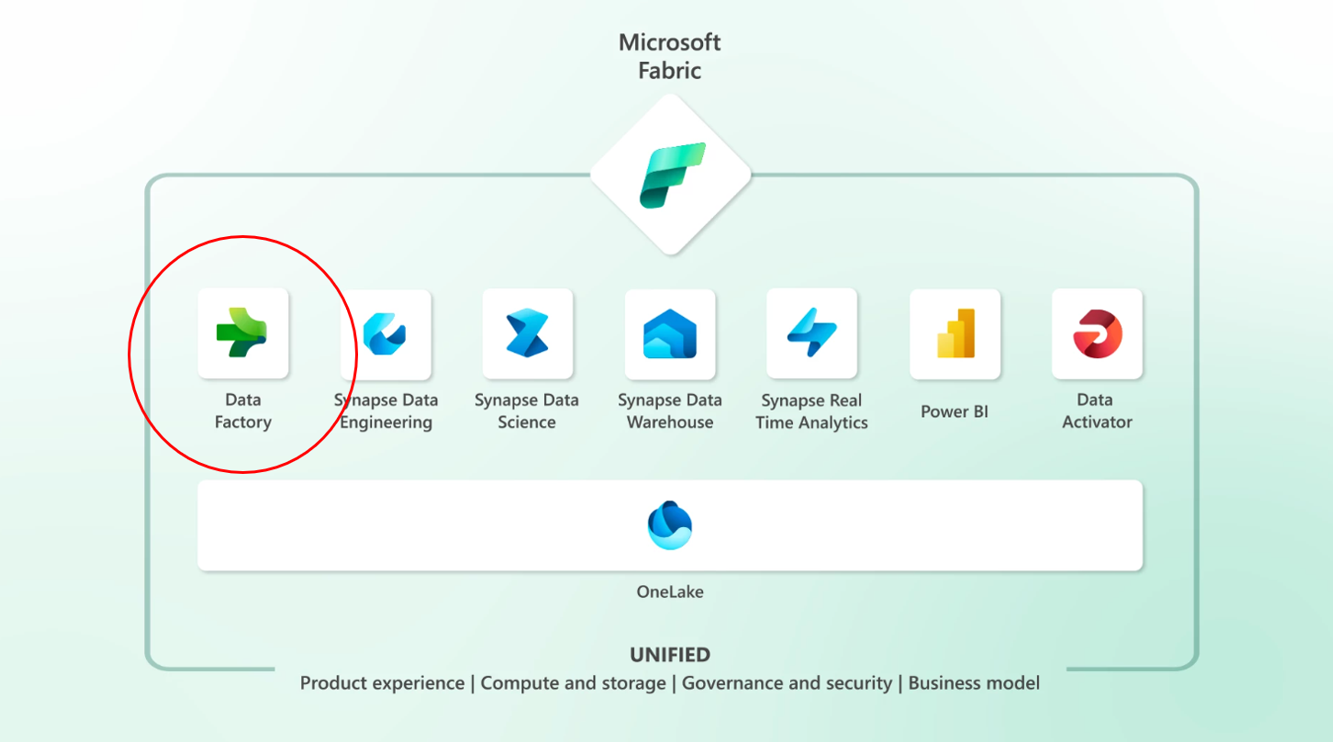
As data engineers, we use Azure Data Factory on a daily basis to collect datasets from sources, process them, and store in target data stores. It provides a robust environment in the Microsoft Azure stack to schedule and manage data pipelines and is generally a very powerful tool for data integration and ETL in the cloud.
As we begin to explore how Microsoft Fabric will change the way we perform these tasks in its end-to-end data analytics platform, I wanted to explore the data integration workload of the service, Data Factory. This short blog will help to understand the next generation of Azure Data Factory, outline some of its key features and compare the differences between Azure Data Factory and Data Factory in Microsoft Fabric.
