The topic of Optical Character Recognition (OCR) is not an unexplored field to the Adatis audience. Some Adati like Kalina Ivanova (link1, link2) and Francesco Sbrescia (link3) have already explored this topic from the perspective of Azure Cognitive Services and Azure Data Lake. In my first blog, I would like to explore this topic from a different perspective: using Tesseract and Databricks.
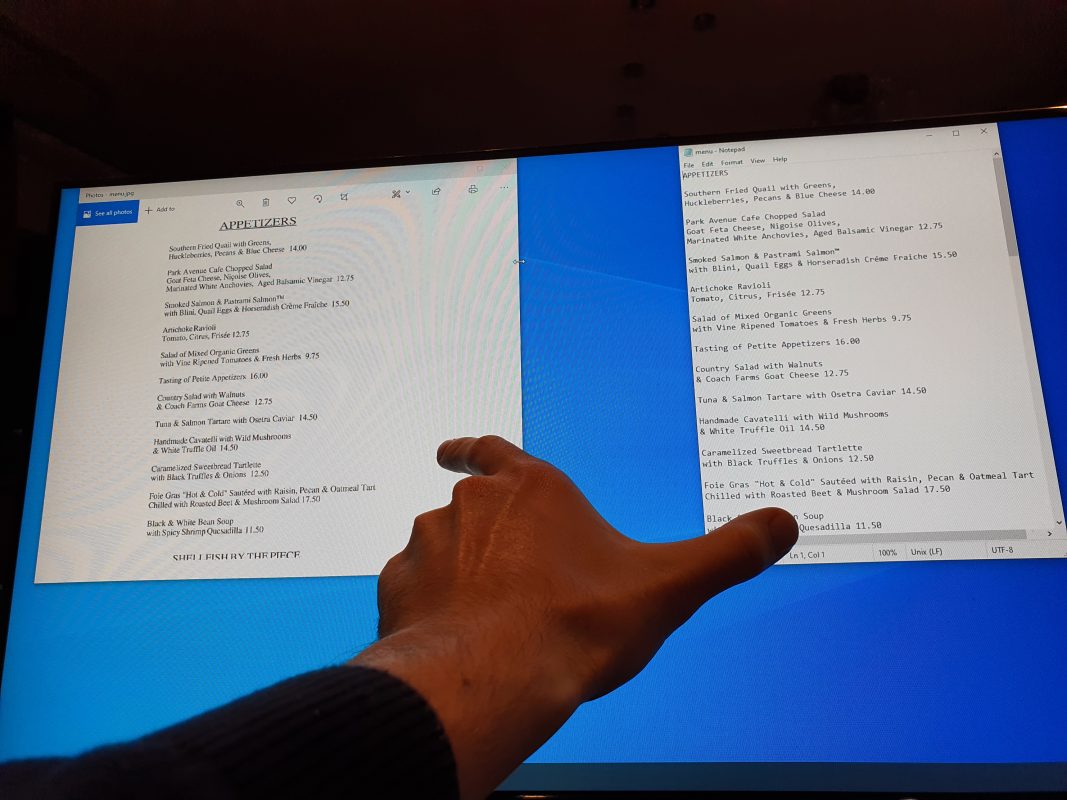
Before extracting any information from a picture, we need to read it first. In our example, we will use this menu:

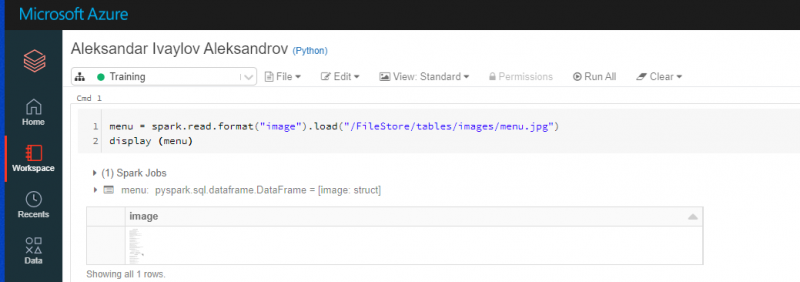
Let`s read the menu in Databricks:
menu = spark.read.format("image").load("/FileStore/tables/images/menu.jpg")
display (menu)
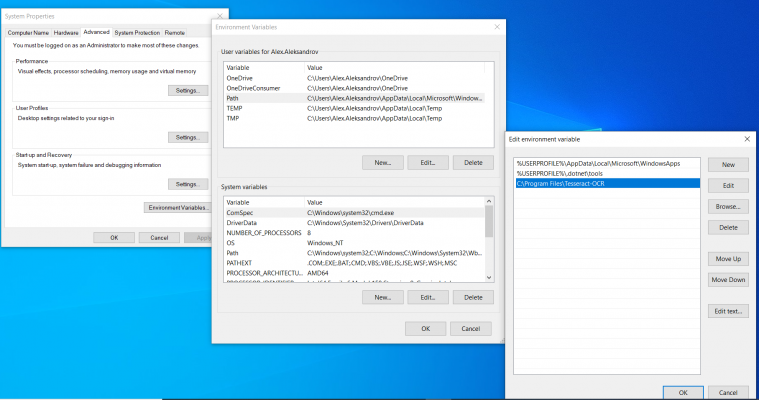
Now for the purpose of OCR, we would use the Google’s tesseract library. You can install it from here. The process of installation is simple – you just need to follow the instructions. After the installation, it is very important to add the installation folder to your PATH environment variable. You can do this from the Advanced System Properties:
As a next step, we will locate our PC folder from where we have imported the image to Databricks, and we will run the Command Prompt from there:
After we have opened the Command Prompt in the directory of the image, we type the following command:
tesseract menu.jpg menu
This command will create a txt file from our image. Look what we have before the execution and after it:
Before:
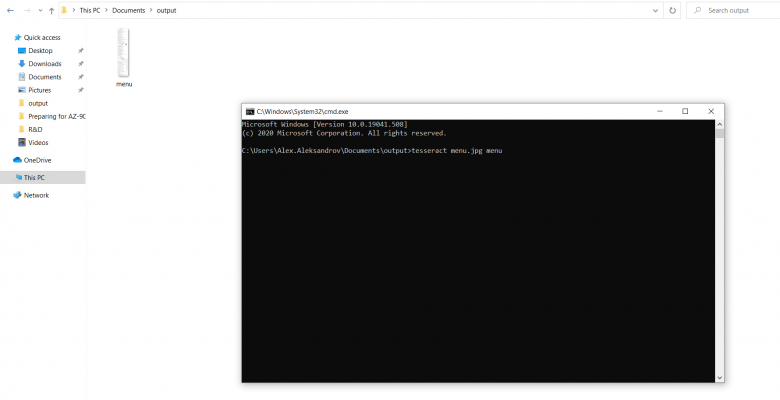
After:
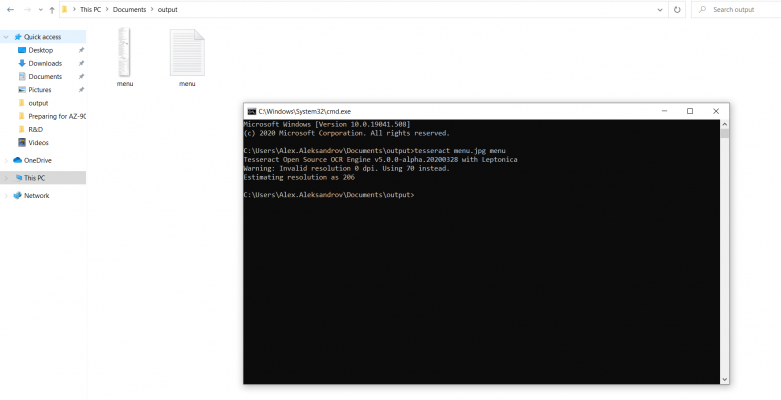
Now we are seeing that we have a txt file with the same name next to the image.
Let`s check whether Tesseract has done its job well. We will import and read the txt file into Databricks:
