The Azure Data Lake has just gone into general availability and the management of Azure Data Lake Store, in particular, can seem daunting especially when dealing with big data. In this blog, I will take you through the risks and challenges of working with data lakes and big data. Then I will take you through a framework we’ve created to help best manage these risks and challenges.
If you need a refresh as to what a data lake is and how to create your first Azure Data Lake Store and your first Azure Data Lake Analytics job, please feel free to follow the links.
Risks and Challenges of Big Data and Data Lake
The challenges posed by big data are as follow:
- Volume – is the sheer amount of data becoming unmanageable?
- Variety – Structured tables? Semi-structured JSON? Completely unstructured text dumps? We can normally manage with systems that contain just one of these, but if we’re dealing with a huge mix, it gets very tricky
- Velocity – How fast is the data coming in? And how fast do we need to get it to the people who need it?
- Veracity – How do we maintain accuracy, veracity, when the data is of varying volumes, the sources and structures are different and the speed in which they arrive in the Lake are of differing velocities?
Managing all four simultaneously is where the challenges begin.
It is very easy to treat a data lake as a dumping ground for anything and everything. Microsoft’s sale pitch says exactly this – “Storage is cheap, Store everything!!”. We tend to agree – but if the data is completely malformed, inaccurate, out of date or completely unintelligible, then it’s no use at all and will confuse anyone trying to make sense of the data. This will essentially create a data swamp, which no one will want to go into. Bad data & poorly managed files erode trust in the lake as a source of information. Dumping is bad.
There is also data drowning – as the volume of the data tends towards the massive and the velocity only increases over time we are going to see more and more information available via the lake. When it gets to that point, if the lake is not well managed, then users are going to struggle to find what they’re after. The data may all be entirely relevant and accurate, but if users cannot find what they need then there is no value in the lake itself. Essentially, data drowning is when the amount of data is so vast you lose the ability to find what’s in there.
If you ignore these challenges, treat the lake like a dumping ground, you will have contaminated your lake and it will no longer be fit for purpose.
If no one uses the Data Lake, it’s a pointless endeavour and not worth maintaining.
Everyone needs to be working together to ensure the lake stays clean, managed and good for a data dive!
Those are the risks and challenges we face with Azure Data Lake. But how do we manage it?
The Framework

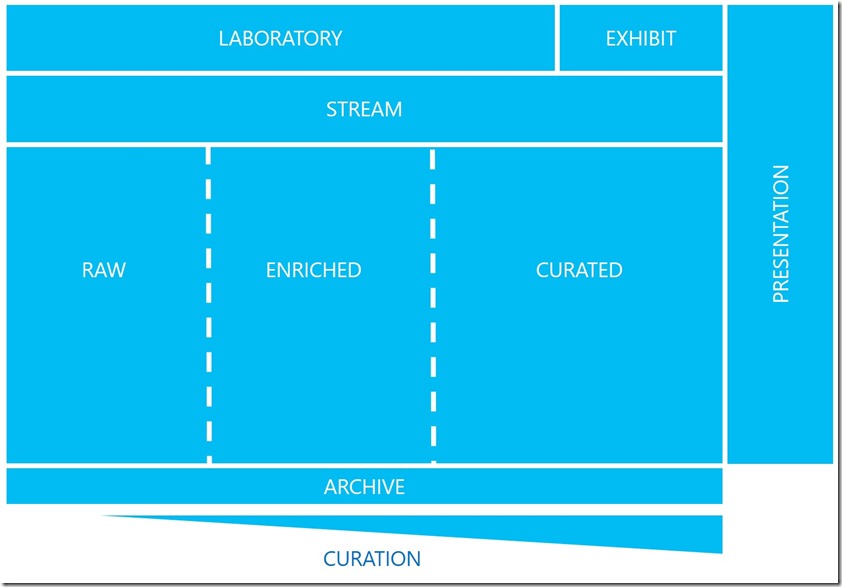
We’ve carved the lake up into different sections. The key point is that the lake contains all sorts of different data – some that’s sanitised and ready to consume by the business user, some that’s indecipherable raw data that needs careful analysis before it is of use. By ensuring data are carefully managed you can instantly understand the level of preparation that data has undergone.
Data flows from left to right – the further left areas represent where data has been input directly from source systems. The horizontal sections describe the level of preparation – Manual, Stream and Batch.
Manual – aka, the laboratory. Here data is manually prepared with ad-hoc scripts.
Stream – The data here flows in semi-real time, coming from event hubs and being landed after processing through stream-specific tools such as Streaming Analytics. Once landed, there is no further data processing – the lake is essentially a batch processing tool.
Batch – This is more traditional data processing, the kind of “ETL” seen by many BI developers. We have a landing area for our raw data, a transitional area where data is cleaned, validated, enriched and augmented with additional sources and calculation, before finally being placed in a curated area where it is ready for consumption by the business.
We’re taking the blank-canvas of the Data Lake Store and applying a folder structure, a file management process and a curation process over the top.
The folder structure itself can be as detailed as you like, we follow a specific structure ourselves:

The Raw data area, the landing place for any files entering the lake, has sub-folders for each source of data. This allows for the easy browsing of the data sources within the Lake and ensures we are not receiving the same data twice, even if we use it within different systems.
The Enriched and Curated layers however, have a specific purpose in mind. We don’t take data and enrich/clean/process it without a business driver, it’s not something we do for fun. We can therefore assign a project or system name to it, at this point it is organised into these end-systems. This means we can view the same structure within Enriched as within Curated.
Essentially Raw data is categorised by Source whilst Enriched and Curated data is categorised by Destination.
There’s nothing complicated about the Framework we’ve created or the processes we’ve ascribed to it, but it’s incredibly important that everyone is educated on the intent of it and the general purpose of the data lake. If one user doesn’t follow process when adding data, or an ETL developer doesn’t clean up test files, the system starts to fall apart and we succumb to the challenges we discussed at the start.
To summarise, structure in your Azure Data Lake Store is key to maintaining order:
- You need to enforce and maintain folder structure.
- Remember that structure is necessary whether using unstructured data or tables & SQL
- Bear in mind that schema on read applies temporary structure – but if you don’t know what you’re looking at, this is going to be very hard to do!
Introduction to Data Wrangler in Microsoft Fabric
What is Data Wrangler? A key selling point of Microsoft Fabric is the Data Science
Jul
Autogen Power BI Model in Tabular Editor
In the realm of business intelligence, Power BI has emerged as a powerful tool for
Jul
Microsoft Healthcare Accelerator for Fabric
Microsoft released the Healthcare Data Solutions in Microsoft Fabric in Q1 2024. It was introduced
Jul
Unlock the Power of Colour: Make Your Power BI Reports Pop
Colour is a powerful visual tool that can enhance the appeal and readability of your
Jul
Python vs. PySpark: Navigating Data Analytics in Databricks – Part 2
Part 2: Exploring Advanced Functionalities in Databricks Welcome back to our Databricks journey! In this
May
GPT-4 with Vision vs Custom Vision in Anomaly Detection
Businesses today are generating data at an unprecedented rate. Automated processing of data is essential
May
Exploring DALL·E Capabilities
What is DALL·E? DALL·E is text-to-image generation system developed by OpenAI using deep learning methodologies.
May
Using Copilot Studio to Develop a HR Policy Bot
The next addition to Microsoft’s generative AI and large language model tools is Microsoft Copilot
Apr