This blog will demonstrate the use of cluster-scoped initialisation scripts for Azure Databricks. An example will run through how to configure an initialisation script to install libraries on to a cluster that are not included in the Azure Databricks runtime environment. It will cover how to do this firstly using the Databricks UI, followed by how to include it in your CI/CD solutions.
What is a cluster initialisation script?
A cluster node initialisation script is a shell script that runs during the start-up of each cluster before the Apache Spark driver or worker nodes start.
Azure Databricks supports two kinds of init scripts:
- Cluster-scoped: runs on every cluster that the initialisation script is configured for. This is the recommended way by Microsoft to run an init script and will be the focus of this blog post.
- Global: runs on every cluster in the workspace. You may want to use this to standardise some configurations across the workspace. However, Microsoft warns that these should be used carefully since they can have unanticipated impacts, like library conflicts (Cluster node initialization scripts – Azure Databricks | Microsoft Docs)
Use-Cases
A common use case for cluster-scoped init scripts is to install packages and libraries not included in the Databricks Runtime environment.
In Databricks runtime 7.1 and above, you can run the %pip magic command within a notebook to install libraries supported by pip. However, using cluster scoped init scripts ensures these libraries by default are available for all notebooks across the workspace that are attached to the cluster.
Also, an init script will be needed to install custom packages not available via pip. This blog will run through an example of doing this.
More advanced use cases include the ability to modify the JVM system classpath and set properties and environment variables used by the JVM, which can even reference secrets (Secrets – Azure Databricks | Microsoft Docs).
Worked Example:
For a client, it was necessary to parse a password-protected excel workbook into a dataframe within Databricks. To do this, an initialisation script was used to install a custom library provided by elastacloud on to a cluster, which can be found here: (elastacloud/spark-excel (github.com)).
The first step is to navigate to the releases and download the jar file locally, I was using spark_excel_3_2_1_0_1_8.jar.
The following steps are outlined as followed:
1) Save the local jar file in the Databricks File System (DBFS).
2) Create a script and save it in the DBFS root, accessible by the cluster.
It is important to note that Azure Databricks does not support storing these scripts in a mounted object store.
3) Configure the cluster to reference this script in its initialisation scripts
I will outline how to do this first by using the Databricks UI, followed by doing this programmatically for use in CI/CD processes.
Using the UI
- To browse the DBFS file system interactively rather than through the shell it is necessary to navigate to the Admin Console (you must be an Azure Databricks administrator to access the Admin Console) and enable the ‘DBFS File Browser’ option.
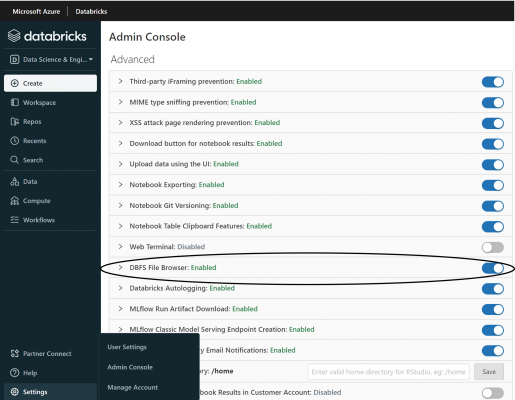
After enabling this, you can browse the DBFS by navigating to the Data tab and selecting DBFS. From there, choose a location to upload the locally installed jar file and make a note of this location.
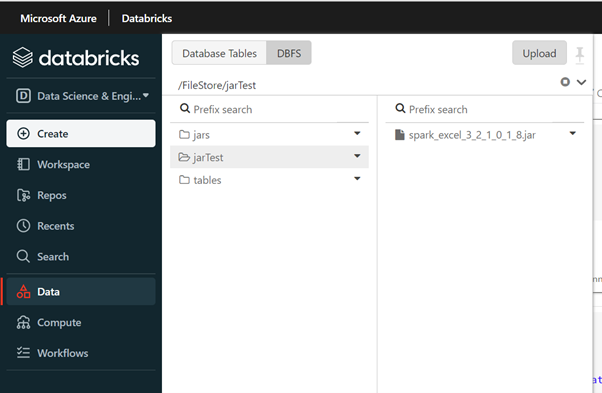
2. Creating the script:
To install jar files on the cluster, the initialisation script must copy the jar file saved in the DBFS to /databricks/jars/ (install jar file in dbfs and mvn packages)
So, create a file named installSparkExcel.sh using a text editor:
#!/bin/bash cp /dbfs/FileStore/jarTest/spark_excel_3_2_1_0_1_8.jar /databricks/jars/
The first location is the location of the uploaded the jar file from the previous step.
#!/bin/bash is a shebang in Unix, which tells the operating system to use Bash as the default shell to run the script (Shell Scripting – Define #!/bin/bash – GeeksforGeeks).
This script must then be uploaded to a DBFS location which the cluster can access.
