
Introduction
The purpose of this blog is to explore the process of running ML predictions on SQL server using Python. We are going to train and test the data to predict information about bike sharing for a specific year. We are going to be using the provided 2011 data and predict what 2012 will result in. The 2012 data already exists inside the dataset, so we will be able to compare the predicted to the actual amount.
What we require?
To run ML predictions on SQL server, we are going to install SQL server 2019 Developer Edition and run the predictions on a local database. As well as installing and running SQL Server 2019, we need to enable the functionality of ML Services (Python and R). In order to do this, go to ‘SQL Server 2019 Installation Centre (64bit)’ by typing into Start menu and follow the instructions provided on the link on ‘ML Services (Python and R)’. Another package which is required to in order run Python in SQL Server is a module called ‘revoscalepy’, but this has been enabled by standard for SQL Server 2019, Windows and Linux.
If you haven’t yet already got SQL Server Management Studio (SSMS), let’s get SSMS installed at this time as this is the tool we are going to use to manage our SQL Server.
And lastly, we are going to use VS code as a Python IDE. In order to setup the VS Code with the necessary tools, we need the following (These extensions can be installed inside VS Code under Extensions):
Let’s start with some SQL and Python!
Like mentioned in the Introduction, we are going to be using a bike sharing (may need to sign up if you have not got an account already) dataset which was fit for the purpose of this exercise. Although there is 2 CSVs within this download, we will use the ‘day’ CSV.
First thing we are going to do is create a database which we can use for this tutorial, feel free to use the script below:
CREATE DATABASE BikeSharing;
After creating the database, we are going to import the CSV into our SQL Server, to do this, right click on the database that we just created (you may need to refresh your instance) and follow the instructions on ‘Import Flat File’ feature provided in SSMS. When the wizard gets to the Modify columns section, change it to as shown below:
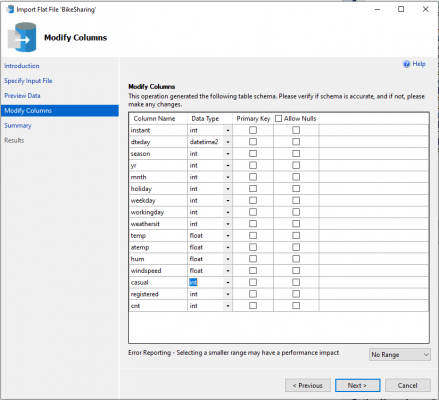
We are going to be altering this table once it has been created. We are going to be removing the dteday and yr (as it is empty) columns but before we do that, we are going to split the dteday column into year and day as month is already provided. Follow the script below to complete this part (please run in order of the steps):
/*Step 1 - first create the columns*/ ALTER TABLE [dbo].[day] ADD [year] INT NULL; ALTER TABLE [dbo].[day] ADD [day] INT NULL; /*Step 2 - secondly populate the new columns 2*/ UPDATE [dbo].[day] SET [year] = YEAR(dteday); UPDATE [dbo].[day] SET [day] =DAY(dteday); /*Step 3 - drop the unwanted columns 2*/ ALTER TABLE [dbo].[day] DROP COLUMN dteday; ALTER TABLE [dbo].[day] DROP COLUMN yr; /*Step 4 - View the result.*/ SELECT * FROM [dbo].[day];
After completing the database and table creation, we are going to go to our VS Code and run the following script to import the data from SQL Server to Python (Make sure to change server details in ‘MYSQLSERVER’ space to your server details, most likely it will be a ‘.’ if on windows as it is a local server):
import pandas as pd
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
#If you are running SQL Server 2017 RC1 and above:
from revoscalepy import RxComputeContext, RxInSqlServer, RxSqlServerData
from revoscalepy import rx_import
#Connection string to connect to SQL Server named instance
conn_str = 'Driver=SQL Server;Server=MYSQLSERVER;Database=BikeSharing;Trusted_Connection=True;'
#Define the columns we wish to import
column_info = {
"year" : { "type" : "integer" },
"mnth" : { "type" : "integer" },
"day" : { "type" : "integer" },
"cnt" : { "type" : "integer" },
"weekday" : {
"type" : "factor",
"levels" : ["0", "1", "2", "3", "4", "5", "6"]
},
"holiday" : {
"type" : "factor",
"levels" : ["0", "1"]
},
"windspeed" : {
"type" : "float",
"levels" : ["0", "1"]
},
"hum" : {
"type" : "float",
"levels" : ["0", "1"]
}
}
#Get the data from SQL Server Table
data_source = RxSqlServerData(table="dbo.day",
connection_string=conn_str, column_info=column_info)
computeContext = RxInSqlServer(
connection_string = conn_str,
num_tasks = 1,
auto_cleanup = False
)
RxInSqlServer(connection_string=conn_str, num_tasks=1, auto_cleanup=False)
# import data source and convert to pandas dataframe
df = pd.DataFrame(rx_import(input_data = data_source))
print("Data frame:", df)