Azure Data Factory & Power Query Dataflows
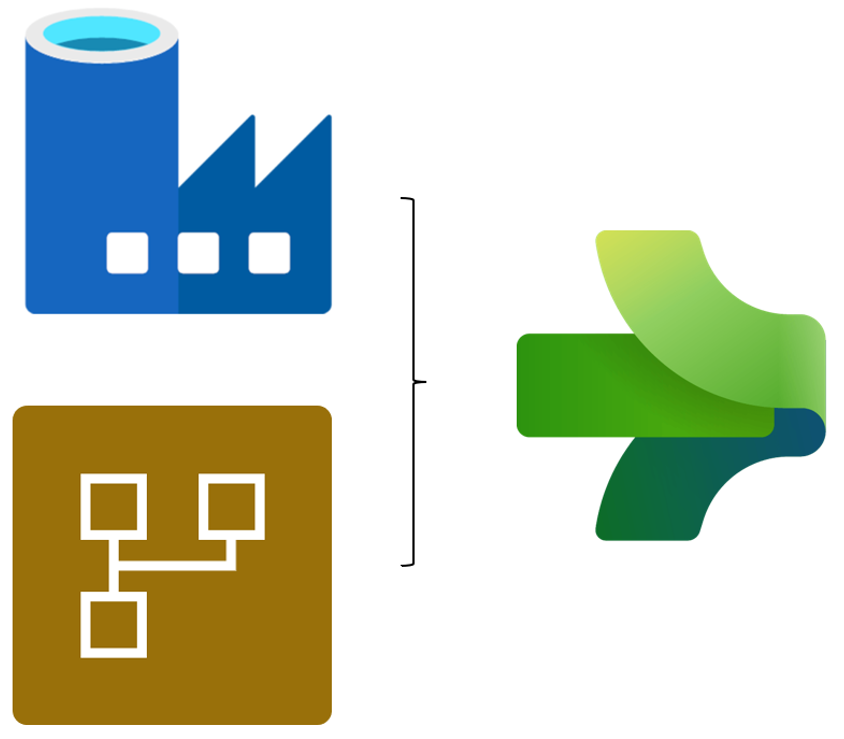
Data Factory in Fabric brings together the functionality of Azure Data Factory and Power Query Dataflows into one product. Initially, Power Query Dataflows was an add-on to Power BI as a simple to use data transformation tool for data analysts in the cloud. Now it is also used for data migration in Power Apps. Azure Data Factory is primarily used for data ingestion, designed for data engineers to create flowing pipelines using task specific modules.
Before Data Factory, there was a split between the two with Power Query Dataflows; an easy-to-use tool for low volumes of data and Azure Data Factory for more scalable solutions. With