MLFlow is an open-source MLOps platform designed by Databricks to enable organisations to easily manage their end-to-end machine learning lifecycle.
What is MLOps?
MLOps is a framework that applies the principles of DevOps to the development of machine learning models. In the same way as DevOps, a successful application of MLOps allows organisations to unify and align developers of the ML systems with the operations team for the ML application. This framework uses continuous integration and deployment to enable close collaboration between these teams with continuous feedback and re-assessment of goals.
How does MLFlow enable MLOps?
The MLFlow platform facilitates continuous integration and deployment (CI/CD) by providing a simple platform to manage crucial CI/CD tasks – keeping track of experiments and iterative improvements, comparing and reproducing versions of code, and staged and controlled deployment of ML models.
MLFlow is installed by default on the Databricks Runtime for ML – you can identify these as any Databricks Runtimes with an “ML” suffix. It can leverage all of the scalability and big data processing capability of Spark and works with any ML library, language or existing code.
It consists of 4 core components:

What is the Model Registry?
The Model Registry component of MLFlow is a centralised model store that allows users to collaboratively manage the full development lifecycle of an ML Model and standardises deployment.
Developers can use the MLFlow tracking component to run experiments and identify ways to optimise and improve their ML Models (see MLFlow: Introduction to ML Flow Tracking https://bit.ly/2Q9MMFf). Then, the Model Registry allows users to continuously deploy these improvements in a systematic and controlled way.
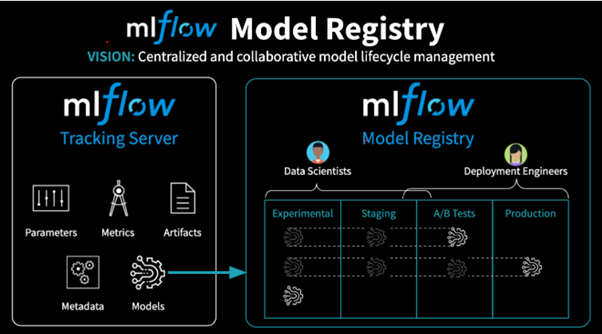
The Model Registry provides the following features:
- Central Repository: This repository contains all registered models, along with corresponding metadata. All previous versions of registered models are stored and accessible here.
- Model Staging: Registered models can be assigned to pre-built or custom stages to represent which phase they are at within the ML lifecycle. This allows developers to deploy new versions of a model into a Development stage, without impacting the model in Production.
- Managing and Monitoring Changes: Users can design events to automatically log key information when changes are made to the model registry. Users can also implement levels of control to the deployment process by requiring changes to the Model Registry to be requested, reviewed and approved before being submitted.
Demo
Let’s continue from the demo in Introduction to MLFlow: MLFlow Tracking (https://bit.ly/2Q9MMFf). To recap, we have a dataset with various attributes of many wines and a quality rating. We began an experiment and generated two runs of a linear regression model as part of this.
The first run uses only alcohol percentage as the feature input to predict the quality rating, whereas the second uses alcohol percentage as well as a selection of other fields as the feature inputs.
In this demonstration, we are going to show how programmatically interact with the Model Registry to:
- Register a model within the model registry using one of your existing runs
- Updating a model including versioned updates to the model itself, as well as updates to the model stage and model description
- Maintaining versions of a model, including running previous versions and applying version-specific changes
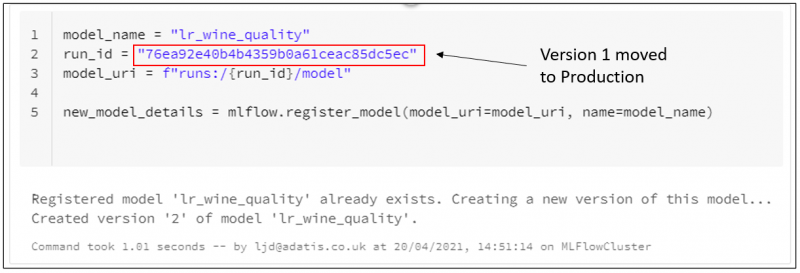
Using mlflow.register_model(…), we can register our run as a model in our Model Registry with the name “lr_wine_quality”. We can see that this run has successfully been registered as the first version of the model.
