Announced at the recent PASS Summit, Power BI Dataflows has now gone into public preview. Previously, any ETL that users applied via Power Query within Power BI Desktop was only applied to their own dataset. With Dataflows, ETL processes are now classified as a first-class citizen and this update provides centralised self-service data prep as part of the Power BI product so that business users can expose cleaned/schematised entities across the business in a similar way to a Data Warehouse. No longer will the same lightweight ETL processes be occurring across multiple users for the same dataset, and often in different ways. Traditionally, self-service BI is limited to analytic models and reports/dashboards but with Dataflows that is changing as it shifts down a peg. In this blog, I’ll take a look at the new functionality and give my thoughts.
Before we begin, its worth noting that this is an entirely different piece of functionality to that of the similarly named Data Flows in Data Factory which is in private preview. You can tell the difference by the capitalisation of the word “Flow” for Data Factory. I’m not sure what the marketing department would say about this but it is slightly confusing having both been released as news at the same time.
What is a Dataflow?
A dataflow is a collection of entities (which are similar to tables) that are created and managed from within the Power BI Service (powerbi.com). This is then stored under the Common Data Model (CDM) in an Azure Data Lake Storage (Gen2) resource as files and folders – no longer as a Tabular Model that we are used to with Datasets. Dataflows are used to ingest, cleanse, transform, enrich and schematize/model the data in a similar way to that of ETL to create a Data Warehouse. Once created you can use Power BI Desktop to create datasets based off of these entities in the usual manner. While dataflows can be created and edited by both Pro and Premium users, there is a larger set of functionality only available via premium. This includes creating computed entities (calculation aggregates), linking to existing entities in other dataflows, and incremental refreshes.
Creating a Dataflow
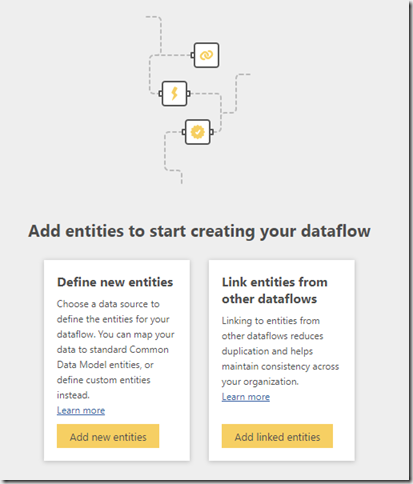
To go about creating a dataflow, navigate to an App Workspace on the Power BI Service (note that this cannot be My Workspace for obvious reasons, also note this cannot be done in Power BI Desktop). You’ll notice alongside Dashboards, Reports, Workbooks, and Datasets that there is a new artefact labelled Dataflows (Preview). If you have Premium capacity this will need to be enabled via the Admin Portal Capacity Settings. Click the + Create and select Dataflow. Each dataflow has only one owner and only the owner can edit it. To create a dataflow, you can either define new entities which involves connecting to a data source and then mapping to the Common Data Model entities / defining custom entities OR linking to other existing dataflows (see below).

If you are creating new entities, you are provided with a set of familiar data source connectors (see below). This set is not as complete as those through Power BI Desktop but I expect more to appear within time. I suspect there is also more work to do here because some of these connectors documented below, i.e. Excel – ask for a File Path or URL without giving any functionality to go get this through a lookup. This is something we have come to expect as part of Power BI Desktop.

Once you have loaded your data, you will then be provided with a fairly familiar query editor pane (see below). The first thing you will notice is that the options to manipulate and transform your data are limited to that of Power Query as part of Power BI Desktop. Again, I suspect this will mature when the functionality hits GA but for the time being gives some reasonable functionality to do what you need to do to create entities in the form of column/row transformations. You are also provided an option to “map to standard” which allows you to join into the Common Data Model (CDM), essentially some generic templates for entities such as Account/Product/Customer/etc. While I can see how this could be useful for an average user, I think it would still be better to create your own based around your businesses own definition of an Account/Product/Customer/etc. These are then stored as custom entities within the CDM. Once the entities are transformed/schematised how you want them, you save them to the Power BI Service with a name/description. Under the hood, this is then written to a Data Lake as a series of files along with a JSON schema.

