
Often, when building data analytics solutions, we are asked to integrate with third-party tools that are not part of the Microsoft ecosystem. In this 3 part blog series, I’ll demonstrate how to send data to Salesforce and NetSuite using Azure Data Factory (ADF).
- Ingest your data to Salesforce Marketing Cloud using Azure Data Factory
- Ingest your data to Salesforce Service Cloud using Azure Data Factory
- Ingest your data to NetSuite using Azure Data Factory
Salesforce is a Customer Relationship Management (CRM) solution that can integrate different departments, like marketing, sales or service, in a single shared view. Salesforce Service Cloud (SFSC) is a service platform for the organisation’s customer service and support team. It provides features like case tracking and social networking plug-in for conversation and analytics.
Scenario
- A SFSC administrator created a set of custom data extensions (objects equivalent to tables in SQL). You have to build a process in ADF that will select data from Azure SQL DB and ingest it to SFSC.
Considerations & Limitations
- The copy activity in ADF contains a considerable list of connectors to Microsoft and third-party tools (list available here). The connector can copy data from SFSC to any supported sink data store and vice-versa (further details here). In this blog, I’ll demonstrate how to ingest to SFSC using the REST/BULK APIs and how to retrieve results from SFSC using the ADF connector. Although the pattern is more complex, this is the recommended approach to achieve better performance results
- The BULK API body expects a CSV file
- The body of the REST/BULK API is limited to 1MB, therefore, the data has to be split in batches. The number of rows in each batch depends on the number of columns of the object in Azure SQL DB and the length of the values
Solution
The proposed pattern uses 3 ADF pipelines:
- Service Cloud Parent
- Service Cloud Group
- Service Cloud Child
Service Cloud Parent

*Lookup Group Number Procedures – Obtains the list of stored procedures that calculates how many groups each table should have
*ForEach Group Number Procedure – Contains a Stored Procedure activity that executes the objects obtained in the previous step. The data is stored in GroupNumber tables. (Eg, CustomerGroupNumber)
*Lookup Salesforce Procedures – Obtains a list with two types of stored procedures. One receives the group number as a parameter, split the data into small chunks and converts it to text/csv format (SPA) and the other updates the records that have been consumed (SPB)
*ForEach Salesforce Procedure – Contains an Execute Pipeline activity that invokes the Service Cloud Group pipeline. The batch count can be changed to increase/decrease the number of concurrent executions
Service Cloud Group
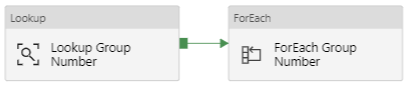
*Lookup Group Number – Obtains the number of groups stored in the GroupNumber table
*ForEach Group Number – Contains an Execute Pipeline activity that invokes the Service Cloud Child pipeline. The batch count can be changed to increase/decrease the number of concurrent executions
Service Cloud Child
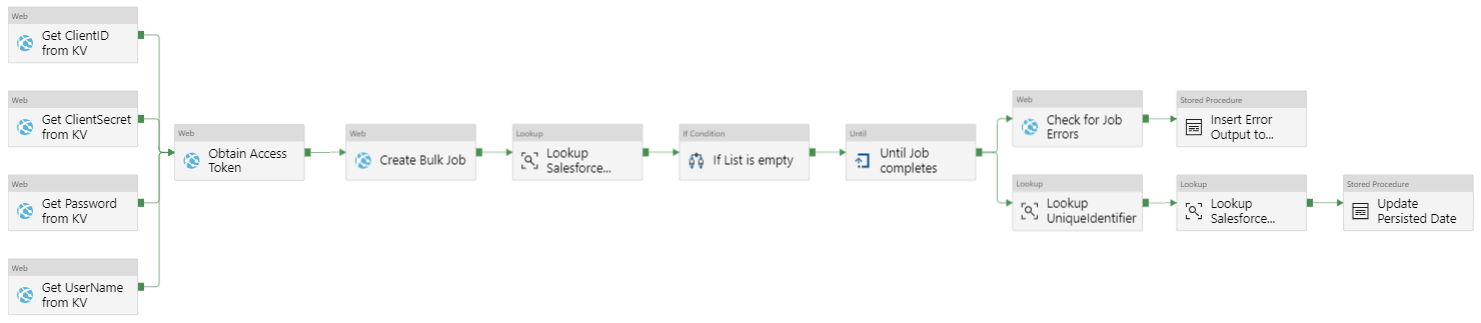
*Get ClientID from KV – Obtains the SFSC Client ID stored in Key Vault
*Get ClientSecret from KV – Obtains the SFSC Client Secret stored in Key Vault
*Get Password from KV – Obtains the SFSC Password stored in Key Vault
*Get UserName from KV – Obtains the SFSC Username stored in Key Vault
*Obtain Access Token – To use the API functionality the source application must obtain an access token from the SFSC authentication API. This access token is then used in an authentication header in subsequent calls. Find here the Access Token Request details
*Create Bulk Job – Because of the data volumes, calls should use the BULK API to upload data to SFSC. This call creates a job to import multiple rows into a data object. Find the API details here
*Lookup Salesforce Procedure – Executes the stored procedures of type SPA