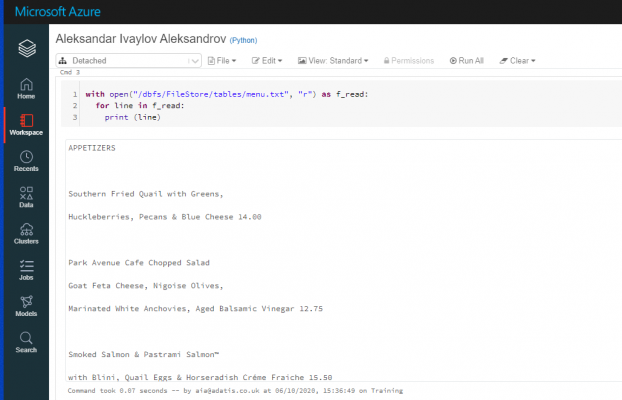
We see that the menu content has been read quite well.
Of course, there are many ways to perform OCR, such as using Spark OCR for example, and doing the process in the cloud, without referring to the on-premises PC environment. Generally, I prefer this hybrid way because it is simple – it takes less resources (prerequisite files, license keys) and less code to accomplish it.
Thank you for your attention. This was my first blog. I hope you find it useful. Expect more blogs on different topics soon.
If you enjoyed this blog, check out our full blog list here.
Introduction to Data Wrangler in Microsoft Fabric
What is Data Wrangler? A key selling point of Microsoft Fabric is the Data Science
Jul
Autogen Power BI Model in Tabular Editor
In the realm of business intelligence, Power BI has emerged as a powerful tool for
Jul
Microsoft Healthcare Accelerator for Fabric
Microsoft released the Healthcare Data Solutions in Microsoft Fabric in Q1 2024. It was introduced
Jul
Unlock the Power of Colour: Make Your Power BI Reports Pop
Colour is a powerful visual tool that can enhance the appeal and readability of your
Jul
Python vs. PySpark: Navigating Data Analytics in Databricks – Part 2
Part 2: Exploring Advanced Functionalities in Databricks Welcome back to our Databricks journey! In this
May
GPT-4 with Vision vs Custom Vision in Anomaly Detection
Businesses today are generating data at an unprecedented rate. Automated processing of data is essential
May
Exploring DALL·E Capabilities
What is DALL·E? DALL·E is text-to-image generation system developed by OpenAI using deep learning methodologies.
May
Using Copilot Studio to Develop a HR Policy Bot
The next addition to Microsoft’s generative AI and large language model tools is Microsoft Copilot
Apr