After doing my recent blog post on the Excel Fuzzy Lookup Add-In Vs SSIS, it got me thinking about the capabilities of the SSIS Fuzzy Lookup Transformation.
Although I’m aware that the Fuzzy Lookup is a token-based solution, I’ve only ever tuned it really by altering the similarity thresholds on both the columns and also on the task itself. What you can also do is alter how the transform deals with tokens. Therefore, I thought it would be worth a quick post to show how the tokens help produce matches.
Tokens
The Fuzzy Lookup works by splitting up strings into several different components, known as tokens. For example, the Adventure Works reseller “Cross-Country Riding Supplies” might be split up into the tokens “Cross”, “Country”, “Riding” and “Supplies”. This is key to the matching process, as the fuzzy algorithms will attempt a match based on the commonality between tokens in the input and reference datasets.
SSIS Fuzzy Lookup
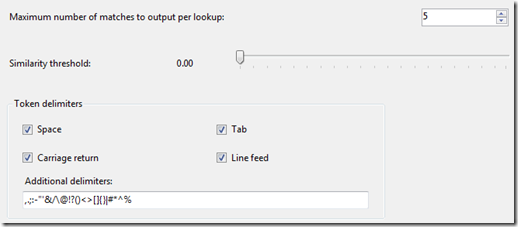
The advanced tab of the fuzzy lookup will show the delimiters used to create the tokens. As you can see, a hyphen is included in the list, meaning words separated by a hyphen get interpreted as separate tokens:

On the “Reference Table” tab of the transformation, there is the option to store a new index, which means that SQL Server will create a table in the data source to hold the tokens found in the reference table:

In my made up dbo.Retailers table, I’ve got two retailers – “Nearest Bike Store” and “Gears+Chain Supply”. After running the SSIS package once, the dbo.IndexTest table will be created, which is where the reference tokens get stored in order to help with matching. As it’s just stored in SQL Server we can select from it.Before we do that, I should just say, I’m only passing this fuzzy lookup 1 input string, which is a misspelt company called “Bikes Chaiin Supply”. If I run the package, I get the following matches and scores:

This has a fairly low similarity and confidence, so we can probably do better. Going back to the index, if we select from dbo.IndexTest, we get the following:

The index table also contains substrings found in the reference table, known as q-grams, which are designed to assist with matches that contain errors. What’s interesting about these results is that “gears+chain” has been entered on its own, meaning that the word “chain” has not been interpreted as a token in this case. The solution, in this case, is to alter the token delimiters to include “+”:

If we re-run the package and then look again at the index table, we now see that the word “chain” has been successfully interpreted as a token. In addition we also have a few variants on the word chain, such as “chai” and “hain”:

After re-running the matching process with out new delimiters, we can now look at the results of the matching process. If we take a look at the data viewer output, we can see that this has now resulted in a better similarity and confidence for the first row:

The delimiters work across all columns for the whole fuzzy lookup, so that’s something to test when changing the delimiters – it may not be beneficial in all situations. However the new delimiter has clearly worked very well in this example, so it’s very much worth considering if you’re not quite getting the level of matches that you had hoped for.
Introduction to Data Wrangler in Microsoft Fabric
What is Data Wrangler? A key selling point of Microsoft Fabric is the Data Science
Jul
Autogen Power BI Model in Tabular Editor
In the realm of business intelligence, Power BI has emerged as a powerful tool for
Jul
Microsoft Healthcare Accelerator for Fabric
Microsoft released the Healthcare Data Solutions in Microsoft Fabric in Q1 2024. It was introduced
Jul
Unlock the Power of Colour: Make Your Power BI Reports Pop
Colour is a powerful visual tool that can enhance the appeal and readability of your
Jul
Python vs. PySpark: Navigating Data Analytics in Databricks – Part 2
Part 2: Exploring Advanced Functionalities in Databricks Welcome back to our Databricks journey! In this
May
GPT-4 with Vision vs Custom Vision in Anomaly Detection
Businesses today are generating data at an unprecedented rate. Automated processing of data is essential
May
Exploring DALL·E Capabilities
What is DALL·E? DALL·E is text-to-image generation system developed by OpenAI using deep learning methodologies.
May
Using Copilot Studio to Develop a HR Policy Bot
The next addition to Microsoft’s generative AI and large language model tools is Microsoft Copilot
Apr