In my previous blog I looked how we can utilise pipeline parameters to variablise certain aspects of a dataset to avoid duplication of work. In this blog I will take that one step further and use parameters to feed into a For Each activity that can iterate over a data object and perform an action for each item. This blog assumes some prior knowledge of Azure Data Factory and it won’t hurt to read my previous blog
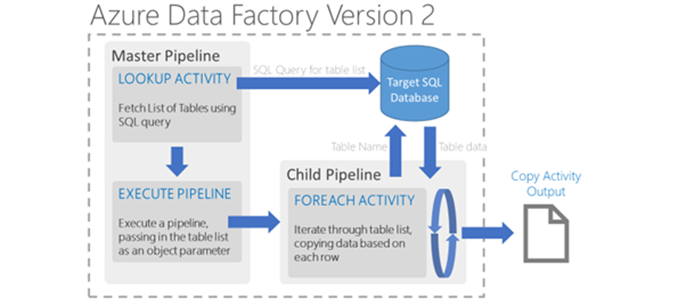
Previously I showed how to use a parameter file to copy a single table from Azure SQL DB down into a blob. Now lets use the For Each activity to fetch every table in the database from a single pipeline run. The benefit of doing this is that we don’t have to create any more linked services of data sets, we are only going to create one more pipeline that will contain the loop. The big picture here looks like below.

The first activity to note is the lookup activity. This can go off and fetch a value from either SQL or JSON based sources and then incorporate that value into activities further down the chain.

Here we are using SQL and you can see that we have supplied a SQL query that will fetch the schema and table names of our database. One “gotcha” is that even though you supply a SQL query, you still need to provide a dummy table name in the SQL dataset. It will use the query above at run time but won’t pass deployment without a table name. Also note that at this point, we do nothing with the returned value.
Next, we have the Execute Pipeline activity which can accept input parameters and pass those down into the executed pipelines (or child pipelines as per the diagram).

Within the type properties we can specify the parameters we want to pass in. The names here need to match whatever parameters we specify in the child pipeline but for the “value” we can make use of the new expression language to get a hold of the output of the previous lookup activity. We then reference the pipeline we want to execute, and that we need to wait for it to complete before continuing with our parent pipeline. Finally, we use the “dependsOn” attribute to ensure that our Execute Pipeline activity occurs AFTER our lookup has completed successfully.
At this point we have told the child pipeline which tables to copy and then told it to start. Our child pipeline now just needs to iterate over that list and produce our output files. To do this it only needs one activity which is the For Each. The For Each really has two components which are the outer configurables (such as the items to iterate over) and then the inner activity to perform on each item. The outer section looks like this:

Here we can configure the “isSequential” property which when set to “false” allows Data Factory to parallelise the inner activity, otherwise it will run each activity one after another. The other property is the “items” which is what the activity will iterate through. Because we fed the table list in to the “tableList” parameter from the Execute Pipeline activity we can specify that as our list of items.
Now for the inner activity:

Whilst this is a fairly chunky bit of JSON, those familiar with the copy activity in ADF V1 will probably feel pretty comfortable with this. The key difference is that we are again making use of expressions and parameters to make our template generic. You can see in the “output” attribute we are dynamically specifying the output blob name by using the schema and table name properties gleaned from our input data set. Also, in the source attribute we dynamically build our SQL query to select all the data from the table that we are currently on using the @item() property. This method of combing text and parameters is called string interpolation and allows us to easily mix static and dynamic content without the needed for additional functions or syntax.
That’s it! By making use of only a few extra activities we can really easily do tasks that would have taken much longer in previous versions of ADF. You can find the full collection of JSON objects using this link: http://bit.ly/2zwZFLB. Watch this space for the next blog which will look at custom logging of data factory activities!
Introduction to Data Wrangler in Microsoft Fabric
What is Data Wrangler? A key selling point of Microsoft Fabric is the Data Science
Jul
Autogen Power BI Model in Tabular Editor
In the realm of business intelligence, Power BI has emerged as a powerful tool for
Jul
Microsoft Healthcare Accelerator for Fabric
Microsoft released the Healthcare Data Solutions in Microsoft Fabric in Q1 2024. It was introduced
Jul
Unlock the Power of Colour: Make Your Power BI Reports Pop
Colour is a powerful visual tool that can enhance the appeal and readability of your
Jul
Python vs. PySpark: Navigating Data Analytics in Databricks – Part 2
Part 2: Exploring Advanced Functionalities in Databricks Welcome back to our Databricks journey! In this
May
GPT-4 with Vision vs Custom Vision in Anomaly Detection
Businesses today are generating data at an unprecedented rate. Automated processing of data is essential
May
Exploring DALL·E Capabilities
What is DALL·E? DALL·E is text-to-image generation system developed by OpenAI using deep learning methodologies.
May
Using Copilot Studio to Develop a HR Policy Bot
The next addition to Microsoft’s generative AI and large language model tools is Microsoft Copilot
Apr