its introduction into Microsoft Fabric, Data Factory takes the simple approach to data transformation from Power Query Dataflows and couples it with the scalability and ETL pipeline builds from ADF.
Features
Data Connectors
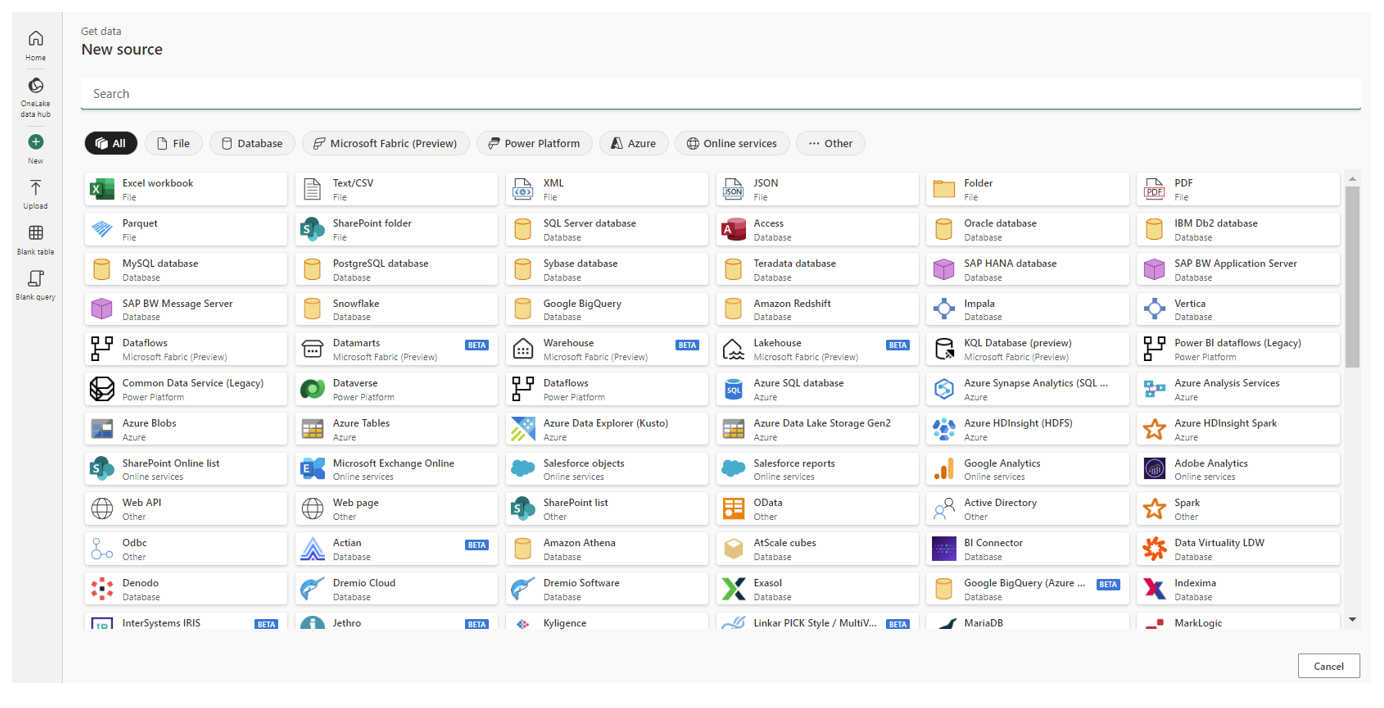
There are many options for data connectivity within Data Factory as shown by the image above, from excel workbooks and JSON files to Azure SQL databases and Databricks. It is also possible to connect directly to the OneLake environment or input a local file, as shown below.
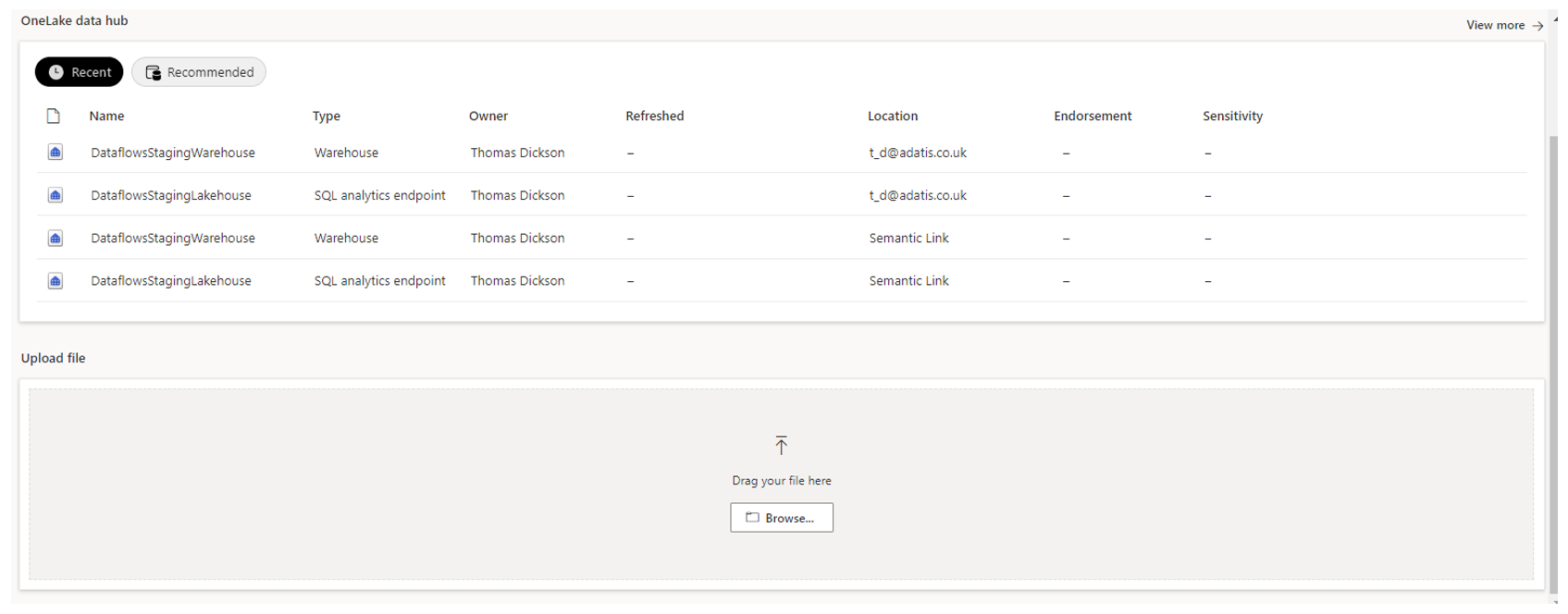
We are given a very modern and simple environment to select our data source, making it really efficient to get connected to our data.
