Historically, when implementing big data processing architectures, Lambda has been the desired approach, however, as technology evolves, new paradigms arise and with that, more efficient approaches become available, such as the Databricks Delta architecture. In this blog, I’ll describe both architectures and demonstrate how to build a data pipeline in Azure Databricks following the Databricks Delta architecture.
The Lambda architecture, originally defined by Nathan Marz, is a big data processing architecture that combines both batch and real time processing methods. This approach attempts to balance latency, throughput, and fault-tolerance by using batch processing to provide comprehensive and accurate views of batch data, while simultaneously using real-time stream processing to provide views of online data.
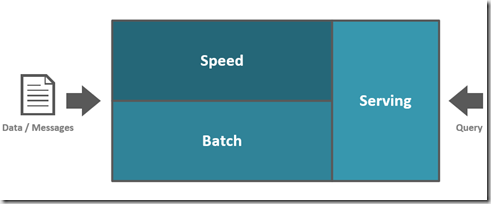
From a high-level perspective, the Lambda architecture is as followed.

A valid approach of using Lambda in Azure could be as demonstrated below (please be aware that there are different options for each layer that I won’t be detailing in this blog).

For the speed layer we could use Azure Streaming Analytics, a serverless scalable event processing engine that enables the development and run of real-time analytics on multiple streams of data from sources such as devices, sensors, web sites, social media, and other applications.
For the batch layer, we could use Azure Data Lake Storage (ADLS) and Azure Databricks. ADLS is an enterprise-wide hyper-scale repository for big data analytic workloads that enable us to capture data of any size, type, and ingestion speed in one single place for operational and exploratory analytics. Currently there are two versions of ADLS, Gen 1 and Gen 2, with the latest still being in private preview.
Azure Databricks is an Apache Spark-based analytics platform optimized for the Microsoft Azure cloud services platform that allow us to create streamlined workflows and interactive workspaces that enables collaboration between data scientists, data engineers, and business analysts.
For the serving layer, we could use Azure Data Warehouse, a cloud-based Enterprise Data Warehouse (EDW) that leverages Massively Parallel Processing (MPP) to quickly run complex queries across petabytes of data.
With this architecture, the events are consumed by the Azure Streaming Analytics and landed in ADLS in flat files, that can be partitioned by hour. Once the processing of the file is completed, we can create a batch process via Azure Databricks and store the data in the Azure SQL Data Warehouse. To obtain the data that was not captured by the batch process, we can use Polybase to query the file being updated and then create a view to union both tables. Every time that view is queried, the polybase table will get the latest streamed data, meaning we have a real time query with the capability to obtain the most recent data.
The major problem of the Lambda architecture is that we have to build two separate pipelines, which can be very complex, and, ultimately, difficult to combine the processing of batch and real-time data, however, it is now possible to overcome such limitation if we have the possibility to change our approach.
Databricks Delta delivers a powerful transactional storage layer by harnessing the power of Apache Spark and Databricks File System (DBFS). It is a single data management tool that combines the scale of a data lake, the reliability and performance of a data warehouse, and the low latency of streaming in a single system. The core abstraction of Databricks Delta is an optimized Spark table that stores data as parquet files in DBFS and maintains a transaction log that tracks changes to the table.
From a high-level perspective, the Databricks Delta architecture can be described as followed.

