I was lucky enough to attend the PASS Summit in Seattle last week and was therefore able to see some early demos of some new features coming to various Azure products. One of the key new releases that caught my eye was the implementation of Importance for workload management in Azure SQL Data Warehouse.
The concept of workload management is a key factor for Azure SQL DW as there is only limited concurrency slots available and depending on the resource class, these slots can fill up pretty quickly. Once the concurrency slots are full, queries are queued until a sufficiently sized slot is opened up. Let’s recap what Resource Classes are and how they affect workload management.
A Resource Class is a pre-configured database role that determines how much resource is allocated to queries coming from users that belong to that role. For example, an ETL service account may use a “large” resource class and be allocated a generous amount of the server, however an analyst may use a “small” resource class and therefore only use up a small amount of the server with their queries. There are actually 2 types of resource class, Dynamic and Static. The Dynamic resource classes will grant a set percentage of memory to a query and actual value of this percentage will vary as the Warehouse scales up and down. The key factor is that an xLargeRc (extra-large resource class) will always take up 70% of the Server and will not allow any other queries to be run concurrently. No matter how much you scale up the Warehouse, queries run with an xLargeRc will run one at a time. Conversely, queries run with a smallrc will only be allocated 4% of the Server and therefore as a Warehouse scales up, this 4% becomes a larger amount of resource and can therefore process data quicker.
The static resource class offers a fixed amount of memory per query regardless of scale. This means that as the Warehouse gets scaled up, the concurrency increases with it. More detail on Resource Classes in SQL Data Warehouse is available here (https://docs.microsoft.com/en-us/azure/sql-data-warehouse/resource-classes-for-workload-management)
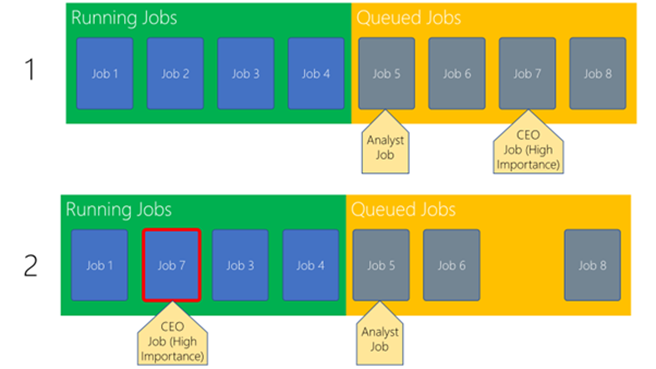
The new Importance feature, that will be released into preview on 1st December, allows administrators to specify the importance of a user, thereby affecting the order in which jobs are processed off the queue by the server. To illustrate Importance, we can use the example of a CEO and an Analyst, both of which are trying to run queries against the SQL DW Instance. Assuming the CEO has been tagged with a high importance then their queries will be pulled off the queue before the analyst, as illustrated in the below diagram:

In the above diagram, Job 2 finishes and therefore Job 7 is pulled off the queue because it originated from the CEO with High Importance. The analyst job with lower importance is left in the queue until another slot opens up.
Importance can also affect how the SQL DW handles locking. The reason for this is that if a job is awaiting a lock on a frequently used table, this lock can often be unavailable for a large amount of time, therefore increasing the time it takes to complete the operation. Importance on top of locking will ensure the locks are reserved for high importance queries so that they can complete much quicker. See the below diagram.

In this image, both Job 1, 2 and Job 3 are running, however in the top queue Job 1 currently has the lock on a table that both Job 2 and Job 3 will need. As Job 2 – the Analyst job, was submitted before Job 3 – the CEO job, usually this would secure the lock before the CEO and therefore mean that the CEO would wait longer for their query. However, with Importance enabled, SQL DW knows to hold the lock and grant it to the higher importance so that it can complete first.
Finally, Importance affects how the optimiser chooses which queries to run when. Generally speaking the optimiser accelerates throughput, so as soon as an appropriate sized slot becomes available then the next job is pulled off the queue and executed. However, if a large query is waiting to be run then there is the possibility that it will wait a long time as small jobs continually jump into the smaller slots. See diagram below:


In the above diagram, there are 4 small jobs running, a small job queued for an analyst and a large job queued for the CEO. With Importance turned on, the optimiser knows that when Job 1 finishes it needs to hold the resource so that I can make room for the highly important job 6 and not automatically start job 5. When Job 2 finishes, the optimiser will then push Job 6 to be processed as there is now enough resource to run the process.
Hopefully the above diagrams have illustrated how Importance for Workload Management can ensure that the essential jobs are run before the less essential ones. Please look out for the preview release of this feature on 1st December.
Introduction to Data Wrangler in Microsoft Fabric
What is Data Wrangler? A key selling point of Microsoft Fabric is the Data Science
Jul
Autogen Power BI Model in Tabular Editor
In the realm of business intelligence, Power BI has emerged as a powerful tool for
Jul
Microsoft Healthcare Accelerator for Fabric
Microsoft released the Healthcare Data Solutions in Microsoft Fabric in Q1 2024. It was introduced
Jul
Unlock the Power of Colour: Make Your Power BI Reports Pop
Colour is a powerful visual tool that can enhance the appeal and readability of your
Jul
Python vs. PySpark: Navigating Data Analytics in Databricks – Part 2
Part 2: Exploring Advanced Functionalities in Databricks Welcome back to our Databricks journey! In this
May
GPT-4 with Vision vs Custom Vision in Anomaly Detection
Businesses today are generating data at an unprecedented rate. Automated processing of data is essential
May
Exploring DALL·E Capabilities
What is DALL·E? DALL·E is text-to-image generation system developed by OpenAI using deep learning methodologies.
May
Using Copilot Studio to Develop a HR Policy Bot
The next addition to Microsoft’s generative AI and large language model tools is Microsoft Copilot
Apr