In the previous article (click here) we talked about the common big data challenges. One of the most frequently faced issue by data engineers is the performance of queries. Using several techniques listed below, Delta Lake tackles these challenges and can significantly improve the query performance:
- Data Indexing – Delta automatically creates and maintains index of files (paths). The index is used for data skipping.
- Data Skipping – By calculating basic file statistics (like minimum and maximum values), keeping indexing and information about the partitioning only relevant subsets of the data is read when queried using filters.
- Compaction (bin-packing) – Delta manages sizes of the underlying Parquet files by coalescing small files into larger ones.
- Z-Ordering (multi-dimensional clustering) – Delta rearranges the data in order to colocate related information in the same set of files
- Data Caching – Delta automatically caches highly accessed data, which results in significantly improved reading speed.
- Joins Optimisation – by specifing range, point-in-interval or overlap range we can help speeding up join query. Reference docs for more info.
Let’s see some examples of how we can speed up the query time.
Data compaction (bin-packing)
As the source data we are going to use a public data offered by Databricks. It is located on the internal Databricks File System at the path dbfs:/databricks-datasets/samples/lending_club/parquet/. Under this link you can find the original source of that data that comes from the Kaggle data science community. All the queries used in this article were executed with free Databricks Community Edition (DBCE) using standard Community Optimized cluster with 6GB Memory, 0.88 cores, 1 DBU and Databricks Runtime 6.3.
The loan stats data is by default partitioned into 5 files between 20 MB and 70 MB in size. Very often, however, engineers have to deal with hundres and thousands of relatively small files (~1MB os smaller). Too many small files dramatically reduces the efficency of operations run of the dataset. Let’s simulate this situation and repartition the dataframe into 1200 parts.
# Configure locations
sourcedata_path = "/databricks-datasets/samples/lending_club/parquet/"
deltalake_path = "/tmp/lending_club_delta/"
# Read loan stats
loan_stats = spark.read.parquet(sourcedata_path)
# Remove table if it exists
dbutils.fs.rm(deltalake_path, recurse=True)
# Save table in Delta format as 1200 parts
loan_stats.repartition(1200).write.format("delta").mode("overwrite").save(deltalake_path)
# Re-read as Delta Lake
loan_stats_delta = spark.read.format("delta").load(deltalake_path)
spark.sql("DROP TABLE IF EXISTS loan_stats_delta")
spark.sql("CREATE TABLE loan_stats_delta USING DELTA LOCATION '/tmp/lending_club_delta'")
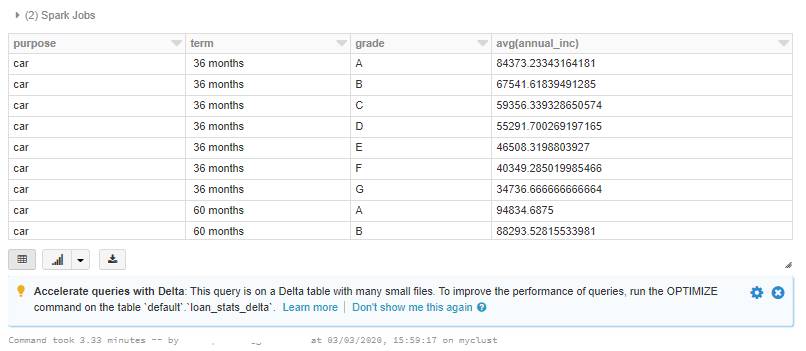
Once the data is loaded, we run a simple SELECT query with one aggregation and a filter. Notice that it takes about a few minutes (~3-4 minutes) to process the query.
