We’ve discussed what Azure SQLDW actually is, so we know it works on scalable MPP technology. But what does that actually mean?
If you’re happy with the idea that MPP aligns compute with storage then read on. If not, have a quick skim of my blog here.
Ok, so we’re using MPP, we have storage and we apply compute to it. In SQLDW, the magic number is 60. There are always sixty distributions. Whenever you write a record to a table, it will always be written to one of those 60 distributions.
You can think of those distributions however you like – as individual buckets of data, as isolated SQL databases, as magic data-shelves in the sky – as long as you know that there are always sixty, regardless of scale, tier, price, country or any other factor. That’s a major difference from the APS/PDW systems that SQLDW evolved from – they would change the number of distributions as you scales. However in order to get the dynamic scaling that cloud technologies rely on, they couldn’t have data being redistributed every time you scale up or down. So distributions are fixed, permanently, at 60.
You scale the system by adding/removing compute to work against these 60 distributions.
IMPORTANT: When you scale SQLDW, you will kill all running transactions. Scaling effectively restarts the server
How to Scale SQLDW
There are several different ways of scaling SQLDW, these are:
- Through the Azure Portal
- Via T-SQL
- Via PowerShell
The portal is the only one that informs you of the cost when you scale. You should be aware that you will be charged per hour – so if you turn it up for 5 minutes then back down, you’ll still be charged for the remainder of the hour.
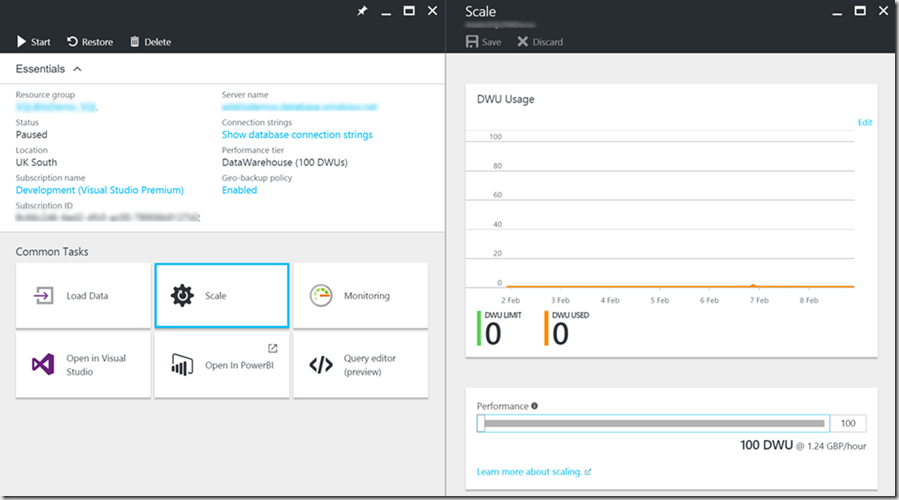
Firstly, the portal. This is the easiest when you’re first getting started, however cannot be automated and is very manual.
To do so, navigate to your SQLDW blade, click on the “Scale” button. When you select your chosen DWU level, it will tell you how much this amount of compute will cost per hour.

Next, there’s the SQL route. Really easy, simply issue an alter statement command against your database and it’ll update the “Service Objective”, which for SQLDW is the DWU.
Note that this will NOT work if you run it against the SQLDW directly. Like other Platform-as-a-Service databases (aka: Azure SQL DB), the server it is allocated to will have a master database, used to control database-level metadata and security settings.
You need to connect directly to the master database to issue a T-SQL scaling command – this isn’t always possible with production systems but it’s worth bearing in mind as a potential method.
ALTER DATABASE [DBNAME] MODIFY (SERVICE_OBJECTIVE = 'DW1000');
Finally there’s PowerShell – either via the Azure Powershell IDE or through an Azure Automation Account – which essentially provides a Platform-as-a-Service Powershell node.
There are a couple of cmdlets available – these are pre-built Powershell functions you can pass parameters to in order to perform standard tasks.
There are three standard cmdlets I would use, these are:
Set-AzureRmSqlDatabase -DatabaseName “Database" -ServerName “Server" -RequestedServiceObjectiveName "DW1000"
This is the same as the cmdlet used to change the service objective of Azure SQLDBs. Simply select your database & server and provide the required DWU level to move to.
The next two are interesting – you can entirely pause the compute associated to your SQLDW. This allows you to save a lot of money in out-of-hours times, maybe turning things off in the evenings and weekends.
Suspend-AzureRmSqlDatabase –ResourceGroupName "ResourceGroup" –ServerName "Server" –DatabaseName "Database" Resume-AzureRmSqlDatabase –ResourceGroupName "ResourceGroup" –ServerName "Server" –DatabaseName "Database"
In each of these methods, the scaling will take anywhere from 30 seconds to 5 minutes. If you have long running transactions when you issue the scaling command, it will need to roll these back, in these scenarios the scaling action could take a long time!
What happens when you scale SQLDW?
When we change the number of DWUs (that’s data warehouse units, similar to the SQLDB concept of DTUs) – we’re actually just changing the number of distributions each compute node has to look after.
At 100 DWUs, a single compute node manages all storage:

At 200 DWUs, the number of distributions is only 30 per compute node. This is already a drastic difference in performance.

Again, at 300 DWUs, we add another compute node and associate it to storage. No data is moving but we now have less work for each compute node to do, therefore it completes faster.

That’s why we can keep scaling all the way to 6000 DWUs – at that point we are associating each distribution directly with a compute node – there’s a one-to-one mapping. We can’t scale any further than that as we would begin sharing storage between compute, and that’s the SMP problem we’re trying to avoid!
It might help to think of this in MPP terms – our 300 DWU example would look like this:

Hopefully that helps understand what’s happening when you hit that “Scale” button – we’ll be talking about distributing data next. If you haven’t distributed your data properly, the all the scaling won’t help you very much!
Introduction to Data Wrangler in Microsoft Fabric
What is Data Wrangler? A key selling point of Microsoft Fabric is the Data Science
Jul
Autogen Power BI Model in Tabular Editor
In the realm of business intelligence, Power BI has emerged as a powerful tool for
Jul
Microsoft Healthcare Accelerator for Fabric
Microsoft released the Healthcare Data Solutions in Microsoft Fabric in Q1 2024. It was introduced
Jul
Unlock the Power of Colour: Make Your Power BI Reports Pop
Colour is a powerful visual tool that can enhance the appeal and readability of your
Jul
Python vs. PySpark: Navigating Data Analytics in Databricks – Part 2
Part 2: Exploring Advanced Functionalities in Databricks Welcome back to our Databricks journey! In this
May
GPT-4 with Vision vs Custom Vision in Anomaly Detection
Businesses today are generating data at an unprecedented rate. Automated processing of data is essential
May
Exploring DALL·E Capabilities
What is DALL·E? DALL·E is text-to-image generation system developed by OpenAI using deep learning methodologies.
May
Using Copilot Studio to Develop a HR Policy Bot
The next addition to Microsoft’s generative AI and large language model tools is Microsoft Copilot
Apr