Introduction
We can use Synapse for many activities. We can use it not only for ingesting, querying, storing and visualising data, but for developing machine learning models as well. Of course, one can say that doing data science is another functionality of this platform and this is definitely true. However, in this article, I would like to show you that instead of using Python, one can use T-SQL for doing predictions.
Machine Learning Models developed in Azure Machine Learning Studio
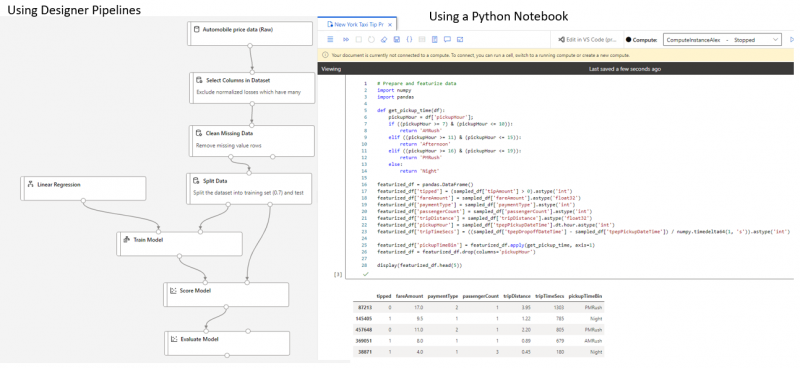
Judging by its name, Azure Machine Learning Studio is the main Azure resource to be used for developing machine learning models. More information about how to use this resource you can find in Matt’s blog – Introduction to Azure Machine Learning – Adatis. Data scientists can use either Python notebooks and/or pipelines in the Designer section. Here I am not going to go into the details of developing machine learning models. I will just show you the complete versions of the Automobile Price Prediction model and the New York Taxi Tip Prediction model. I have developed the first one using designer pipelines and the second one using a Python notebook:
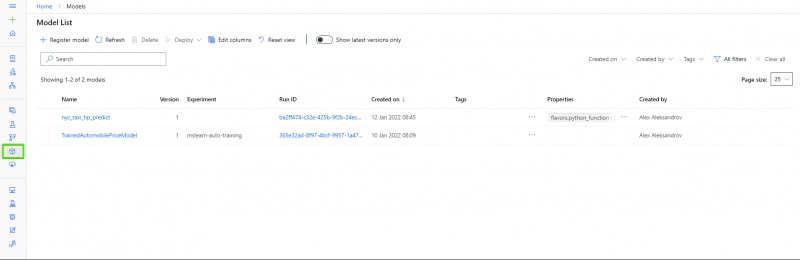
After successfully creating our models, when we click in the model section, we would be able to see them:
Predicting the output of the New York Taxi model in Synapse
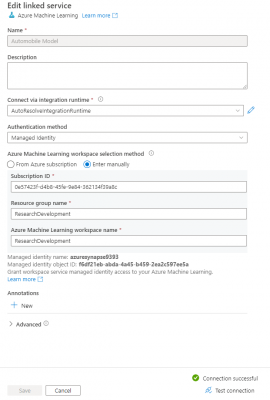
Despite being used for different purposes, T-SQL can also predict the output of a model. Indeed not only Python can do this job. Here I will briefly explain this process with regards to the New York taxi model. But before that we need to create an Azure Machine Learning linked service in Synapse and make sure that the connection is successful:
We need to add the import of the “onnx” and “skl2onnx” libraries in this notebook in Azure Machine Learning Studio. After we execute it, we will have our New York taxi test data exported into a CSV file. We can see it below our Python Notebook. Then we can download the test data and upload it into our data lake storage in Synapse. Afterwards, we will create a table. Then we will load our test data into our dedicated SQL pool. We can use the following script for this purpose:
IF NOT EXISTS (SELECT * FROM sys.objects WHERE NAME = 'nyc_taxi' AND TYPE = 'U')
CREATE TABLE dbo.nyc_taxi
(
tipped int,
fareAmount float,
paymentType int,
passengerCount int,
tripDistance float,
tripTimeSecs bigint,
pickupTimeBin nvarchar(30)
)
WITH
(
DISTRIBUTION = ROUND_ROBIN,
CLUSTERED COLUMNSTORE INDEX
)
GO
COPY INTO dbo.nyc_taxi
(tipped 1, fareAmount 2, paymentType 3, passengerCount 4, tripDistance 5, tripTimeSecs 6, pickupTimeBin 7)
FROM '<URL to linked storage account>/test_data.csv'
WITH
(
FILE_TYPE = 'CSV',
ROWTERMINATOR='0x0A',
FIELDQUOTE = '"',
FIELDTERMINATOR = ',',
FIRSTROW = 2
)
GO
SELECT TOP 100 * FROM nyc_taxi
GO
Now we are ready to resume our SQL pool. Let’s navigate to our newly created dbo.nyc_taxi table. When we click on the Actions dots next to it, we will notice that now we will have the option to do a machine learning on it. Click on “Predict with a model”:
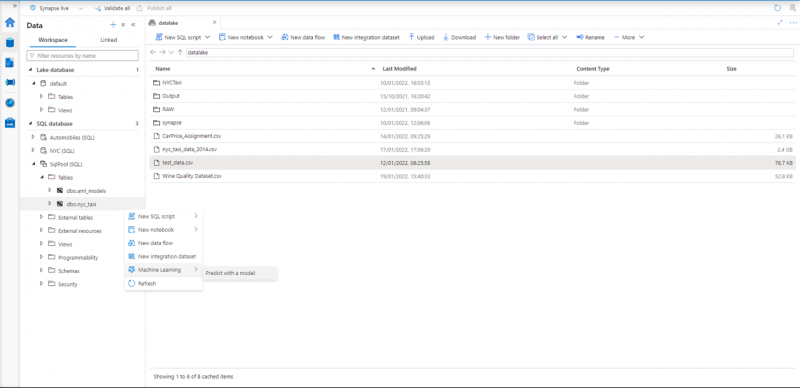
