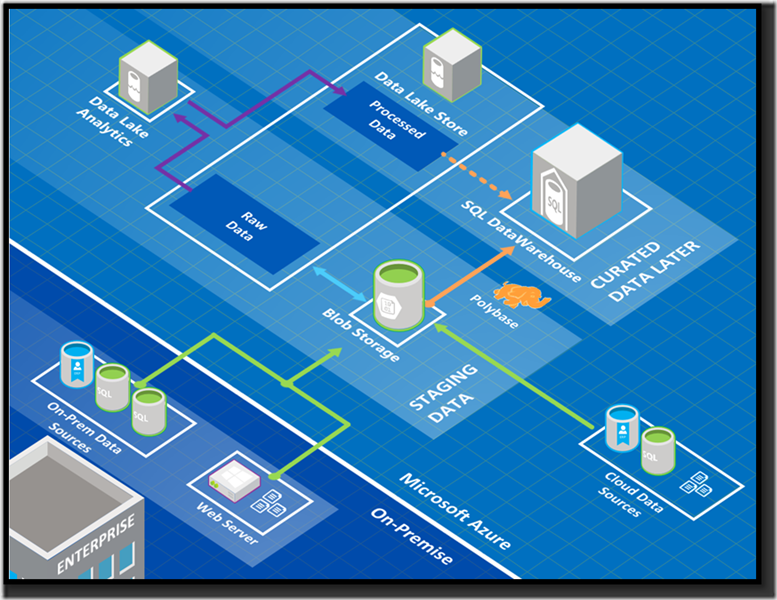
There has been a lot of turmoil in the BI space over the past couple of years, however many of us are still holding on to our favoured design patterns. The standard Kimball warehousing pattern brings data from various sources into a generic staging database. We then copy the data to another location, transforming it en-route before finally placing it into conformed, curated star schemas. There may be further transformations, tools, integrations along the way, but this is our most simplistic architecture – and it all happens on one or more SQL Server boxes.
But business challenges are driving technology changes, data volumes are exponentially rising, the different types of data businesses require in order to remain competitive is growing and the speed at which organisations generate and or/receive data is increasing. As a result there are new, cloud-driven components that facilitate entirely different ways of working, SSIS is no longer the fastest way to transform data when we’re talking about terabytes, or more, of data being moved. We also have different velocities of data, both of how it comes in and how it is analysed. Sensors sending out realtime data streams, and web logs constantly writing away – these don’t always fit nicely into a batch-job ETL. Data Scientists wanting access to raw, unprocessed data in ways that have yet to be thought of – a curated warehouse isn’t necessarily right for them.
So – to solve these issues people are looking towards Microsoft Azure’s data architecture, but there are a lot of different tools now available for a lot of different purposes. I thought I’d start our architectural analysis with a look at some key concepts and components, largely as a primer.
Scalable Processing
Above all, cloud technologies bring scalability. By hinging their charge models on actual usage, cloud providers allow users to dynamically change their resource allocations to match capacity requirements. If you’re expecting a busy period, then add more capacity. If your business hours are 9-5, turn things off in the evening and weekends to make massive cost savings.
Newer components take this even further – Azure Data Lake Analytics allows for compute units to be spun up to run a single job, closing them down afterwards. You can spin up 1000 compute units for the lifetime of a single query, all with only a few minute’s lead time.
Distributed Architectures
Because we can dynamically scale, we can manage our infrastructure to a much finer level. However, if most of our system resides on a single box, our scaling design has to take a large, complex schedule into account. Splitting various pieces of functionality into separate components and scaling them individually provides massive amounts of flexibility in managing our stack. With BI specifically, batch-processing ETL windows are a prime candidate for this.
If we have an SSIS package that needs to be run within a certain window and requires a huge amount of resource when it is running, we don’t want this to impact the rest of our ecosystem. In this case we can have a separate server for the SSIS and leave it turned off outside of our ETL window. We then power our server on (using Azure Automation, aka – hosted powershell), run our packages, then turn the server off again. If we’re talking about hour-long daily runs, then even with some allowances for maintenance windows and support, we’re talking about no more than 40 hours of Azure VM cost per month.
Queryable Archive
One of the biggest changes is the attitude to storage with cloud technologies. It has gone from a prohibitive cost that means systems need to justify their storage and growth expectations, to a relatively cheap item which can almost be considered as an afterthought. There is a growing trend of companies storing absolutely everything their systems generate, with an assumption that they will find a use for it at later dates. The cost of storing this data, thanks to falling storage prices and improved technology, is now seen as less than the potential gain that a new seam of rich analysis could bring.
This data doesn’t necessarily make it through to our curated data models – these still need to be carefully designed, governed and documented to ensure they are accessible to less data-savvy users. But expert users, developers and data scientists can write their own queries against the more expansive data stores, pull data into Azure ML and run R algorithms to unearth new insights.
Bringing it Together
With the concepts above, we get the best of both worlds – the ability to analyse vast amounts of data and apply modern data analysis techniques, and expose these findings to end-users and dashboarding systems seamlessly.
This is what we’re building into our reference Azure architecture going forward – a combined approach that has huge potential to scale yet has the functionality to meet the needs of modern BI projects.
Azure Data Lake provides the queryable store, as well as powerful targeted compute, which serves as a feed for more established, curated data models within the Azure Data Warehouse.
![clip_image001[5]](https://adatis.co.uk/wp-content/uploads/historic/simonwhiteley_clip_image0015.png "clip_image001[5]")
Over the next few blog posts, I’ll be discussing how this new architecture works in practice, how it affects the teams and companies around it, best practice for ETL, reporting architectures and development practices, as well as the new governance challenges that will grow from these structures.
Introduction to Data Wrangler in Microsoft Fabric
What is Data Wrangler? A key selling point of Microsoft Fabric is the Data Science
Jul
Autogen Power BI Model in Tabular Editor
In the realm of business intelligence, Power BI has emerged as a powerful tool for
Jul
Microsoft Healthcare Accelerator for Fabric
Microsoft released the Healthcare Data Solutions in Microsoft Fabric in Q1 2024. It was introduced
Jul
Unlock the Power of Colour: Make Your Power BI Reports Pop
Colour is a powerful visual tool that can enhance the appeal and readability of your
Jul
Python vs. PySpark: Navigating Data Analytics in Databricks – Part 2
Part 2: Exploring Advanced Functionalities in Databricks Welcome back to our Databricks journey! In this
May
GPT-4 with Vision vs Custom Vision in Anomaly Detection
Businesses today are generating data at an unprecedented rate. Automated processing of data is essential
May
Exploring DALL·E Capabilities
What is DALL·E? DALL·E is text-to-image generation system developed by OpenAI using deep learning methodologies.
May
Using Copilot Studio to Develop a HR Policy Bot
The next addition to Microsoft’s generative AI and large language model tools is Microsoft Copilot
Apr