Dataflows
Dataflows are then created using the online Power Query editor and the data transformation engine to retrieve, define and load the data from source to target. A data destination can be selected for the dataflow as shown below, with Azure SQL database, Lakehouse, Azure Data Explorer (Kusto) and Warehouse currently supported.
It is worth noting that the Lakehouse & Data Warehouse are also available as sources, making it very convenient for us to build projects integrated within these.
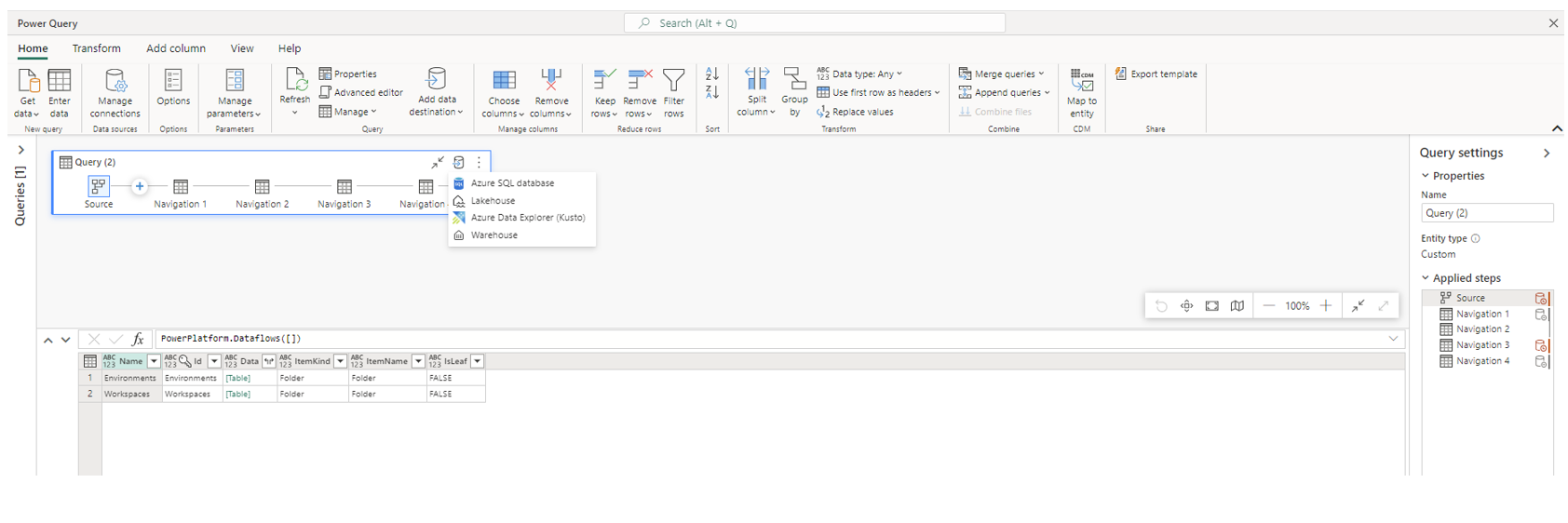
The editor also allows you to write code in M (Power Query language) to develop within the dataflow.
Data Pipelines
As seen in Azure Data Factory, data pipelines are used to create a flow of executable activities to perform specific tasks. In Data Factory, we can incorporate the running of a dataflow into our pipelines to enhance the ETL process. These can then be scheduled to run at certain times or triggered based on the output of another flow.