# Get all the columns from the dataframe.
columns = df.columns.tolist()
# Filter the columns to remove ones we don't want to use in the training
columns = [c for c in columns if c not in ["year"]]
Some results should appear similar to the snippet below:

As you can see from the snippet above, we are just importing the data which exists inside our SQL Server table and using some python to view it in our Python IDE. Now that we have imported the data from our SQL Server, we are going to train the model, which means that we are going to provide a ML algorithm which is used to learn the subset of the dataset we are focusing on for this exercise. We are going to be creating some models using a linear regression algorithm. Add this code below, to the end of the code shown above and run together in your Python IDE:
# Store the variable we'll be predicting on.
target = "cnt"
# Generate the training set. Set random_state to be able to replicate results.
train = df.sample(frac=0.8, random_state=1)
# Select anything not in the training set and put it in the testing set.
test = df.loc[~df.index.isin(train.index)]
# Print the shapes of both sets.
print("Training set shape:", train.shape)
print("Testing set shape:", test.shape)
# Initialize the model class.
lin_model = LinearRegression()
# Fit the model to the training data.
lin_model.fit(train[columns], train[target])
We are using one of the popular Python libraries, ‘Scikit-learn’ to understand the dataset as part of the process of predicting the bike sharing count for the year 2012. There are different variables such as depend variables and independent variables used to study the data closer. We can now predict the count for BikeSharing using a Prediction function and our models. Add this code below, to the end of the code shown above and run together in your Python IDE:
# Generate our predictions for the test set.
lin_predictions = lin_model.predict(test[columns])
print("Predictions:", lin_predictions)
# Compute error between our test predictions and the actual values.
lin_mse = mean_squared_error(lin_predictions, test[target])
print("Computed error:", lin_mse)
Then we need to go to SSMS and run this script in order to store the model being produced from the algorithm.
USE BikeSharing;
DROP TABLE IF EXISTS sharing_py_models;
GO
CREATE TABLE sharing_py_models (
model_name VARCHAR(30) NOT NULL DEFAULT('default model') PRIMARY KEY,
model VARBINARY(MAX) NOT NULL
);
GO
We are now going to create a stored procedure with embedded python scripts to create the linear regression model inside our database. We are using some of the Python script we wrote up previously as part of the SQL stored procedure and generate the linear regression model which then can be stored in the SQL table as reference. We can see that in the variable, @input_data_1 on line 26, we have a SQL select statement which is specifying that we are only training the data which is ‘< 2012’ because we are trying to predict the count for the year 2012.
USE [BikeSharing]
GO
DROP PROCEDURE IF EXISTS [dbo].[generate_sharing_py_model];
GO
CREATE PROCEDURE [dbo].[generate_sharing_py_model] (@trained_model varbinary(max) OUTPUT)
AS
BEGIN
EXECUTE sp_execute_external_script
@language = N'Python'
, @script = N'
from sklearn.linear_model import LinearRegression
import pickle
df = sharing_train_data
# Get all the columns from the dataframe.
columns = df.columns.tolist()
# Store the variable well be predicting on.
target = "cnt"
# Initialize the model class.
lin_model = LinearRegression()
# Fit the model to the training data.
lin_model.fit(df[columns], df[target])
#Before saving the model to the DB table, we need to convert it to a binary object
trained_model = pickle.dumps(lin_model)'
, @input_data_1 = N'select "cnt", "year", "mnth", "day", "weekday", "holiday", "windspeed", "hum" from dbo.day where Year < 2012'
, @input_data_1_name = N'sharing_train_data'
, @params = N'@trained_model varbinary(max) OUTPUT'
, @trained_model = @trained_model OUTPUT
END;
GO
/*Save model to table*/
TRUNCATE TABLE sharing_py_models;
DECLARE @model VARBINARY(MAX);
EXEC generate_sharing_py_model @model OUTPUT;
INSERT INTO sharing_py_models (model_name, model) VALUES('linear_model', @model);
We are going to create another stored procedure to predict the count of bike sharing using our models. Now that we are closing in on the final parts of deploying our models, we are going to be using the data generated by the previous stored procedure which is stored inside the SQL table (sharing_py_models) as reference point for this query to run. In the previous stored procedure, we looked at line 26 as it was specifying all data which was ‘<2012’, but we can see this procedure that we are picking the data which ‘=2012’, this is to do a side by side comparison of how much the ‘cnt’ should have been and what the outcome actually was for bike sharing dataset.
