
What are Serverless SQL Pools?
Serverless SQL Pools or SQL on-demand is a serverless distributed data processing service offered by Microsoft. The service is comparable to Amazon Athena. The serverless nature of the service means that there is no infrastructure to manage, and you only pay for what you use (pay-per-query model).
Through Serverless SQL pools, you query the data in your data lake using T-SQL. The architecture behind the service is optimized for querying and analyzing big data by running queries in parallel.
Where do Serverless SQL Pools fit within a modern data platform?
The benefits of Serverless SQL Pools are well documented. These benefits are quickly realised when small and medium sized business (SMBs) use them to migrate some of their data warehouse workloads from on-prem to the cloud. The below image (courtesy of Microsoft docs) shows
several ways that SMBs can modernize legacy data stores and explore big data tools and capabilities, without overextending current budgets and skillsets.

Focusing on the Serverless Analysis scenario, we’ll take a deep dive into a worked example and see a “Hello World” implementation of Serverless SQL Pools.
Worked Example
We’ll create a very basic logical data warehouse using a small AdventureWorks data set, we’ll perform a few transformations and then create a model for reporting. You can access the scripts here.
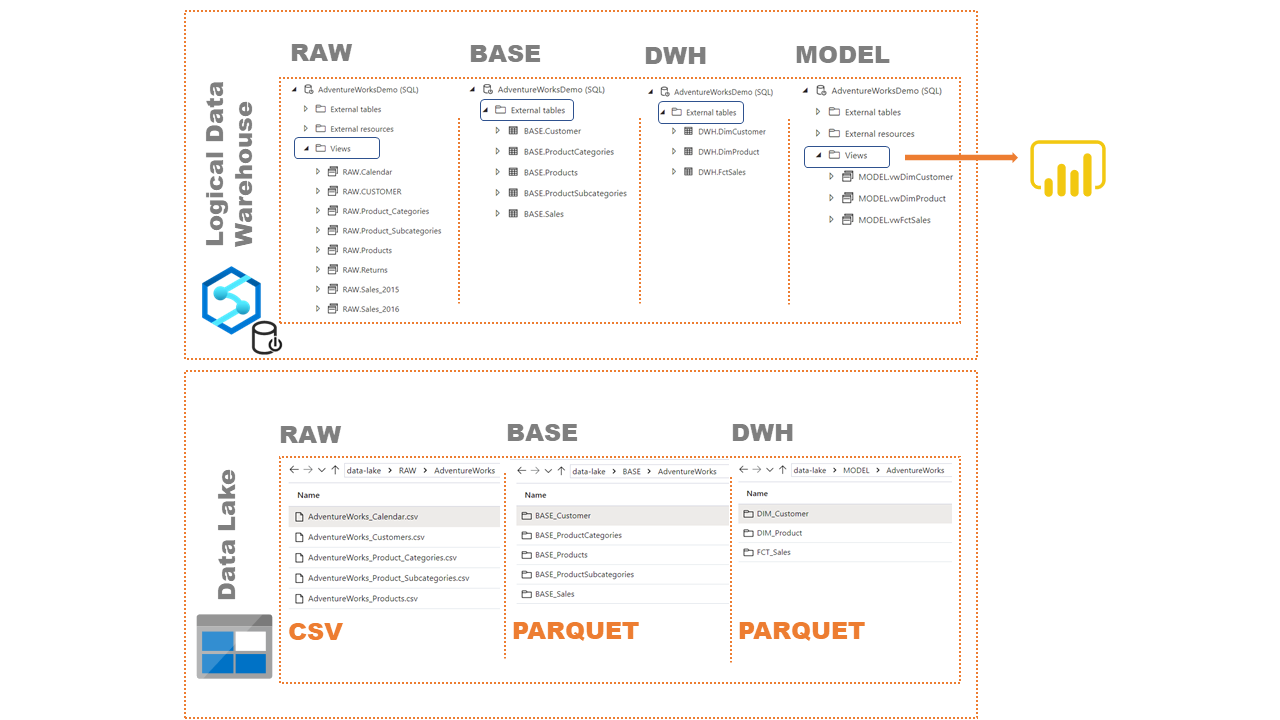
Logical Data Warehouse (LDW)
This provides us with an abstraction layer over our Data Lake – where our data resides. Instructions on how to create a logic data warehouse within your Synapse workspace can be found here.
- RAW – the data is an exact replica of the source data (csv), hence the use of views.
- BASE – we cleanse the data and transform the files to parquet for optimization. The data is created as an External Table using CETAS. This creates a new folder within the data lake which we query through External Tables.
- DWH – We create our Fact and Dimensions from our BASE Tables using Stored Procedures (which are supported in Serverless Pools. However, the Synapse Analytics UI doesn’t currently reflect this. Instead you can view the stored procedures in SSMS)
- MODEL – We create views of our Fact and Dimensions. We serve them to Power BI and other analytics tools for reporting.
