I wrote an introductory Purview blog post previously, where I explored what the tool is at a reasonably high level and how to get started with registering and scanning sources. If you’re new to Purview, make sure you check that post out first, you can read it here: Getting Started with Azure Purview.
In this post, I’d like to take a look at one of the key features of Purview: Data Lineage. What is it for, and what can and can’t Purview do out of the box at the moment, and how do we use it?
What is Data Lineage?
Data Lineage aims to offer visibility of how and where data is moving within your data estate.
We may have many data sources within an environment, and many transformation steps of the data within those sources, which result in a cleansed and modelled data warehouse. A data lineage tool can help you quickly visualise what sources are used to make up a dimension, for example, or what pipelines data has passed through before reaching a certain point. It can be extremely useful for troubleshooting, visibility, and informing decisions.
Enabling and viewing Data Lineage in Azure Purview
First of all, you need to register the sources you want to record lineage information for. You can find out how to do that from my previous Purview post, linked to at the top of this post.
You also need register the Data Factories or Data Share’s you want to capture lineage information from. To do this, open the Purview Studio, go to the Management Centre, and from the menu on the left click Data Factory in the External connections section. Select New at the top, choose the data factory you’d like to capture lineage information from, and press OK. You should see a green tick and connected message under status. The process is identical for connecting up to a Data Share.
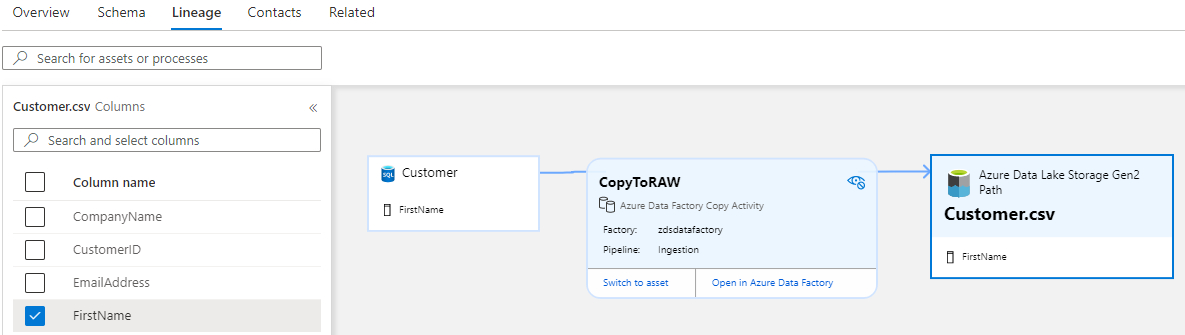
Once your sources and external connections are registered and you’ve run a scan, you can find lineage information by going to Browse assets on the home screen and drilling down into an asset such as a table in a database, or a file in a data lake. Once in an asset, choose Lineage from the top menu, and you should be presented with a screen similar to my example below, assuming your data has some form of lineage to it:
In this example, I built a very simple meta-data driven Azure Data Factory (ADF) ingestion pipeline, which picked data up from an AdventureWorksLT sample database, and landed it into an Azure Data Lake – and this is exactly the story you see from the lineage information. In the screenshot, I’ve selected the “CopyToRAW” box, which is my ADF pipeline, so it’s expanded to show additional details. From here I can switch to the asset to view more information about what’s passing through that pipeline, or I can jump directly to ADF to look under the hood, and see exactly what’s going – very helpful!
Purview has also automatically picked up on the schema of entities I’ve scanned, and has provided a checkbox list of the columns on the left hand side. This allows you to very quickly and easily see where a column, such as FirstName in my example, is used within the lineage of the entity. This could be useful in furthering your understanding of what data is available and where that data is, but could also be extremely useful in troubleshooting where a column might be being lost within a process.
Limitations
At the time of writing this blog the product is still in preview, and there are some limitations to be aware of. Lineage information can only be recorded out of the box via Azure Data Factory, Power BI, and Azure Data Share. This means that if you had something like a SQL Stored Procedure or a Databricks Notebook doing some data transformation of a source table and saving it into another table, you would lose that connection.
Conclusion
The Data Lineage feature in Azure Purview has a great deal of potential to make understanding the flow of data within your data estate a breeze, but it isn’t without its pitfalls at the moment. As the limitation above suggests, there’s a huge dependency on the way your data transformation pipelines are built to get the most out of Data Lineage in Purview. My hope is that the tool will continue to be developed to include more transformation engines, and I have no doubt that it will.
Enjoyed this blog on Azure Purview? Check out our Azure Rapid Landing Zone proposition here for more in-depth knowledge
Introduction to Data Wrangler in Microsoft Fabric
What is Data Wrangler? A key selling point of Microsoft Fabric is the Data Science
Jul
Autogen Power BI Model in Tabular Editor
In the realm of business intelligence, Power BI has emerged as a powerful tool for
Jul
Microsoft Healthcare Accelerator for Fabric
Microsoft released the Healthcare Data Solutions in Microsoft Fabric in Q1 2024. It was introduced
Jul
Unlock the Power of Colour: Make Your Power BI Reports Pop
Colour is a powerful visual tool that can enhance the appeal and readability of your
Jul
Python vs. PySpark: Navigating Data Analytics in Databricks – Part 2
Part 2: Exploring Advanced Functionalities in Databricks Welcome back to our Databricks journey! In this
May
GPT-4 with Vision vs Custom Vision in Anomaly Detection
Businesses today are generating data at an unprecedented rate. Automated processing of data is essential
May
Exploring DALL·E Capabilities
What is DALL·E? DALL·E is text-to-image generation system developed by OpenAI using deep learning methodologies.
May
Using Copilot Studio to Develop a HR Policy Bot
The next addition to Microsoft’s generative AI and large language model tools is Microsoft Copilot
Apr