An Azure Databricks Delta Raw table stores the data that is either produced by streaming sources or is stored in data lakes. Query tables contains the normalized data from the Raw tables. Summary tables, often used as the source for the presentation layer, contains the aggregated key business metrics that are frequently queried. This unified approach means that there are less complexity due to the removal of storage systems and data management steps, and, more importantly, output queries can be performed on streaming and historical data at the same time.
In the next steps, I’ll demonstrate how to implement the Databricks Delta architecture using a python notebook.
#If Databricks delta is not enabled in the cluster, run this cell
spark.sql("set spark.databricks.delta.preview.enabled=true")
#Define variables
basePath = "/kafka"
taxiRidesRawPath = basePath + "/taxiRidesRaw.delta"
taxiRidesQueryPath = basePath + "/taxiRidesQuery.delta"
taxiFaresQueryPath = basePath + "/taxiFaresQuery.delta"
taxiSummaryPath = basePath + "/taxiSummary.delta"
checkpointPath = basePath + "/checkpoints"
#Load the Kafka stream data to a DataFrame
kafkaDF = (spark
.readStream
.option("kafka.bootstrap.servers", "192.168.1.4:9092")
.option("subscribe", "taxirides")
.option("startingOffsets", "earliest")
.option("checkpointLocation", "/taxinyc/kafka.checkpoint")
.format("kafka")
.load()
)
#Kafka transmits information using a key, value, and metadata such as topic and partition. The information we're interested in is the value column. Since this is a binary value, we must first cast it to a StringType and then split the columns.
#Stream into the Raw Databricks Delta directory. By using a checkpoint location, the metadata on which data has already been processed will be maintained so the cluster can be shut down without a loss of information.
from pyspark.sql.types import StructType, StructField,LongType,TimestampType,StringType,FloatType,IntegerType
from pyspark.sql.functions import col, split
(kafkaDF
.select(split(col("value").cast(StringType()),",").alias("message"))
.writeStream
.format("delta")
.option("checkpointLocation", checkpointPath + "/taxiRidesRaw")
.outputMode("append")
.start(taxiRidesRawPath)
)
#Create and populate the raw delta table. Data is stored in a single column as an array Eg. ["6","START","2013-01-01 00:00:00","1970-01-01 00:00:00","-73.866135","40.771091","-73.961334","40.764912","6","2013000006","2013000006"]
spark.sql("DROP TABLE IF EXISTS TaxiRidesRaw")
spark.sql("""
CREATE TABLE TaxiRidesRaw
USING Delta
LOCATION '{}'
""".format(taxiRidesRawPath))
#Stream into the Query Databricks delta directory.
(spark.readStream
.format("delta")
.load(str(taxiRidesRawPath))
.select(col("message")[0].cast(IntegerType()).alias("rideId"),
col("message")[1].cast(StringType()).alias("rideStatus"),
col("message")[2].cast(TimestampType()).alias("rideEndTime"),
col("message")[3].cast(TimestampType()).alias("rideStartTime"),
col("message")[4].cast(FloatType()).alias("startLong"),
col("message")[5].cast(FloatType()).alias("startLat"),
col("message")[6].cast(FloatType()).alias("endLong"),
col("message")[7].cast(FloatType()).alias("endLat"),
col("message")[8].cast(IntegerType()).alias("passengerCount"),
col("message")[9].cast(IntegerType()).alias("taxiId"),
col("message")[10].cast(IntegerType()).alias("driverId"))
.filter("rideStartTime <> '1970-01-01T00:00:00.000+0000'")
.writeStream
.format("delta")
.outputMode("append")
.option("checkpointLocation", checkpointPath + "/taxiRidesQuery")
.start(taxiRidesQueryPath)
)
#Create and populate the quer delta table. Data is no longer in a single column
spark.sql("DROP TABLE IF EXISTS TaxiRidesQuery")
spark.sql("""
CREATE TABLE TaxiRidesQuery
USING Delta
LOCATION '{}'
""".format(taxiRidesQueryPath))
#Load the data to a DataFrame. The parquet files are stored in a blob storage
taxiFaresDF = (spark.read
.parquet("/mnt/geospatial/kafka/NYC")
.write
.format("delta")
.mode("append")
.save(taxiFaresQueryPath)
)
#Create and populate the query delta table
spark.sql("DROP TABLE IF EXISTS TaxiFaresQuery")
spark.sql("""
CREATE TABLE TaxiFaresQuery
USING Delta
LOCATION '{}'
""".format(taxiFaresQueryPath))
#Load the data to a DataFrame
taxiRidesDF = (spark
.readStream
.format("delta")
.load(str(taxiRidesQueryPath))
)
#Load the data to a DataFrame
taxiFaresDF = (spark
.read
.format("delta")
.load(str(taxiFaresQueryPath))
)
#Join the steaming data and the batch data. Group by Date and Taxi Driver to obtain the number of rides per day
from pyspark.sql.functions import date_format, col, sum
RidesDf = (taxiRidesDF.join(taxiFaresDF, (taxiRidesDF.taxiId == taxiFaresDF.taxiId) & (taxiRidesDF.driverId == taxiFaresDF.driverId))
.withColumn("date", date_format(taxiRidesDF.rideStartTime, "yyyyMMdd"))
.groupBy(col("date"),taxiRidesDF.driverId)
.count()
.withColumnRenamed("count","RidesPerDay")
.writeStream
.format("delta")
.outputMode("complete")
.option("checkpointLocation", checkpointPath + "taxiSummary")
.start(taxiSummaryPath)
)
#Create and populate the summary delta table
spark.sql("DROP TABLE IF EXISTS TaxiSummary")
spark.sql("""
CREATE TABLE TaxiSummary
USING Delta
LOCATION '{}'
""".format(taxiSummaryPath))
As always, if you have any questions or comments, do let me know.
Introduction to Data Wrangler in Microsoft Fabric
What is Data Wrangler? A key selling point of Microsoft Fabric is the Data Science
Jul
Autogen Power BI Model in Tabular Editor
In the realm of business intelligence, Power BI has emerged as a powerful tool for
Jul
Microsoft Healthcare Accelerator for Fabric
Microsoft released the Healthcare Data Solutions in Microsoft Fabric in Q1 2024. It was introduced
Jul
Unlock the Power of Colour: Make Your Power BI Reports Pop
Colour is a powerful visual tool that can enhance the appeal and readability of your
Jul
Python vs. PySpark: Navigating Data Analytics in Databricks – Part 2
Part 2: Exploring Advanced Functionalities in Databricks Welcome back to our Databricks journey! In this
May
GPT-4 with Vision vs Custom Vision in Anomaly Detection
Businesses today are generating data at an unprecedented rate. Automated processing of data is essential
May
Exploring DALL·E Capabilities
What is DALL·E? DALL·E is text-to-image generation system developed by OpenAI using deep learning methodologies.
May
Using Copilot Studio to Develop a HR Policy Bot
The next addition to Microsoft’s generative AI and large language model tools is Microsoft Copilot
Apr