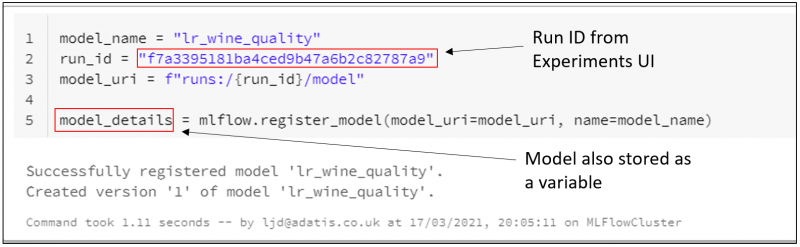
The registration can take a few seconds to process, and then we will be able to see this model in our Model Registry.
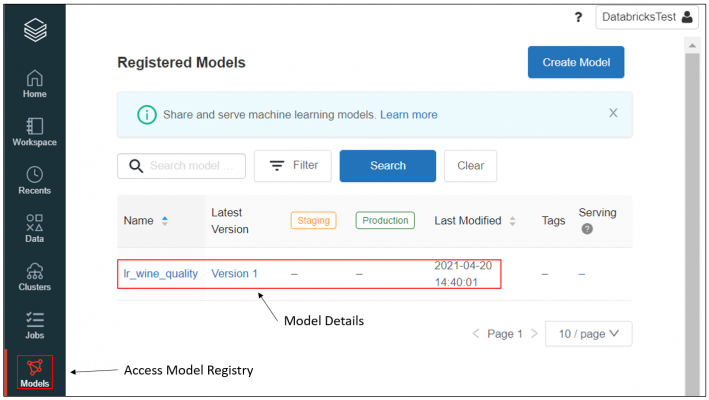
Now, let’s say we want to make some updates to our registered model. To do this, we are going to use the MLFlow Client, an API interface for programmatically interacting with MLFlow.

Let’s use the MLFlow client to move our model directly into the Production stage. The model_details variable was defined earlier when registering our model, and we can use this to retrieve attributes such as model name and model version.
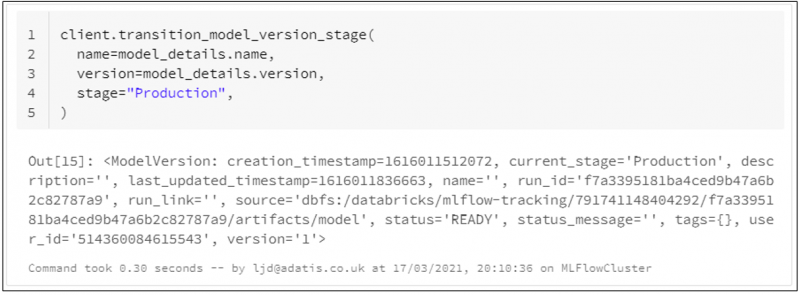
If we take a look back in our Model Registry, we can see that version 1 of the model has been added to the Production stage.
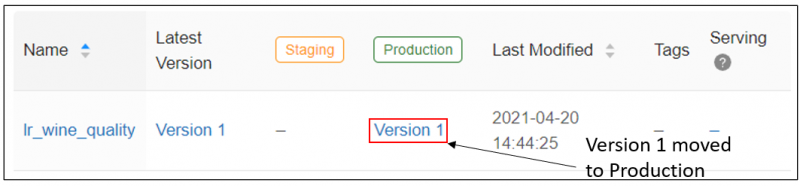
Now let’s imagine that a new field is added to our dataset, which indicates the PH level of the wine. We produce another run of our linear regression model, this time including the PH field, and we find that our RMSE is improved further.
