As I mentioned in my post a few weeks a ago, the PEL Allocate statement is a powerful method of moving data between PerformancePoint models.
Although it’s powerful, the end result of an Allocate statement is simply that the destination model will contain data that has been queried from the source model. What if the destination model already contains data for the target scope? If this is the case, then you will have double counting. When creating the Allocate rule, there is unfortunately no option that lets you decide what you want to do with existing data. Ideally you need to have the ‘Existing Data’ option that you get when running an association, which gives you the ‘Append’, ‘Scoped Replacement’ and ‘Full Replacement’ options.
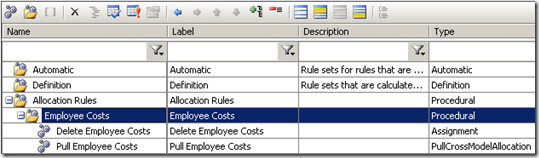
To get around this, I tend to place two rules inside a rule set. The first rule is a SQL implementation assignment rule with the same scope as the allocate rule, and deletes existing data by using the PEL statement this = NULL inside the rule. Then the second rule is the allocate statement, which appends the data. This is shown below:
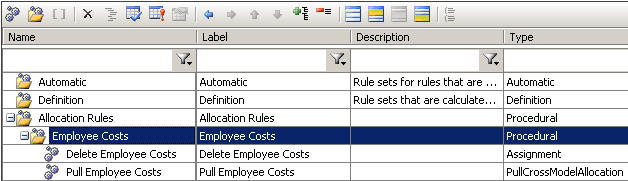
The idea is then to execute the rule set, which will execute each of its rules in order. The advantage to doing this is that your whole data movement process can be executed in one clean step (perhaps scheduled or via Excel), without the hassle of executing several individual rules.
Introduction to Data Wrangler in Microsoft Fabric
What is Data Wrangler? A key selling point of Microsoft Fabric is the Data Science
Jul
Autogen Power BI Model in Tabular Editor
In the realm of business intelligence, Power BI has emerged as a powerful tool for
Jul
Microsoft Healthcare Accelerator for Fabric
Microsoft released the Healthcare Data Solutions in Microsoft Fabric in Q1 2024. It was introduced
Jul
Unlock the Power of Colour: Make Your Power BI Reports Pop
Colour is a powerful visual tool that can enhance the appeal and readability of your
Jul
Python vs. PySpark: Navigating Data Analytics in Databricks – Part 2
Part 2: Exploring Advanced Functionalities in Databricks Welcome back to our Databricks journey! In this
May
GPT-4 with Vision vs Custom Vision in Anomaly Detection
Businesses today are generating data at an unprecedented rate. Automated processing of data is essential
May
Exploring DALL·E Capabilities
What is DALL·E? DALL·E is text-to-image generation system developed by OpenAI using deep learning methodologies.
May
Using Copilot Studio to Develop a HR Policy Bot
The next addition to Microsoft’s generative AI and large language model tools is Microsoft Copilot
Apr