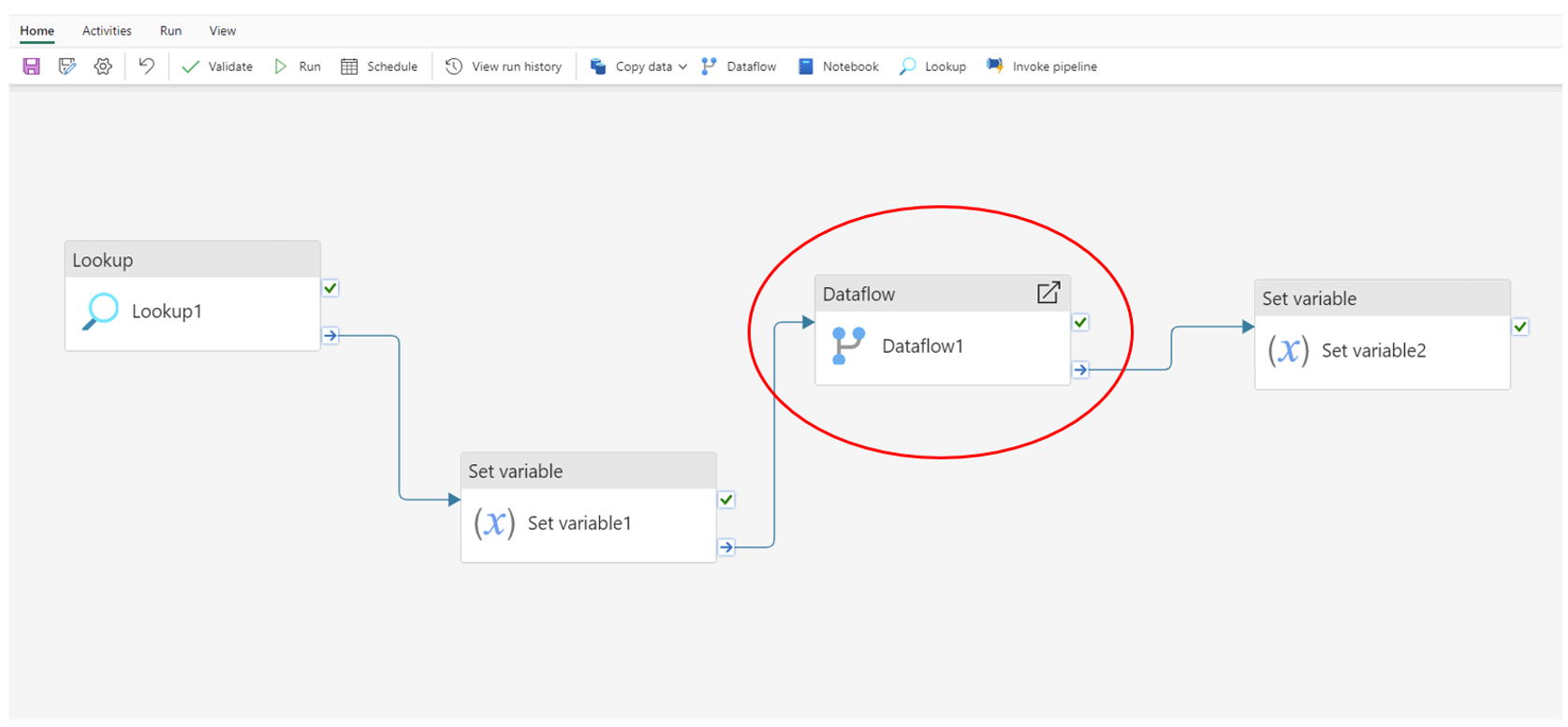
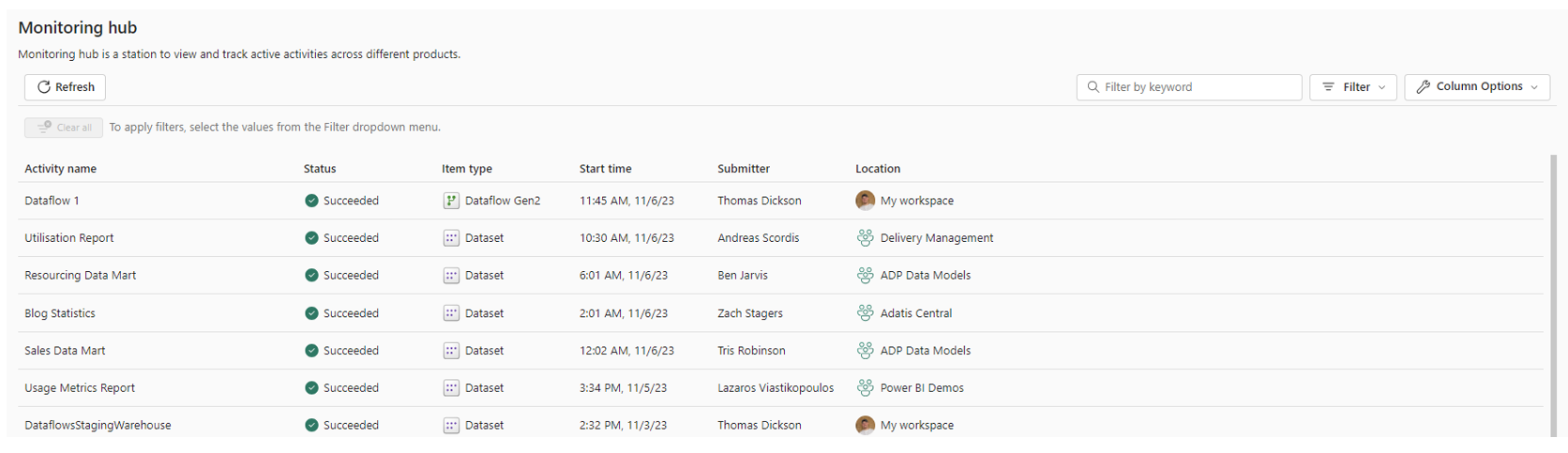
There is now also a unique monitoring hub to track scheduled runs. This feature, combined with dataflows and data pipelines, gives us a full view of all workloads, and allows us to drill down into any activity.