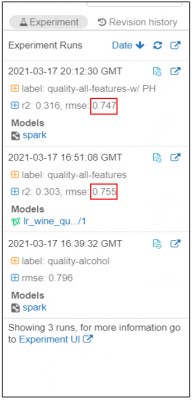
We may now wish to update the model in our registry with this improved model, but we may not wish to overwrite the model in Production until full testing is complete.
In the same way as before, we can register our latest run as a model with the same name to create a second version of this model, and then we can move this second version of the model into Staging whilst it undergoes further testing and review.
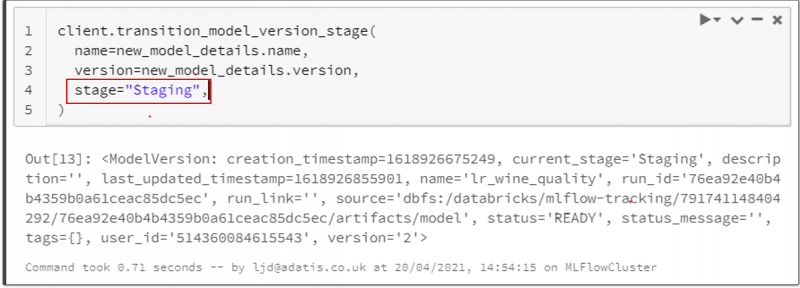
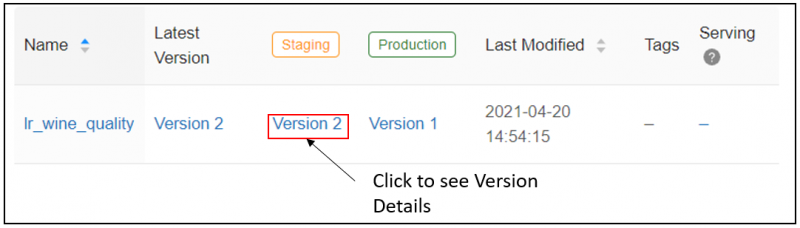
In our model registry, we can see that this change has been reflected.
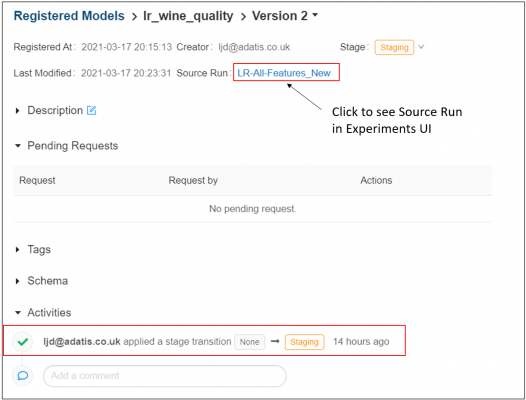
We can click through to the version details page to see a history of the stage transitions along with associated metadata of the request such as the user it came from and when it was made. We can also view here the underlying run on which this model version is based.
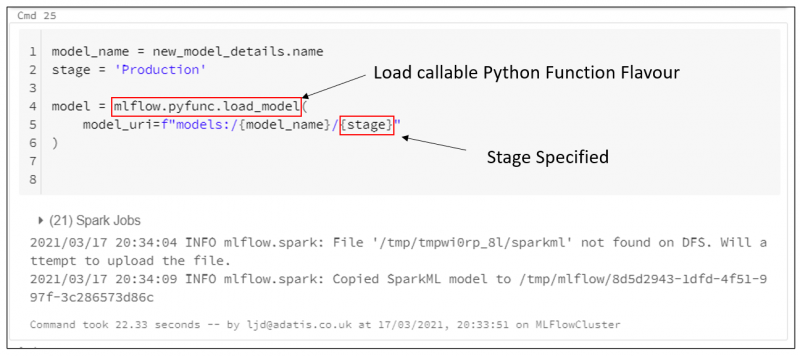
When loading the model, users can specify the stage to choose to load only whichever version is saved within that stage. So uploading our new version to Staging will not affect any of the runs which are pointed to Production.