Dataflows are then available via Power BI Desktop using Get Data (see below). I believe you will need the November 2018 release or later to see this option. The dataset is then treated in a similar way to everything else you would have seen previously within Power BI Desktop. When selected, you should be able to see all of the workspaces within your BI tenant that you have access to which contain dataflows. Within each dataflow you can see each entity.
That’s really it, they’ve kept it simple on purpose and abstract from what’s going on under the hood.

Wait, but what does this mean for the classic Enterprise Data Warehouse?
I certainly think from a business perspective it will blur the lines slightly between using traditional ETL processes to create a DW or going down this route, more so at smaller scales. It would be hard pressed to replace an Enterprise level solution, but there is definitely a use case somewhere around departmental level instead of creating a data mart. It will allow users to leverage their data faster than waiting on IT to build out a solution.
It really depends on the complexity and maturity of the platform they are intending to develop and its purpose. The fact is sits on ADLS Gen2 is a positive and allows other applications to access the data at a raw level rather than relying on a specific connector. It also allows users of products such as PowerApps to connect into a cleaned CDM, another plus.
On the other side, its worth bearing in mind that you will need the Premium version to facilitate incremental refresh which is required by the majority of data warehouse solutions. The lowest cost of Power BI Premium is that of a single P1 node which costs at the time of writing £3,766/month or £45k/pa – not small by any standards. This is worth taking into consideration.
The other fact is that traditional DWHs deal with concepts such as SCD Type II and creating History which Dataflows will not be able to facilitate. You may also have noticed there was no mention of DAX or measures, which still needs to be down at the usual level within Power BI Desktop, not ideal to share KPIs across users. Lastly, there is currently no data lineage, although this has been rumoured to be part of the roadmap.
Conclusion
While this feature will be a game changer for a number of end users and projects, I think it will join the set of questions such as “Do I need SSAS or can I use Power BI for my models?” I expect to see this appear at next years conferences! The answer will always be – it depends!
As we have seen with some aspects of Power BI, this new functionality also opens up businesses to governance issues with potentially having users create their own version of the truth rather than something which has been thought out and modelled by someone with a certain skillset or authoritative source. This could cause contention between departments.
As noted above, I expect the Power BI team to continue to mature the functionality of the product – but for the time being, it certainly opens up another avenue to draw people into the toolset and provide another level of functionality for business and users alike.
Introduction to Data Wrangler in Microsoft Fabric
What is Data Wrangler? A key selling point of Microsoft Fabric is the Data Science
Jul
Autogen Power BI Model in Tabular Editor
In the realm of business intelligence, Power BI has emerged as a powerful tool for
Jul
Microsoft Healthcare Accelerator for Fabric
Microsoft released the Healthcare Data Solutions in Microsoft Fabric in Q1 2024. It was introduced
Jul
Unlock the Power of Colour: Make Your Power BI Reports Pop
Colour is a powerful visual tool that can enhance the appeal and readability of your
Jul
Python vs. PySpark: Navigating Data Analytics in Databricks – Part 2
Part 2: Exploring Advanced Functionalities in Databricks Welcome back to our Databricks journey! In this
May
GPT-4 with Vision vs Custom Vision in Anomaly Detection
Businesses today are generating data at an unprecedented rate. Automated processing of data is essential
May
Exploring DALL·E Capabilities
What is DALL·E? DALL·E is text-to-image generation system developed by OpenAI using deep learning methodologies.
May
Using Copilot Studio to Develop a HR Policy Bot
The next addition to Microsoft’s generative AI and large language model tools is Microsoft Copilot
Apr