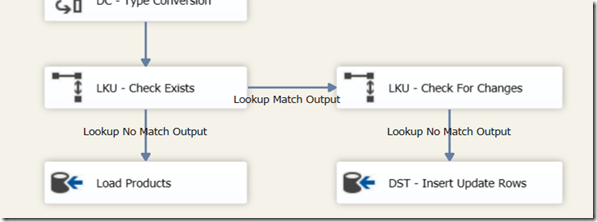
In this blog we look at how to optimise SSIS lookups with HASHBYTES. I was recently working on a load for a Dimension table which worked like the below.

The package follows a fairly standard routine. Data for the Dimension is transformed into the required format using SSIS, following this it is inserted into the target table. On the way an initial check is made to determine if the record is new ‘LKU – Check Exists’ and a secondary check to determine if the record has changed, which is subsequently used in an update routine.
Although the package was incrementally loading, it was having to sometimes check several million rows to determine if these had changed, as the table was quite wide I decided to implement the HASHBYTES() function in order to take a hash of the columns for comparison rather than compare each of the columns.
The initial results were quite promising with the package running in around half the time, however on a particularly big load I noticed the package failed as it had run out of memory for the second Lookup (full cache was used). I found this odd because the HASHBYTES function only returned a single value and I anticipated this would be smaller than the sum of the columns, however on a little deeper investigation I found that by default any row returned using the HASHBYTES function are all of a default size 8000 bytes.

A quick check of the SQL Documentation of the HASHBYTES function at http://msdn.microsoft.com/en-GB/library/ms174415.aspx states that the size of the data returned for the HASHBYTES function when used with the SHA2-256 algorithm is 32 bytes meaning that most of this space was being wasted.
Therefore changing the formula from 1 to 2 below significantly increases the efficiency of the lookup and also make the cache size required smaller by a factor of around 250!
1. HASHBYTES(‘SHA2_256’,[ProductName] + ‘|‘ + [CategoryName]) AS HashValue
2. CONVERT(VARBINARY(32),HASHBYTES(‘SHA2_256’,[ProductName] + ‘|‘ + [CategoryName])) AS NewHash
Upon doing this the size of each row was significantly reduced, the package is running faster than before and most importantly there are no memory issues 🙂

Introduction to Data Wrangler in Microsoft Fabric
What is Data Wrangler? A key selling point of Microsoft Fabric is the Data Science
Jul
Autogen Power BI Model in Tabular Editor
In the realm of business intelligence, Power BI has emerged as a powerful tool for
Jul
Microsoft Healthcare Accelerator for Fabric
Microsoft released the Healthcare Data Solutions in Microsoft Fabric in Q1 2024. It was introduced
Jul
Unlock the Power of Colour: Make Your Power BI Reports Pop
Colour is a powerful visual tool that can enhance the appeal and readability of your
Jul
Python vs. PySpark: Navigating Data Analytics in Databricks – Part 2
Part 2: Exploring Advanced Functionalities in Databricks Welcome back to our Databricks journey! In this
May
GPT-4 with Vision vs Custom Vision in Anomaly Detection
Businesses today are generating data at an unprecedented rate. Automated processing of data is essential
May
Exploring DALL·E Capabilities
What is DALL·E? DALL·E is text-to-image generation system developed by OpenAI using deep learning methodologies.
May
Using Copilot Studio to Develop a HR Policy Bot
The next addition to Microsoft’s generative AI and large language model tools is Microsoft Copilot
Apr