*If List is empty – Verifies if the output of the previous activity is empty. If false, uploads the the data to SFSC and marks the job as completed
![]()
**Upload data to Bulk Job – Uploads the data to the job. Find the API details here
**Set Job Status to UploadComplete – Sets the job status to UploadComplete and thus ready to import. Find the API details here
*Until Job Completes – Because we are running an asynchronous process, we need a mechanism to check when the job completes before moving to the next activity. To do so, we have an Until activity with two activities. The execution proceeds once the result of the Get Job Status web activity is JobComplete or Failed
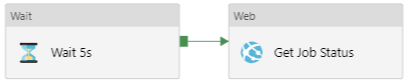
**Wait 5s – Wait 5 seconds until it proceeds to the next activity
**Get Job Status – Returns the status of a bulk import job using the job Id from the call in the Create Bulk Job web activity. Find the API details here
*Check for Job Errors – Returns the results of a bulk job using the job Id from the call in the Create Bulk Job web activity. Find the API details here
*Insert Error Output to Error Table – Takes the output of the previous activity and inserts it in a table in Azure SQL DB.
*Lookup Unique Identifier – Each row posted to SFSC can be uniquely identified. This activity executes a stored procedure that returns the list of unique identifiers from Azure SQL DB
*Lookup Salesforce Upserted Records – This activity uses the ADF SFSC connector and, using the list of unique identifiers, queries a SFSC data object to understand which records were successfully posted
*Update Persisted Date – Executes the stored procedures of type SPB








Hello Jose
This is a great article. We are looking to implement something similar in our company that is to insert data in Saleforce from Azure Synapse using DataFactory. Can you explain how the output of data can be converted to CSV using the SPA stored procedure?
Here’s an example on how to convert the data to a CSV format
CREATE PROCEDURE [Salesforce].[ObtainJSONEntity]
-- =============================================
-- Author: Adatis
-- Description: Output Data as CSV
--
-- =============================================
@groupNumber AS INT = NULL
AS
BEGIN
SELECT STRING_AGG(Entity, CHAR(10)) AS Entity
FROM
(SELECT STRING_AGG(CAST(CONCAT(
'ColumnA'
, '|', 'ColumnB'
, '|', 'ColumnC'
, CHAR(10)
) AS NVARCHAR(MAX)), CHAR(10)) AS Entity
UNION ALL
SELECT STRING_AGG(CAST(REPLACE(REPLACE(CONCAT(
ColumnA
, '|', ColumnB
, '|', ColumnC
),'"',''),'''','') AS NVARCHAR(MAX)), CHAR(10)) AS Entity -- Remove single + double quotes from dataset
FROM(
SELECT DISTINCT
ColumnA
,ColumnB
,ColumnC
FROM
[dbo].[SalesforceEntity] sfe
INNER JOIN [Persisted].[SalesforceEntityGroupNumber] G
ON G.EntityChangeHash = sfe.EntityChangeHash
WHERE G.groupNumber = @groupNumber
) Ent
) A
END
Hi Jose
Thanks for your reply. This procedure to convert looks good, but it is difficult to implement if there are columns with data types other than Varchar, so it can create problems if written for a generic pipeline. Is it possible that this dynamic sql result is converted within the pipeline to CSV file put in blob storage and try to post this CSV file to the Upload data to Bulk Job activity using parameters?
Hi,
The Salesforce API expects a CSV body not a file, so I don’t think your approach would work, but you can always test it and hopefully prove me wrong 🙂
Hi Jose
I understand that the CSV file directly cannot be posted to Salesforce Bulk API, but reading its content and passing it in the API body is achievable. With little tweaking and help from Microsoft Q&A, I was able to read the content from CSV file in Blog container and dynamically passed in the body of the Insert CSV data end point of Bulk Data API call. Following is the link of Microsoft Q&A for your reference.
https://docs.microsoft.com/en-us/answers/questions/354596/adf-how-to-post-csv-format-data-in-the-rest-api-bo.html
Glad you could find a solution for your problem. Thanks for sharing 🙂