Again, this can be achieved using the DBFS explorer. I saved the script in: /databricks/scripts/ :
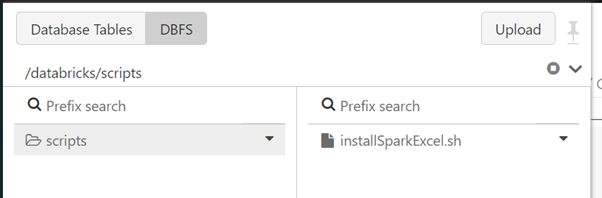
3. The final step is to configure the cluster to reference this script in its initialisation scripts.
- Navigate to the cluster through the compute tab and select the cluster you want the library to be installed on.
- On the top right, click ‘Edit’, which will allow you to edit the configuration of the cluster.
- Expand the ‘advanced options’ section.
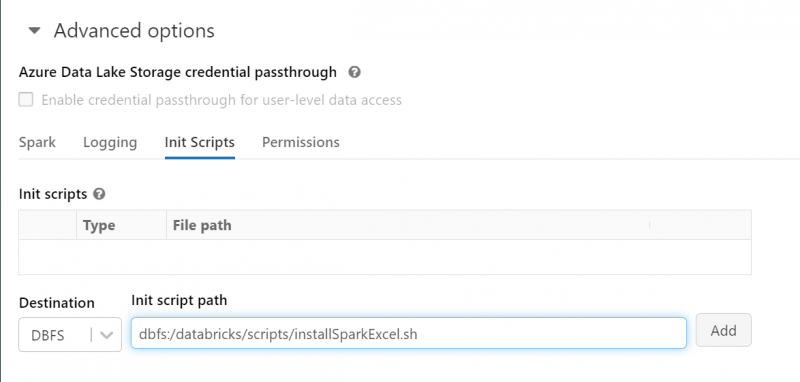
Here, you can add initialisation script paths to reference the script you uploaded in the previous step.
Upon restarting the cluster, the library will be installed and be available across notebooks that are attached to the cluster!
Programmatically
Instead of using the UI to achieve this, you can achieve this programmatically and make use of it in deployments.
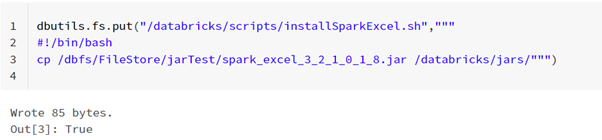
To achieve step 2, you can use Databricks Utilities to upload the same script to the DBFS in one step:
Step 3:
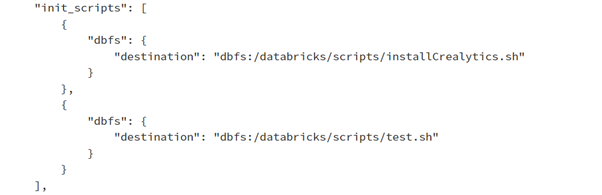
If making use of tools to automate the deployment of Databricks and their clusters, you can modify the JSON configuration file for the cluster to include the initialisation script.
To see what this would look like navigate to the cluster and the JSON output:
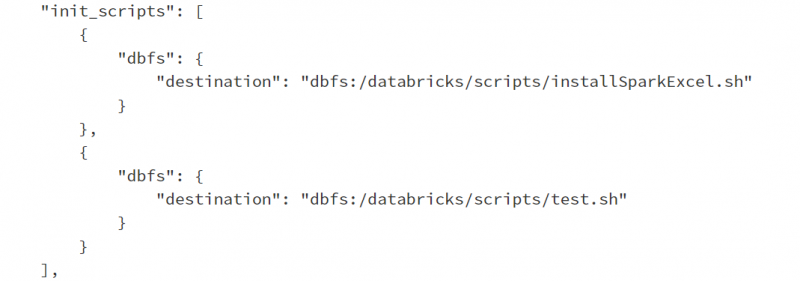
Rather than an empty array, the “init_scripts” will reference the locations of the scripts. Above, I have added another script called test.sh to demonstrate that multiple scripts can be referenced.
Deploying files to the DBFS:
In this example, uploading the jar file in step 1 and uploading the script to DBFS using the DBFS explorer when using the UI or dbutils in step 2 required some manual intervention.
This step can be incorporated in CICD solutions through the use of the 3rd party provider Data Thirst, using azure.databricks.cicd.tools, which provides PowerShell tools for deploying and managing Databricks solutions in Azure.
Specifically, you can use the ‘Add DatabricksDBFS’ task to upload files contained within your solution to the DBFS (Add DatabricksDBFSFile · DataThirstLtd/azure.databricks.cicd.tools Wiki (github.com)).This way, the jar file containing the library and the initialisation script can be uploaded to the DBFS as part of the deployment of Databricks.
Final Comments
This blog followed a specific example of using a locally downloaded jar file to install a library on a cluster, but the general steps can be followed for similar use cases.
Often it will not be necessary to have the jar installed onto the DBFS, as tools such as maven can be used in the initialisation scripts to reference specific libraries directly.
Feel free to leave any questions or comments and reach out to me on LinkedIn.








I am constantly searching online for tips that can help me. Thank you!