%sql
SELECT purpose, term, grade, avg(annual_inc)
FROM loan_stats_delta
WHERE purpose IN ('car','credit_card','house')
GROUP BY purpose, term, grade
ORDER BY purpose, term, grade
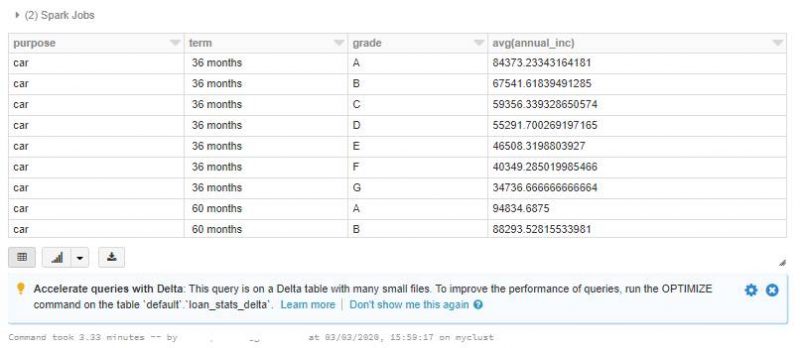
There’s also a hint from Databricks engine that we should OPTIMIZE the dataset as there are simply too many small files. But before we do that, let’s take a look at the files that are underneath it. All of them are about 0.2mb in size and this is considered very small file size for Spark. Spark would really like be reading files that are hunderds and even 1GB in size. When we issue above query all of 1200 small files has to be open and read through and that makes the performance not the one we’d like to have.
%fs ls /tmp/lending_club_delta
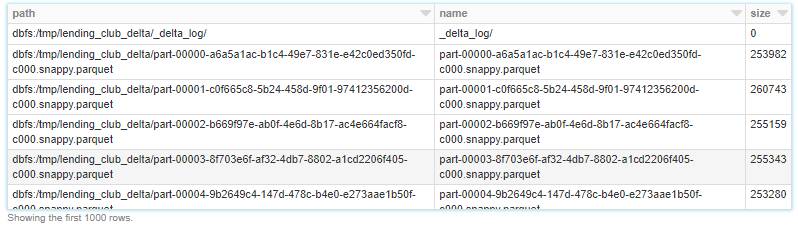
Let’s run the OPTIMIZE command (see docs). This is the key feature of Delta Lake optimisation methods. What it does is simply coalesing and compacting the files into larger ones (bin-packing optimisation). The sweet spot of file size researched by Databricks for best query performance is around 1 GB and OPTIMIZE command will eventually produce files around that size if possible. We can however control this “sweet spot” size and change it if needed spark.conf.get("spark.databricks.delta.optimize.maxFileSize")
Let’s run it.
%sql OPTIMIZE loan_stats_delta
…and check once again same SELECT query we run a moment ago.
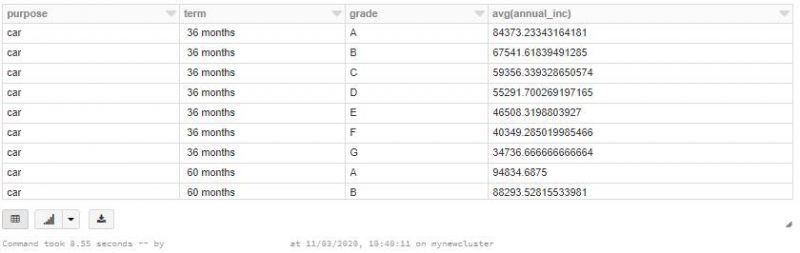
There’s a significant improvement in query execution time (less than 10sec). But as you noticed there’s a huge side cost of that “performance improvement”, mainly OPTIMIZE is an expensive operation in time and resources. In our case it took more than 3 minutes to finish the optimisation process. That’s why it is not triggered automatically by Delta Lake and engineer has to analyse and decide on a trade-off between performance and cost when it comes to how often OPTIMIZE should be run.
How do our files look like in DBFS?