Then a window will appear, in which we need to select the model from the Azure Machine Learning workspace. Then we will see the mappings of our columns. In our last window, we need to choose whether we want to have an automatically generated stored procedure or a view. We also need to choose whether we want to load the model into an existing or a new table. At the end, we simply click “Deploy model + open script” and the automated script is being generated for us. The sequence of steps that we need to execute is the following:
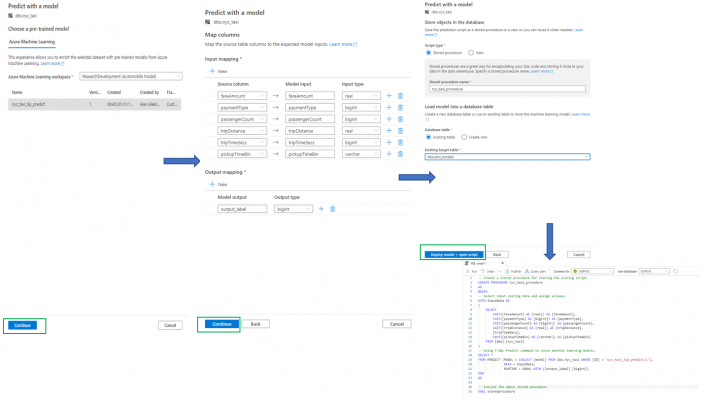
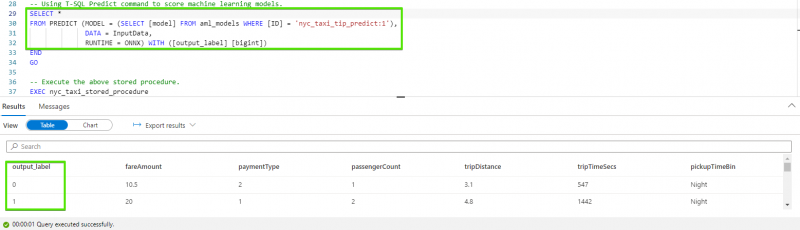
After we run the stored procedure, our output_label column will be displayed into our predictive model. It will be binary and will show whether the driver will receive a tip (with 1), or not (with 0). Indeed, it is possible to use the T-SQL Predict command to score machine learning models:
What drives the value of doing machine learning in Synapse?
The value of doing machine learning models in Synapse is the following:
- When we have a data warehouse in Synapse Analytics and a machine learning model in Azure Machine Learning Studio, we can connect to that model and our data warehouse will be constantly updating, so we do not need to have a separate pipeline that pumps this data in order to be updated in the model.
- We are doing the scoring where the data lives.
- More scalability in Synapse because unlike Azure Machine Learning Studio, we do not have any quotas or restrictions and we can always increase the data warehouse units of our SQL pool.
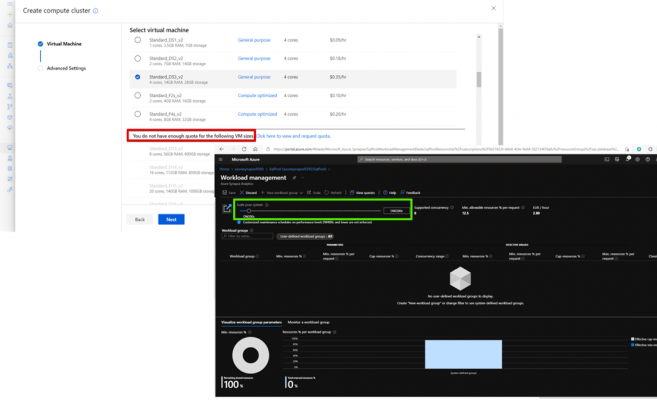
In Synapse we also have more flexibility in choosing the type of pool (Serverless or Dedicated) that we want. In Azure Machine Learning, we cannot perform any data-related activity without the creation of a cluster.
Conclusion
All in all, Azure Machine Learning Studio provides a more intuitive platform for developing machine learning models. This is indisputably true, as the name suggests. However, Azure Synapse Analytics gives us the ability to feed data to these models much faster and scale the data warehouse units when needed. This gives us higher performance and speed when we are predicting the output of these models.
Introduction to Data Wrangler in Microsoft Fabric
What is Data Wrangler? A key selling point of Microsoft Fabric is the Data Science
Jul
Autogen Power BI Model in Tabular Editor
In the realm of business intelligence, Power BI has emerged as a powerful tool for
Jul
Microsoft Healthcare Accelerator for Fabric
Microsoft released the Healthcare Data Solutions in Microsoft Fabric in Q1 2024. It was introduced
Jul
Unlock the Power of Colour: Make Your Power BI Reports Pop
Colour is a powerful visual tool that can enhance the appeal and readability of your
Jul
Python vs. PySpark: Navigating Data Analytics in Databricks – Part 2
Part 2: Exploring Advanced Functionalities in Databricks Welcome back to our Databricks journey! In this
May
GPT-4 with Vision vs Custom Vision in Anomaly Detection
Businesses today are generating data at an unprecedented rate. Automated processing of data is essential
May
Exploring DALL·E Capabilities
What is DALL·E? DALL·E is text-to-image generation system developed by OpenAI using deep learning methodologies.
May
Using Copilot Studio to Develop a HR Policy Bot
The next addition to Microsoft’s generative AI and large language model tools is Microsoft Copilot
Apr