Real-time stream processing is becoming more prevalent on modern day data platforms, and with a myriad of processing technologies out there, where do you begin? Stream processing involves the consumption of messages from either queue/files, doing some processing in the middle (querying, filtering, aggregation) and then forwarding the result to a sink – all with a minimal latency. This is in direct contrast to batch processing which usually occurs on an hourly or daily basis. Often is this the case, both of these will need to be combined to create a new data set.
In terms of options for real-time stream processing on Azure you have the following:
- Azure Stream Analytics
- Spark Streaming / Storm on HDInsight
- Spark Streaming on Databricks
- Azure Functions
Stream Analytics is a simple PaaS offering. It connects easily into other Azure resources such as Event Hubs, IoT Hub, and Blob, and outputs to a range of resources that you’d expect. It has its own intuitive query language, with the added benefit of letting you create functions in JavaScript. Scaling can be achieved by partitions, and it has windowing and late arrival event support that you’d expect from a processing option. For most jobs, this service will be the quickest/easiest to implement as long as its relatively small amount of limitations fall outside the bounds of what you want to achieve. Its also worth noting that the service does not currently support Azure network security such as Virtual Networks or IP Filtering. I suspect this may only be time with the Preview of this in EventHubs.
Both Spark Streaming on HDInsight and Databricks open up the options for configurability and are possibly more suited to an enterprise level data platform, allowing us to use languages such as Scala/Python or even Java for the processing in the middle. The use of these options also allows us to integrate Kafka (an open source alternative to EventHubs) as well as HDFS, and Data Lake as inputs. Scalability is determined by the cluster sizes and the support for other events mentioned above is also included. These options also give us the flexibility for the future, and allow us to adapt moving forward depending on evolving technologies. They also come with the benefit of Azure network security support so we can peer our clusters onto a virtual network.
Lastly – I wouldn’t personally use this but we can also use Functions to achieve the same goal through C#/Node.js. This route however does not include support for those temporal/windowing/late arrival events since functions are serverless and act on a per execution basis.
In the following blog, I’ll be looking at Spark Streaming on Databricks (which is fast becoming my favourite research topic).
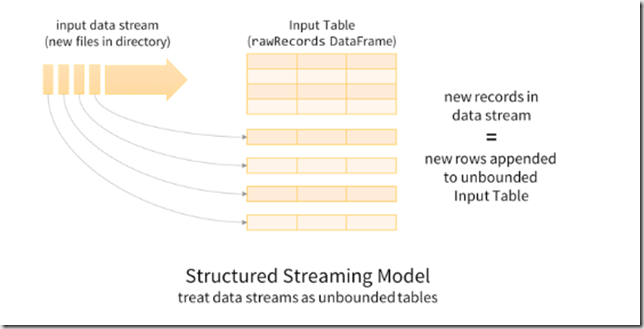
A good place to start this is to understand the structured streaming model which I’ve seen a documented a few times now. Essentially treating the stream as an unbounded table, with new records from the stream being appended as a new rows to the table. This allows us to treat both batch and streaming data as tables in a DataFrame, therefore allowing similar queries to be run across them.

At this point, it will be useful to include some code to help explain the process. Before beginning its worth mounting your data sink to your databricks instance so you can reference it as if it were inside the DBFS (Databricks File System) – this is merely a pointer. For more info on this, refer to the databricks documentation here. Only create a mount point if you want all users in the workspace to have access. If you wish to apply security, you will need to access the store directly (also documented in the same place) and then apply permissions to the notebook accordingly.
As my input for my stream was from EventHubs, we can start by defining the reading stream. You’ll firstly need to add the maven coordinate com.microsoft.azure:azure-eventhubs-spark_2.11:2.3.2 to add the EventHub library to the cluster to allow the connection. Further options can be added for the consumer group, starting positions (for partitioning), timeouts and events per trigger. Positions can also be used to define starting and ending points in time so that the stream is not running continuously.
connectionString = "Endpoint=sb://{EVENTHUBNAMESPACE}.servicebus.windows.net/{EVENTHUBNAME};EntityPath={EVENTHUBNAME};SharedAccessKeyName={ACCESSKEYNAME};SharedAccessKey={ACCESSKEY}" startingEventPosition = { "offset": "-1", # start of stream "seqNo": -1, # not in use "enqueuedTime": None, # not in use "isInclusive": True } endingEventPosition = { "offset": None, # not in use "seqNo": -1, # not in use "enqueuedTime": dt.now().strftime("%Y-%m-%dT%H:%M:%S.%fZ"), # point in time "isInclusive": True } ehConf = {} ehConf['eventhubs.connectionString'] = connectionString ehConf['eventhubs.startingPosition'] = json.dumps(startingEventPosition) ehConf['eventhubs.endingPosition'] = json.dumps(endingEventPosition) df = spark .readStream .format("eventhubs") .options(**ehConf) .load()
The streaming data that is then output then follows the following schema – the body followed by a series of metadata about the streaming message.