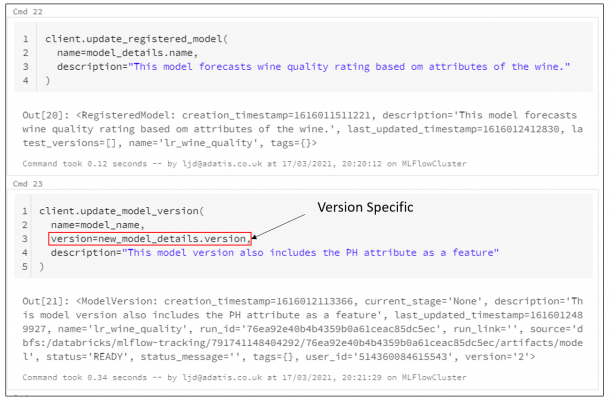
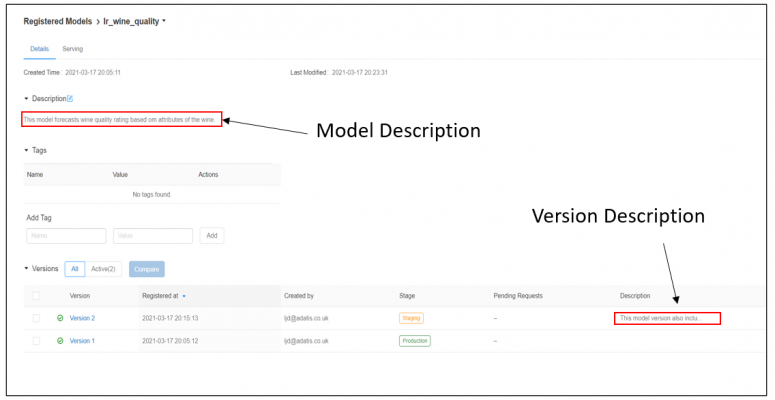
Finally, let’s update our model with some descriptions. We are going to add one description detailing the intended purpose of this model, and then we are going to add a version-specific description describing the difference between the first and second version.
If we return to our model registry and then click on the model name, we will see these changes reflected on our Model Details page.
In conclusion…
Overall, the Model Registry is a very useful tool for organisations looking to implement an MLOps approach – facilitating controlled and continuous integration and deployment of ML models and providing effective version control.
To read part one of this blog, An Introduction to MLFlow Tracking click here. If you have any questions, comments or feedback about any of the content of this blog, please feel free to reach out to me on LinkedIn.
Introduction to Data Wrangler in Microsoft Fabric
What is Data Wrangler? A key selling point of Microsoft Fabric is the Data Science
Jul
Autogen Power BI Model in Tabular Editor
In the realm of business intelligence, Power BI has emerged as a powerful tool for
Jul
Microsoft Healthcare Accelerator for Fabric
Microsoft released the Healthcare Data Solutions in Microsoft Fabric in Q1 2024. It was introduced
Jul
Unlock the Power of Colour: Make Your Power BI Reports Pop
Colour is a powerful visual tool that can enhance the appeal and readability of your
Jul
Python vs. PySpark: Navigating Data Analytics in Databricks – Part 2
Part 2: Exploring Advanced Functionalities in Databricks Welcome back to our Databricks journey! In this
May
GPT-4 with Vision vs Custom Vision in Anomaly Detection
Businesses today are generating data at an unprecedented rate. Automated processing of data is essential
May
Exploring DALL·E Capabilities
What is DALL·E? DALL·E is text-to-image generation system developed by OpenAI using deep learning methodologies.
May
Using Copilot Studio to Develop a HR Policy Bot
The next addition to Microsoft’s generative AI and large language model tools is Microsoft Copilot
Apr