Other Notable Features
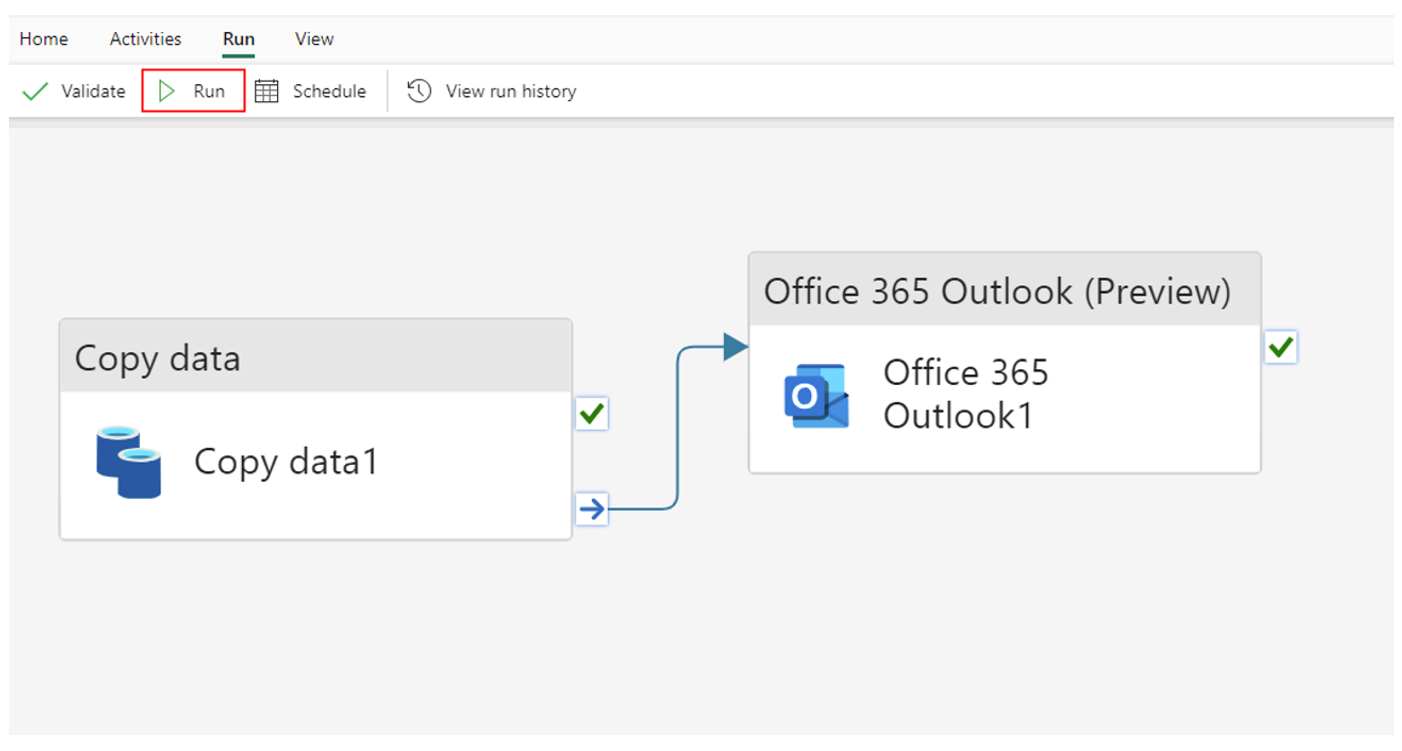
Office 365 outlook activity
There is a new Office 365 outlook activity that allows us to send customised emails detailing the information from our pipelines or pipeline runs.