Its important to note that the body comes out as a binary stream (this contains our message). We will need to cast the body to a String to deserialize the column to the JSON that we are expecting. This can be done by using some Spark SQL to turn the binary into a string as JSON and then parsing the column into a StructType with specified schema. If multiple records are coming through in the same message, you will need to explode out the result into separate records. Flattening out the nested columns is also useful as long as the data frame is still manageable. Spark SQL provides some great functions here to make our life easy.
rawData = df. selectExpr("cast(body as string) as json"). select(from_json("json", Schema).alias("data")). select("data.*")
While its entirely possible to construct your schema manually, its also worth noting that you can take a sample JSON, read it into a data frame using spark.read.json(path) and then calling printSchema() on top of it to return the inferred schema. This can then used be used to create the StructType.
# Inferred schema: # root # |-- LineTotal: string (nullable = true) # |-- OrderQty: string (nullable = true) # |-- ProductID: string (nullable = true) # |-- SalesOrderDetailID: string (nullable = true) # |-- SalesOrderID: string (nullable = true) # |-- UnitPrice: string (nullable = true) # |-- UnitPriceDiscount: string (nullable = true) Schema = StructType([ StructField('SalesOrderID', StringType(), False), StructField('SalesOrderDetailID', StringType(), False), StructField('OrderQty', StringType(), False), StructField('ProductID', StringType(), False), StructField('UnitPrice', StringType(), False), StructField('UnitPriceDiscount', StringType(), False), StructField('LineTotal', StringType(), False) ])
At this point, you have the data streaming into your data frame. To output to the console you can use display(rawData) to see the data visually. However this is only useful for debugging since the data is not actually going anywhere! To write the stream into somewhere such as data lake you would then use the following code. The checkpoint location can be used to recover from failures when the stream is interrupted, and this is important if this code were to make it to a production environment. Should a cluster fail, the query be restarted on a new cluster from a specific point and consistently recover, thus enabling exactly-once guarantees. This also means we can change the query as long as the input source and output schema are the same, and not directly interrupt the stream. Lastly, the trigger will check for new rows in to stream every 10 seconds.
rawData.writeStream .format("json") .outputMode("append") .option("path", PATH) .trigger(processingTime = "10 seconds") .option("checkpointLocation", PATH) .start()
Checking our data lake, you can now see the data has made its way over, broken up by the time intervals specified.

Hopefully this is useful for anyone getting going in the topic area. I’d advise to stick to Python given the extra capacity of the PySpark language over Scala, even though a lot of the Databricks documentation / tutorials uses Scala. This was just something that felt more comfortable.
If you intend to do much in this area I would definitely suggest you use the PySpark SQL documentation which can be found here. This is pretty much a bible for all commands and I’ve been referencing it quite a bit. If this is not enough there is also a cheat sheet available here. Again, very useful for reference when the language is still not engrained.
Introduction to Data Wrangler in Microsoft Fabric
What is Data Wrangler? A key selling point of Microsoft Fabric is the Data Science
Jul
Autogen Power BI Model in Tabular Editor
In the realm of business intelligence, Power BI has emerged as a powerful tool for
Jul
Microsoft Healthcare Accelerator for Fabric
Microsoft released the Healthcare Data Solutions in Microsoft Fabric in Q1 2024. It was introduced
Jul
Unlock the Power of Colour: Make Your Power BI Reports Pop
Colour is a powerful visual tool that can enhance the appeal and readability of your
Jul
Python vs. PySpark: Navigating Data Analytics in Databricks – Part 2
Part 2: Exploring Advanced Functionalities in Databricks Welcome back to our Databricks journey! In this
May
GPT-4 with Vision vs Custom Vision in Anomaly Detection
Businesses today are generating data at an unprecedented rate. Automated processing of data is essential
May
Exploring DALL·E Capabilities
What is DALL·E? DALL·E is text-to-image generation system developed by OpenAI using deep learning methodologies.
May
Using Copilot Studio to Develop a HR Policy Bot
The next addition to Microsoft’s generative AI and large language model tools is Microsoft Copilot
Apr