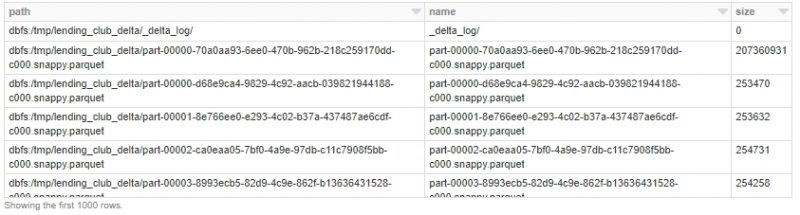
There are still a bunch of small files. That’s because Databricks Delta manages transactions – there might be queries or longer running processes that are still accessing older files after compaction completes. Any new queries or jobs submitted at this time end up accessing the newer, larger files, but any existing jobs would still query the older files.
You can clean these up periodically by calling the VACUUM command. By default VACUUM removes files that are older than 7 days. But you can manually set your own retention by specifying a RETAIN parameter. It’s highly recommended that you do not set the retention to zero hours, unless you are absolutely certain that no other processes are writing to or reading from your table. To set retention below 168 hours we need to change the cluster configuration disabling retention check: spark.conf.set("spark.databricks.delta.retentionDurationCheck.enabled",False)
%sql VACUUM loan_stats_delta RETAIN 0 HOURS

Auto Optimize
Having a bunch of small files is not by default a negative scenerio. On the contrary, there are scenerios when queries run much faster is they operate on rather smaller files than 1 GB. For example:
- Streaming use cases where latency in the order of minutes is acceptable.
MERGE INTOis the preferred method of writing into Delta Lake. (Large files are great for queries, not for MERGE)CREATE TABLE AS SELECTorINSERT INTOare commonly used operations.
For such cases there’s AUTO OPTIMIZE created that will automatically compact small files during individual writes to a Delta table but will compact files to 128 MB instead of 1 GB. For further information on how to use it, please reference the docs.
Data Caching
Let’s take a step further in improving the query performane in our example. We can use the Delta cache feature that will automatically create copies of remote files in nodes’ local storage. Thanks to that any successive reads of the same data are then performed locally without the need to move the data between nodes.
By default the Delta cache feature is disabled if we did not choose Delta Cache Accelerated worker type when setting up the cluster
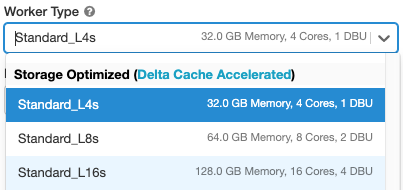
We can check if it is enabled with spark.conf.get("spark.databricks.io.cache.enabled") and if disabled, turn it on spark.conf.set("spark.databricks.io.cache.enabled", True)
Let’s rerun our reference query. Notice the execution time – in our case it’s more than 4 sec.
%sql
SELECT purpose, term, grade, avg(annual_inc)
FROM loan_stats_delta
WHERE purpose IN ('car','credit_card','house')
GROUP BY purpose, term, grade
ORDER BY purpose, term, grade
If we take a look at the Spark log from the query that we have just run, you’ll notice that no data was read from cache but there was some MB of data written to cache.
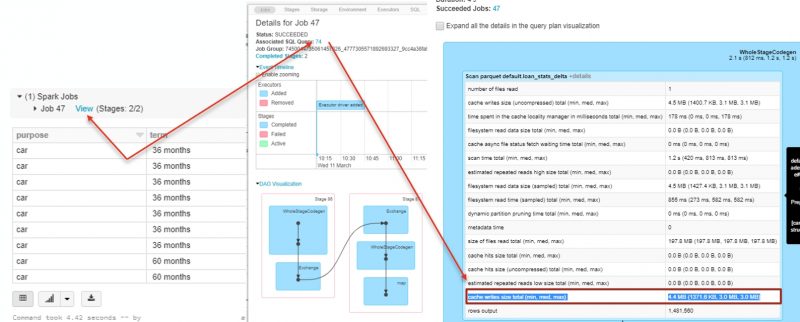
Rerun the above query. Now the query run 2-4x faster as part of the data was read from the Delta cache.
