In this blog I will provide an overview of the process for loading data into Snowflake. It will explain what staging the data means in the context of Snowflake, before illustrating the process of how data can be loaded into the Snowflake database from an Azure container. The goal of this blog is to help you understand from a conceptual point of view how data is loaded into Snowflake.
Staging
Before being loaded into a Snowflake table, the data can be optionally staged, which is essentially just a pointer to a location where the files are stored. There are different types of stages including:
– User stages, which each user will have by default
– Table stages, which each table will have by default
– Internal named stages, meaning staged within Snowflake
Internal named stages are the best option for regular data loads, if you are thinking along the lines of your standard daily ETL process. One benefit of these is the flexibility in that they are database objects, so you can grant privileges to roles to access these objects as you would expect. Alternatively, there are external stages, such as Azure Blob storage.
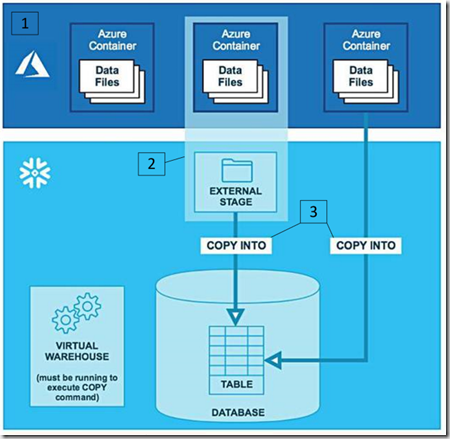
Let’s have a high level look at how you would load data into Snowflake.
![clip_image001_thumb[1]_thumb](https://adatis.co.uk/wp-content/uploads/historic/danbilsborough_clip_image001_thumb1_thumb_1.png "clip_image001_thumb[1]_thumb")
1. Source data is stored in files in an Azure container (Blob Storage, Azure Data Lake Store Gen1/Gen2).
2. Optionally, data can be staged, either internally within a Snowflake table, or externally, in an Azure container. If you choose to stage the data internally, you will need to use the PUT command to load the data into stage if it is stored on a local machine. This cannot be done from the Web UI for Snowflake, it needs to be done using SnowSQL, the CLI client for Snowflake. If you want to stage the data externally, such as in Blob Storage for example, you cannot use the PUT command, and may need to manually upload the data, use PowerShell, or Azure Data Factory for example, to load the data into the desired external stage location.
3. Use the ‘COPY INTO’ command (shown below) while a virtual warehouse is running with reference to a stage to load the data, or if the data is not staged, it can be loaded directly from the location the data is stored in, such as referencing a SAS token to load straight from Blob Storage.

Snowpipe
However, there is a second way that you can load data into Snowflake, which is called Snowpipe, allowing data to be continuously loaded in Snowflake once a file becomes available in stage. Essentially, you can call a public REST endpoint with a list of filenames and a pipe name, and if any of these files are in stage, they are added to the queue to be loaded. Discussing Snowpipe in-depth is a whole other blog in itself, but it’s worth noting that it is an option if you need data to be loaded into Snowflake more often than your daily ETL can provide.
Additional Features
Hopefully that should give a very brief overview of the concept behind loading data into Snowflake, however, there are a couple of features that are worth mentioning here.
– Firstly, Snowflake can load semi-structured data, think JSON or Parquet for example, which get loaded into a single VARIANT column, or you can transform the data into separate columns using the COPY INTO command.
– Secondly, if using an internal stage, unencrypted data will automatically be encrypted. Encrypted data can also be stored in an internal stage, providing the key used to encrypt the data is supplied to Snowflake.
Thanks for reading!
Introduction to Data Wrangler in Microsoft Fabric
What is Data Wrangler? A key selling point of Microsoft Fabric is the Data Science
Jul
Autogen Power BI Model in Tabular Editor
In the realm of business intelligence, Power BI has emerged as a powerful tool for
Jul
Microsoft Healthcare Accelerator for Fabric
Microsoft released the Healthcare Data Solutions in Microsoft Fabric in Q1 2024. It was introduced
Jul
Unlock the Power of Colour: Make Your Power BI Reports Pop
Colour is a powerful visual tool that can enhance the appeal and readability of your
Jul
Python vs. PySpark: Navigating Data Analytics in Databricks – Part 2
Part 2: Exploring Advanced Functionalities in Databricks Welcome back to our Databricks journey! In this
May
GPT-4 with Vision vs Custom Vision in Anomaly Detection
Businesses today are generating data at an unprecedented rate. Automated processing of data is essential
May
Exploring DALL·E Capabilities
What is DALL·E? DALL·E is text-to-image generation system developed by OpenAI using deep learning methodologies.
May
Using Copilot Studio to Develop a HR Policy Bot
The next addition to Microsoft’s generative AI and large language model tools is Microsoft Copilot
Apr