. In this instance, you can take a copy of an existing manifest or manually create one with 1 or 2 attributes and then use that to populate your new entity. Your other alternative is to use Databricks to generate the new manifest file, but not so straightforward and cheap.
Hi,
Is it possible to use Microsoft CDM to build an on-premise SaaS application or is it limited only to Azure Echo System – Azure Data Lake Storage?
Hi,
Apologies for the delay in my answer.
You can build an application on top of the CDM, however, all the data will need to live in the ADLS Gen2. Alternatively, I believe you can take a look at the different industry accelerators and export the schema (here), however, that will only give you a head start and you won’t really be using the CDM, only the schema that comes with it (if that makes sense)
Hi Jose. Great article. Interested to know the background and detail on your second test where you say “After some digging, I found that consuming entities produced by Power BI Dataflow is still not possible as they are not compatible.”
I think there might be an issue with colons in the filename (which the PBI csvs in cdm have in the timestamp part)
Wondering if anything has changed since you wrote this?
Hi Steve,
Unfortunately since I wrote the blog I did not have the chance to perform additional tests, however, judging from this very recent blog from Microsoft, it seems the problem has been fixed. I’ll aim to find some time and update the blog accordingly.
Hi Jose, Here you have mentioned only one entity for example contact. I want to export all entities from lake to Azure SQL database. How should I do it.
At the time I wrote this article, having a generic dataflow that we could use to parameterise the entity names was not possible due to the inline dataset. I’m not entirely sure this has been addressed by Microsoft, but if not, you will have to create all the source data flows, either manually or programmatically.
Hi Jose, Can Power BI desktop CDM connector read data from CDM folder in ADLS Gen2 whose data file formats are snappy.parquet.
There is a CDM connector in Power BI, however, it has been in the beta version for quite some time. Although it’s possible, I would not advise to follow this route
Hi I have Teradata data in azure in delta format and other from Dynamic 365 data in CDM format in azure, How to combine that both data in Azure Synapse with output in single format?