We’ve spoken about the MPP nature of SQLDW, and how it scales by changing the number of compute nodes associated to a fixed number of storage distributions. But the way that you organise data across these distributions can drastically change how the system performs – if it’s done badly, one of your compute nodes will be doing all the work and your performance will be very poor.
For now, there are two main methods of distribution. We can focus on spreading data evenly across all distributions to ensure we get predictable performance or we can distribute on a specific column to optimise for specific query performance. These distribution types are known as ROUND ROBIN and HASH distributions respectively.
Round Robin Distribution
Each record that is inserted goes onto the next available distribution. This guarantees that you will have a smooth, even distribution of data, but it means you have no way of telling which data is on which distribution. This isn’t always a problem!
If I wanted to perform a count of records, grouped by a particular field, I can perform this on a round-robin table. Each distribution will run the query in parallel and return it’s grouped results. The results can be simply added together as a second part of the query, and adding together 60 smaller datasets shouldn’t be a large overhead. For this kind of single-table aggregation, round-robin distribution is perfectly adequate!
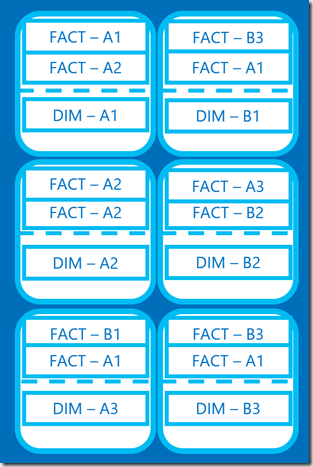
However, the issues arise when we have multiple tables in our query. In order to join two tables. Let’s take a very simple join between a fact table and a dimension. I’ve shown 6 distributions for simplicity, but this would be happening across all 60.
![clip_image001[4]](https://adatis.co.uk/wp-content/uploads/historic/simonwhiteley_clip_image0014.png "clip_image001[4]")
In this case, both tables have been distributed using ROUND ROBIN. There are an even number of records on each distribution, however there is no consistency where records are stored. There are multiple fact records for “A1” but they are held on different distributions.
If I run a simple select statement joining the two tables, each distribution needs to be able to run the query in isolation. Taking the first distribution, we have records with foreign keys for A1 & A2 on the fact, and only records for A1 on the dimension. But more than that – the server doesn’t KNOW which records it has.
In order to execute this query, a thing called data movement happens, which would essentially take a full copy of the dimension table and copy it to all other distributions. At this point, each distribution knows it has all records needed in order to execute the query.
![clip_image002[4]](https://adatis.co.uk/wp-content/uploads/historic/simonwhiteley_clip_image0024.png "clip_image002[4]")
This happens at query runtime. So when you’re user is trying to get the results of a select statement, they have to wait while the system reorganises data. This is done for the specific query and dropped after execution – so it’ll happen every time the query is run.
Basically – data movement is bad. It’s not disastrous, it’s unavoidable in many queries, but it’s something you should have in mind whenever designing your distributions.
HASH Distribution
This is the alternative – designing our distributions on a specific key. When a record is inserted, a HASH is created on the column name and value, and it is allocated to a distribution. Then, if another record comes in that has the same value for that column, it will be co-located in that same distribution. This is true across tables – so if two tables are distributed on the same column, the related records will be stored on the same distribution.
Let’s take a look at our fact and dimensions, assuming they were distributed on the foreign key:
![clip_image003[4]](https://adatis.co.uk/wp-content/uploads/historic/simonwhiteley_clip_image0034.png "clip_image003[4]")
You can immediately see two things – firstly, all records relating to A1 are on the same distribution as the A1 dimension records, same for B1, B2 etc. Secondly, there is obvious skew – there are more A1 records than on any other distribution! This means that the distribution with the A1 records on with be slower to finish it’s query than the others.
This is a tiny example – two extra records makes very little difference, but when we’re dealing with hundreds of millions of records, this skew can become significant. SQLDW can only return queries once all distributions have finished executing, meaning the whole query is only as fast as your slowest distribution.
However, when we execute our query this time, let’s look at our A1 distribution:
![clip_image004[4]](https://adatis.co.uk/wp-content/uploads/historic/simonwhiteley_clip_image0044.png "clip_image004[4]")
We now know which records this distribution holds for both tables, we also know that this distribution can execute the query without the need for data from other distributions. The query can therefore execute immediately with no data movement steps taking place – we have effectively eliminated a whole step from the query.
Replicated Distribution
In APS/PDW world, there is a third distribution type – REPLICATED. This would create a full copy of the table on all distributions, eliminating the need for many types of data movement. At the time of writing, this is being worked on but has not yet been released, even within preview.
Picking a Distribution key
Based on that knowledge, we’re after the following factors for a good distribution:
- Distinct Values – We need at least 60 unique values – but more than this, we want LOTS more. More than 600 at least, would be preferable. If we have fewer than 60 values, we would not be using all distributions and essentially wasting potential performance!
- Even Distribution – We want the values to be evenly spread. If one of our distribution keys has 10 records with that key, but another has 1000, that’s going to cause a lot of discrepancy in distribution performance.
- Commonly Used in Table Joins – Next, the biggest reason for data movement to happen is where joins are occurring. Look at the queries your users are going to be issuing commonly, the keys used in those joins are going to be candidates for distribution.
- Not Commonly Filtered – Finally, if users commonly use your distribution key as a search predicate, this is going to drastically reduce any parallelism. If it happens now and then, it’s not terrible – but if it affects the bulk of queries then it’s going to be a real performance drain.
That’s probably the hardest part of designing an Azure SQL Datawarehouse – a lot of the performance and design comes down to knowing how your users will query the system, and this is rarely something we know in advance! Luckily, it’s fairly easy to change distributions, we’ll come on to that in future posts.
Introduction to Data Wrangler in Microsoft Fabric
What is Data Wrangler? A key selling point of Microsoft Fabric is the Data Science
Jul
Autogen Power BI Model in Tabular Editor
In the realm of business intelligence, Power BI has emerged as a powerful tool for
Jul
Microsoft Healthcare Accelerator for Fabric
Microsoft released the Healthcare Data Solutions in Microsoft Fabric in Q1 2024. It was introduced
Jul
Unlock the Power of Colour: Make Your Power BI Reports Pop
Colour is a powerful visual tool that can enhance the appeal and readability of your
Jul
Python vs. PySpark: Navigating Data Analytics in Databricks – Part 2
Part 2: Exploring Advanced Functionalities in Databricks Welcome back to our Databricks journey! In this
May
GPT-4 with Vision vs Custom Vision in Anomaly Detection
Businesses today are generating data at an unprecedented rate. Automated processing of data is essential
May
Exploring DALL·E Capabilities
What is DALL·E? DALL·E is text-to-image generation system developed by OpenAI using deep learning methodologies.
May
Using Copilot Studio to Develop a HR Policy Bot
The next addition to Microsoft’s generative AI and large language model tools is Microsoft Copilot
Apr