USE [BikeSharing]
GO
DROP PROCEDURE IF EXISTS [dbo].[py_predict_sharingcnt];
GO
CREATE PROCEDURE [dbo].[py_predict_sharingcnt] (@model varchar(100))
AS
BEGIN
DECLARE @py_model varbinary(max) = (select model from sharing_py_models where model_name = @model);
EXEC sp_execute_external_script
@language = N'Python',
@script = N'
# Import the scikit-learn function to compute error.
from sklearn.metrics import mean_squared_error
import pickle
import pandas as pd
sharing_model = pickle.loads(py_model)
df = sharing_score_data
# Get all the columns from the dataframe.
columns = df.columns.tolist()
# variable we will be predicting on.
target = "cnt"
# Generate our predictions for the test set.
lin_predictions = sharing_model.predict(df[columns])
print(lin_predictions)
# Compute error between our test predictions and the actual values.
lin_mse = mean_squared_error(lin_predictions, df[target])
#print(lin_mse)
predictions_df = pd.DataFrame(lin_predictions)
OutputDataSet = pd.concat([predictions_df, df["cnt"], df["mnth"], df["day"], df["weekday"], df["windspeed"], df["hum"], df["holiday"], df["year"]], axis=1)
'
, @input_data_1 = N'select "cnt", "year", "mnth", "day", "weekday", "holiday", "windspeed", "hum" from day where year = 2012'
, @input_data_1_name = N'sharing_score_data'
, @params = N'@py_model varbinary(max)'
, @py_model = @py_model
with result sets (("cnt_Predicted" float, "cnt" float, "mnth" float,"day" float,"weekday" float,"windspeed" float,"hum" float,"holiday" float,"year" float));
END;
We are going to create a table to store the predicted data which will be generated using the model created earlier. Note that the same datatypes are used for the columns for the new table.
USE [BikeSharing] GO DROP TABLE IF EXISTS [dbo].[py_sharing_predictions]; GO CREATE TABLE [dbo].[py_sharing_predictions]( [cnt_Predicted] int NULL, [cnt_Actual] int NULL, [mnth] int NULL, [day] int NULL, [weekday] int NULL, [windspeed] float NULL, [hum] float NULL, [holiday] int NULL, [year] int NULL ) ON [PRIMARY] GO
Finally!
Running the below script will read the model which is stored in the SQL and predict the results for the year 2012. There is a select statement at the end which means that you can see the result when running the below script.
TRUNCATE TABLE [py_sharing_predictions]; --Insert the results of the predictions for test set into a table INSERT INTO [py_sharing_predictions] EXEC py_predict_sharingcnt 'linear_model'; -- Select contents of the table SELECT * FROM [py_sharing_predictions];
Introduction to Data Wrangler in Microsoft Fabric
What is Data Wrangler? A key selling point of Microsoft Fabric is the Data Science
Jul
Autogen Power BI Model in Tabular Editor
In the realm of business intelligence, Power BI has emerged as a powerful tool for
Jul
Microsoft Healthcare Accelerator for Fabric
Microsoft released the Healthcare Data Solutions in Microsoft Fabric in Q1 2024. It was introduced
Jul
Unlock the Power of Colour: Make Your Power BI Reports Pop
Colour is a powerful visual tool that can enhance the appeal and readability of your
Jul
Python vs. PySpark: Navigating Data Analytics in Databricks – Part 2
Part 2: Exploring Advanced Functionalities in Databricks Welcome back to our Databricks journey! In this
May
GPT-4 with Vision vs Custom Vision in Anomaly Detection
Businesses today are generating data at an unprecedented rate. Automated processing of data is essential
May
Exploring DALL·E Capabilities
What is DALL·E? DALL·E is text-to-image generation system developed by OpenAI using deep learning methodologies.
May
Using Copilot Studio to Develop a HR Policy Bot
The next addition to Microsoft’s generative AI and large language model tools is Microsoft Copilot
Apr