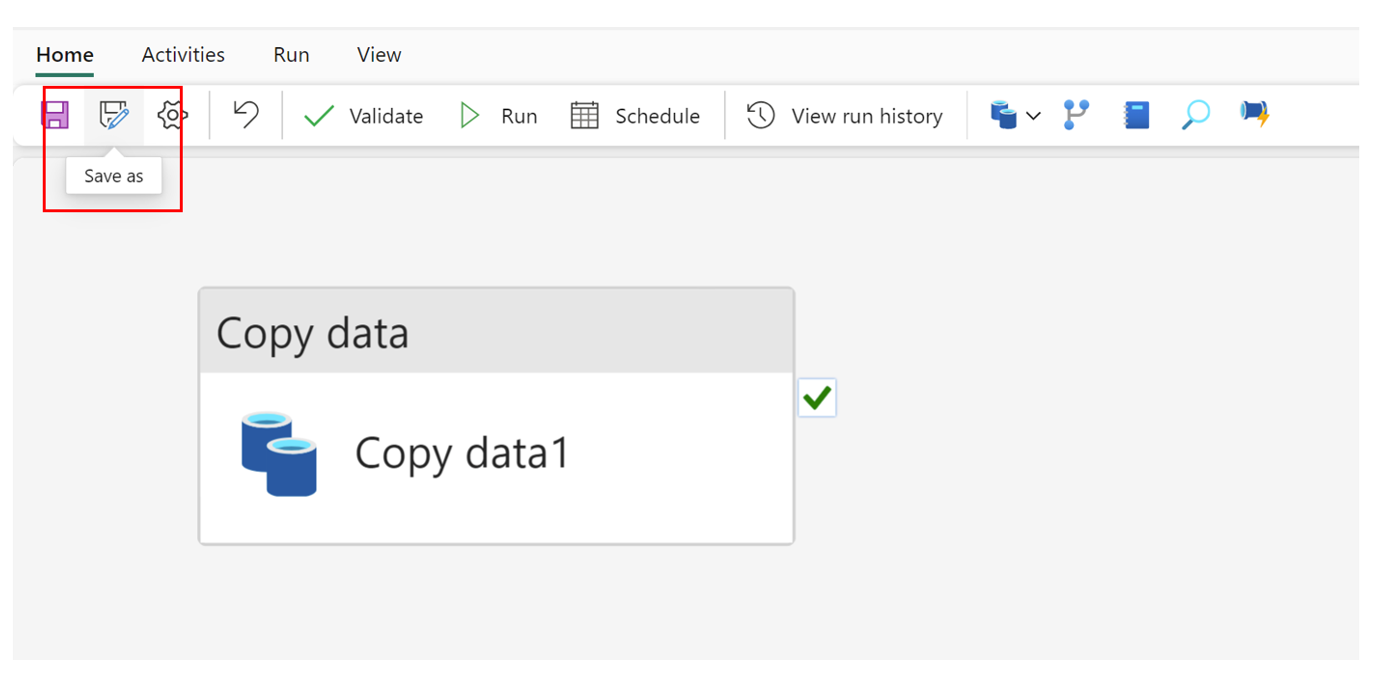
Save As
It is also now possible to save our existing pipelines in a convenient way to duplicate for other development purposes.