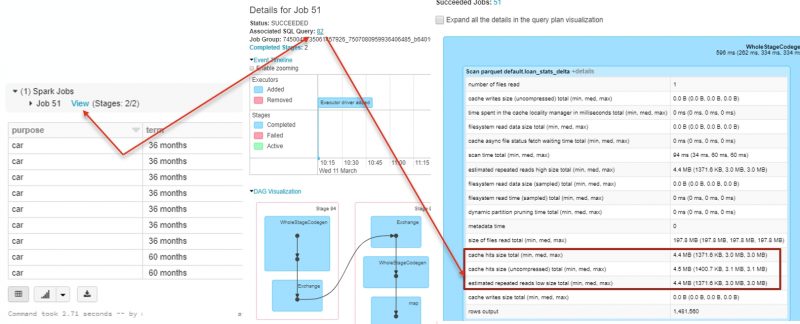
We can monitor the current state of the Delta cache on each of the executors in the Storage tab in the Spark UI.
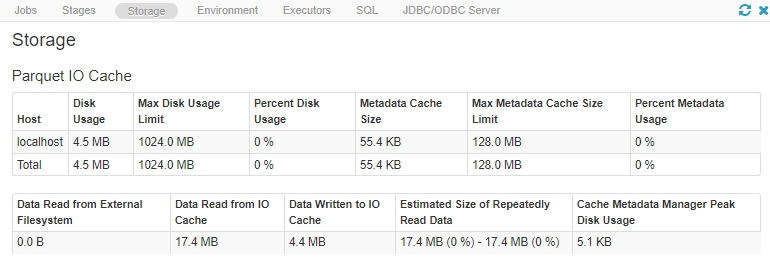 .
.
Summary
To improve query performance Delta Lake introduced a row of features and it keeps implementing new ones. By default the Delta Lake maintains basic statistics about the data as well as the index of files and partitions where the data is stored. Thanks to that every time we run a query the engine does not have to scan whole dataframe but by using idices and statistics kept in Delta Log it can skip most of the data and open only the files that are needed to process the query. Additionally, we have ability so tune the performance by either manually running OPTIMIZE command with Z-ORDER to compact small files and co-locate the data mostly used, or we can turn on automatic Delta caching and/or Auto Optimisation. We need however bear in mind that while some optimisation features (that redistributes data in files) can help us speeding up the execution time of some queries (e.g. OPTIMIZE), they can in the same time slower other queries (e.g. MERGE that “likes” much smaller files than default 1GB by OPTIMIZE)
There are also other optimisation techniques that you can implement to even further tune up your transformation, especially joins.
The Delta Lake team is continuously updating the docs and adding new capabilties for performance’s enhancements, so it’s worth to refresh the docs (click here) when developing ETL pipeline using the Delta Lake.
You can download here Adatis_PerformanceEnhancements_20200311 the databricks notebook with above example codes that you can import and run in Databrick Community Edition (DBCE). You need to unzip and import HTML within DBCE.
If you would like to know how we could help you with your data, please get in touch.
Introduction to Data Wrangler in Microsoft Fabric
What is Data Wrangler? A key selling point of Microsoft Fabric is the Data Science
Jul
Autogen Power BI Model in Tabular Editor
In the realm of business intelligence, Power BI has emerged as a powerful tool for
Jul
Microsoft Healthcare Accelerator for Fabric
Microsoft released the Healthcare Data Solutions in Microsoft Fabric in Q1 2024. It was introduced
Jul
Unlock the Power of Colour: Make Your Power BI Reports Pop
Colour is a powerful visual tool that can enhance the appeal and readability of your
Jul
Python vs. PySpark: Navigating Data Analytics in Databricks – Part 2
Part 2: Exploring Advanced Functionalities in Databricks Welcome back to our Databricks journey! In this
May
GPT-4 with Vision vs Custom Vision in Anomaly Detection
Businesses today are generating data at an unprecedented rate. Automated processing of data is essential
May
Exploring DALL·E Capabilities
What is DALL·E? DALL·E is text-to-image generation system developed by OpenAI using deep learning methodologies.
May
Using Copilot Studio to Develop a HR Policy Bot
The next addition to Microsoft’s generative AI and large language model tools is Microsoft Copilot
Apr