Data Lake
The Data Lake has been created with 3 layers
- RAW – this is the landing area of the ingested source data.
- BASE – we persist our cleansed data in parquet format to utilize parquet’s compression & query optimization benefits, among others.
- DWH – we persist our Dimensions and Fact Tables after adding Surrogate Keys and Audit Details.
Worked Example Setup
DWH Layer
Taking a deeper dive into the DWH Layer, you’ll notice that the external tables were created using stored procedures. For example DimCustomer was created using the following;
CREATE PROCEDURE [DWH].[PopulateDimCustomer]
@LoadId int
AS
BEGIN
IF OBJECT_ID('[DWH].[DimCustomer]') IS NOT NULL
DROP EXTERNAL TABLE [DWH].[DimCustomer]
CREATE EXTERNAL TABLE [DWH].[DimCustomer]
WITH
(
LOCATION = 'MODEL/AdventureWorks/DIM_Customer',
DATA_SOURCE = ExternalDataSourceDataLake,
FILE_FORMAT = SynapseParquetFormat
)
AS
SELECT
CAST(ROW_NUMBER() OVER (ORDER BY [CustomerKey]) AS INT) AS [CustomerId],
ISNULL(CAST([CustomerKey] AS INT), -1) AS [CustomerKey],
ISNULL(CAST([Prefix] AS VARCHAR(5)), 'Unknown') AS [Prefix],
ISNULL(CAST([FirstName] AS VARCHAR(50)), 'Unknown') AS [FirstName],
ISNULL(CAST([LastName] AS VARCHAR(50)), 'Unknown') AS [LastName],
ISNULL(CAST([FullName] AS VARCHAR(100)), 'Unknown') AS [FullName],
ISNULL(CAST([MaritalStatus] AS VARCHAR(50)), 'Unknown') AS [MaritalStatus],
ISNULL(CAST([HomeOwner] AS VARCHAR(50)), 'Unknown') AS [HomeOwner],
ISNULL(CAST([Gender] AS VARCHAR(50)), 'Unknown') AS [Gender],
ISNULL(CAST([EmailAddress] AS VARCHAR(50)), 'Unknown') AS [EmailAddress],
ISNULL(CAST([AnnualIncome] AS VARCHAR(50)), 'Unknown') AS [AnnualIncome],
ISNULL(CAST([TotalChildren] AS INT), 0) AS [TotalChildren],
ISNULL(CAST([EducationLevel] AS VARCHAR(50)), 'Unknown') AS [EducationLevel],
ISNULL(CAST([Occupation] AS VARCHAR(50)), 'Unknown') AS [Occupation],
GETDATE() AS [LoadDate],
@LoadId AS [LoadId]
FROM [BASE].[Customer]
SELECT 0 'Output'
END
Using stored procedures is a great way to operationalize serverless SQL pools within your workspace. This is because you can pass in parameters from upstream activities amongst other things.
CETAS Gotcha
You’ll need to keep in mind that when you use CETAS, it creates physical data within the data lake. Should you run the same query again, you’ll get the error message “External Table Location already exists”.

Note that using the following T-SQL will only remove the external table reference within the Logical Data Warehouse, it doesn’t remove the underlying persisted data.
IF OBJECT_ID('[DWH].[DimCustomer]') IS NOT NULL
DROP EXTERNAL TABLE [DWH].[DimCustomer]
CETAS Workaround
To get around this you’ll have to use the delete activity to delete the persisted data within the data lake every time you want to populate your Dim and Fact Tables.
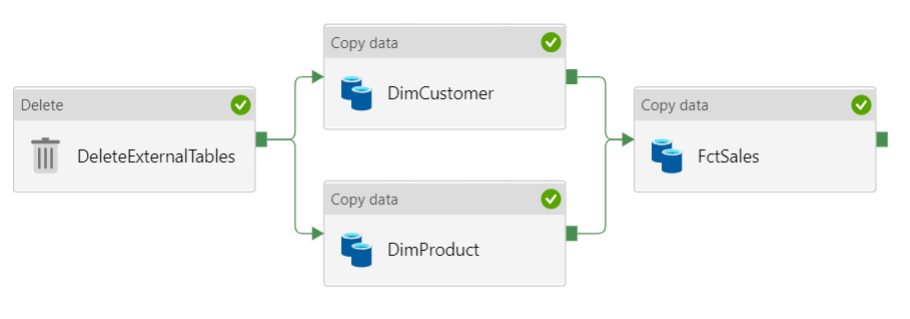
Although this workaround gives us the ability to re-run our stored procedure, it does mean that every time we want to populate the DWH it will always be a truncate and load. The above workaround doesn’t support incremental loads.
Incremental Loads
A major drawback of using SQL on demand, in its current form, is that there is no way to support incremental loads. Namely, retain a history of our data and append new data as and when it arrives.