Azure Data Factory vs Data Factory in Fabric
For those that use Azure Data Factory on a regular basis, the below table from Microsoft outlines some of the key differences between the two products:
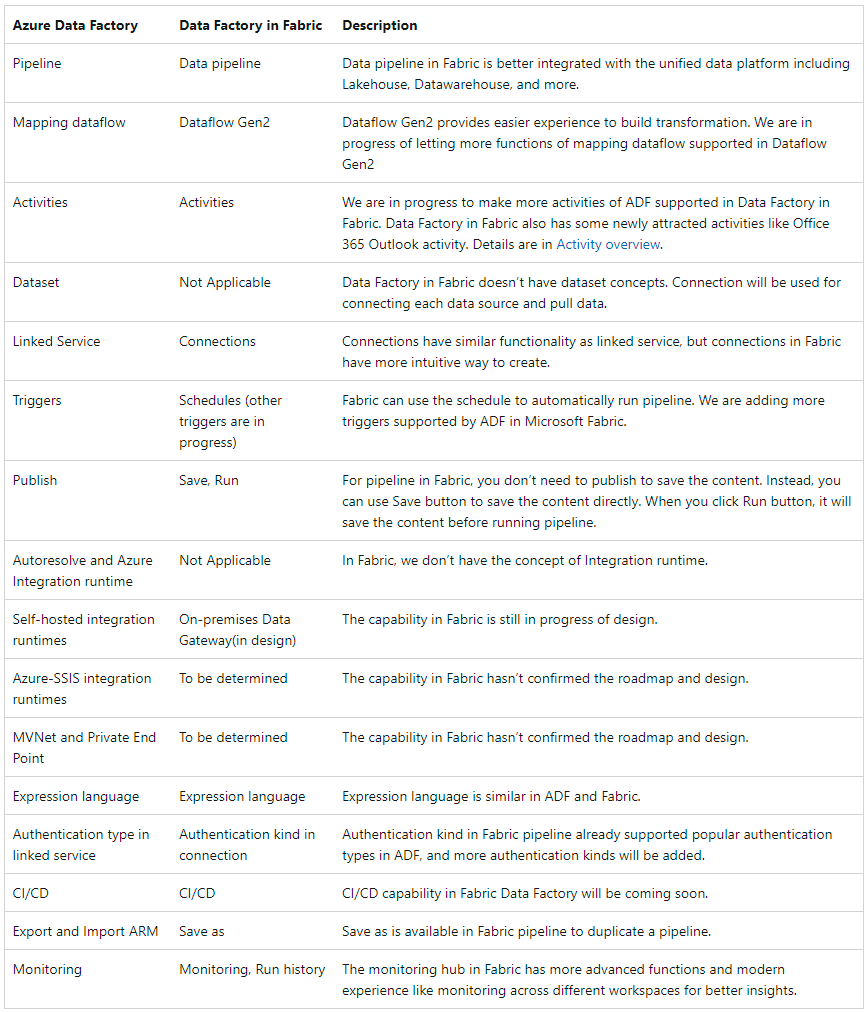
Overall, it confirms that Data Factory is an enhanced version of Azure Data Factory, with the benefit of having dataflows integrated within it. The pipelines are now integrated with the unified data platform, the monitoring hub has more advanced features, connections have replaced linked services and are more intuitive, and Microsoft has promised that functionality such as CI/CD and self-hosted integration runtimes are in progress.
Final thoughts
Data Factory combines the best features from two established products and improves them, providing users with a powerful data integration component of the Fabric suite. It offers tonnes of data connectivity, has a modernised feel, and brings some great new features. As a frequent user of Azure Data Factory, it matches up well and I’m interested to see how it may fit into the Adatis framework in the future!
I hope this has been a useful introduction. Thanks for reading.
Introduction to Data Wrangler in Microsoft Fabric
What is Data Wrangler? A key selling point of Microsoft Fabric is the Data Science
Jul
Autogen Power BI Model in Tabular Editor
In the realm of business intelligence, Power BI has emerged as a powerful tool for
Jul
Microsoft Healthcare Accelerator for Fabric
Microsoft released the Healthcare Data Solutions in Microsoft Fabric in Q1 2024. It was introduced
Jul
Unlock the Power of Colour: Make Your Power BI Reports Pop
Colour is a powerful visual tool that can enhance the appeal and readability of your
Jul
Python vs. PySpark: Navigating Data Analytics in Databricks – Part 2
Part 2: Exploring Advanced Functionalities in Databricks Welcome back to our Databricks journey! In this
May
GPT-4 with Vision vs Custom Vision in Anomaly Detection
Businesses today are generating data at an unprecedented rate. Automated processing of data is essential
May
Exploring DALL·E Capabilities
What is DALL·E? DALL·E is text-to-image generation system developed by OpenAI using deep learning methodologies.
May
Using Copilot Studio to Develop a HR Policy Bot
The next addition to Microsoft’s generative AI and large language model tools is Microsoft Copilot
Apr