The common practice of creating a temp table to store your historical data and then creating a union with a delta load isn’t supported. If there is support for this, it isn’t immediately obvious how this could be accomplished. Support for temp tables in Serverless SQL Pools is currently very limited
Avoiding the use of temp tables by creating transient external tables (persisting historical data in the data lake temporarily) doesn’t help either.
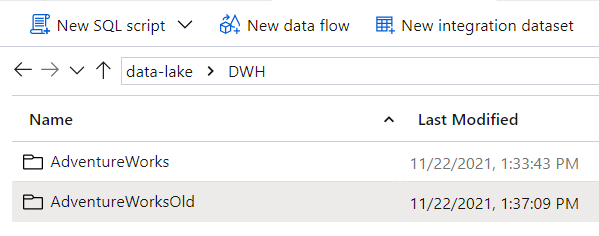
Creating a union between new data stored in the AdventureWorks folder and the historical data stored in the AdventureWorksOld folder results in the following error message.
The query references an object that is not supported in distributed processing mode
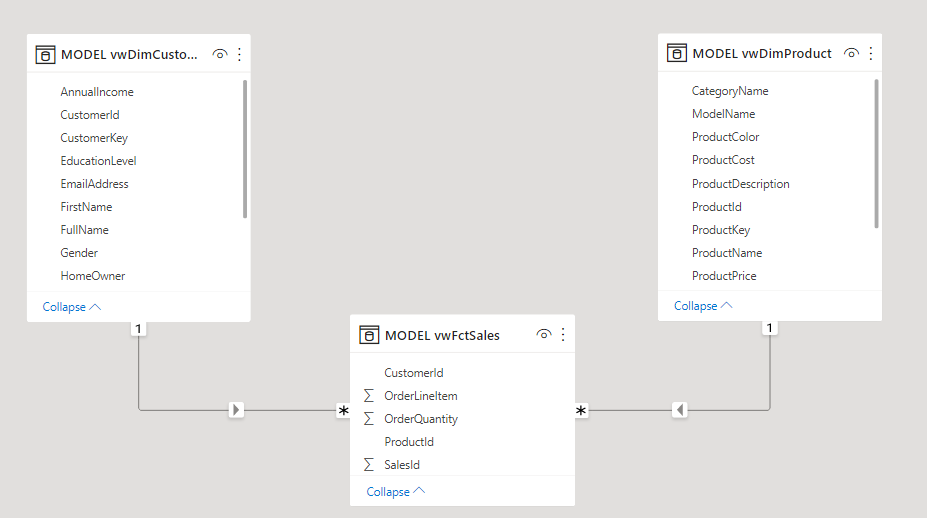
Visualization
The final step is to import our views into Power BI for reporting. Here’s our data model in Power BI.
Main Takeaways
- Serverless SQL Pools have a place within modern data architecture. Having gone through our worked example, we’ve seen how we can operationalize the service as part of a synapse pipeline to perform transformations on demand/on a schedule. We can further operationalize the process using metadata to drive the synapse pipelines.
- Serverless SQL Pools can have huge cost saving implications. The use of a logical data warehouse means that data stays within your data lake, you don’t incur the cost of moving data between different storage services. That said, we do incur a data movement cost when we move data within the data lake itself. Ultimately, we save money by using compute only when required. Useful Links: Pricing Information, Cost Management Information.
- Serverless SQL Pools require workarounds to utilise the service in a production environment. However, as we’ve seen, these workarounds are relatively straight forward and can be implemented without overextending current skillsets allowing SMBs to quickly realise benefits.
- The inability to support incremental loading patterns does mean that the service might not be best placed to run data warehousing workloads. It might be more suitable for ad-hoc or exploratory workloads. Until this is fully supported, Dedicated SQL Pools might be a better option.
If you are interested in knowing about how Adatis can assist you in modernizing your data estate please get in touch.
Introduction to Data Wrangler in Microsoft Fabric
What is Data Wrangler? A key selling point of Microsoft Fabric is the Data Science
Jul
Autogen Power BI Model in Tabular Editor
In the realm of business intelligence, Power BI has emerged as a powerful tool for
Jul
Microsoft Healthcare Accelerator for Fabric
Microsoft released the Healthcare Data Solutions in Microsoft Fabric in Q1 2024. It was introduced
Jul
Unlock the Power of Colour: Make Your Power BI Reports Pop
Colour is a powerful visual tool that can enhance the appeal and readability of your
Jul
Python vs. PySpark: Navigating Data Analytics in Databricks – Part 2
Part 2: Exploring Advanced Functionalities in Databricks Welcome back to our Databricks journey! In this
May
GPT-4 with Vision vs Custom Vision in Anomaly Detection
Businesses today are generating data at an unprecedented rate. Automated processing of data is essential
May
Exploring DALL·E Capabilities
What is DALL·E? DALL·E is text-to-image generation system developed by OpenAI using deep learning methodologies.
May
Using Copilot Studio to Develop a HR Policy Bot
The next addition to Microsoft’s generative AI and large language model tools is Microsoft Copilot
Apr