
Real-time collaboration, code completion and data versioning are just a few of the latest capabilities that have made workspace selection in the tech industry competitive. The need for an interactive and collaborative environment that enables teams to work together on tasks has driven the development of several products, most of which have some functionality of storage, processing and visualisation.
At Adatis, we utilise Databricks notebooks for early transformations in our framework and Spark notebooks in Azure Synapse for anything after. This short blog looks at some of the key considerations for notebook selection and highlights some features of the newer alternatives to help understand, if and where, these could be utilised.
1. Key Considerations
Below are some key points to consider when selecting a collaborative notebook:
Data science, data engineering or data analytics?
There are a variety of notebooks now available, with some more aligned to machine learning models and the ability to utilise popular data science libraries and tools. Others have SQL-based interfaces and integrations to ETL tooling and some even offer built-in visualisation and insight. In some cases, these are available all in the same product, so it’s critical to understand the use case of the notebook and who will be collaborating on it, before selecting the best route to take.
How key is collaboration to the project?
Below, we look at 3 alternative notebooks that provide a fully collaborative experience. Each has a different variety of features including: real-time collaboration, model sharing, shared dataset access, code version control, query history and more. Products such as Google Colab, for example, haven’t been considered here due to a lack of real-time collaboration, however some of these may be more suitable for solo work.
Ecosystem
It is important that the notebook integrates effectively with your tech stack, as this can dramatically increase efficiency on the project and reduce costs. It is advised to test notebooks within the required architecture to ensure they are the right fit.
2. Current Architecture
Cleansed data is currently written to our base layer using Databricks, the cloud-based platform for big data analytics and machine learning. It is built on Apache Spark and designed to simplify the process of building, managing and scaling data pipelines and machine learning workflows, as well as integrating cohesively with the Azure stack.
Some benefits of Databricks include:
- Its streamlined data processing and data transformation,
- Collaborative features including version control,
- Shared workspaces and real-time processing,
- High levels of security,
- Compliance with encryption, access controls, and audit logs.
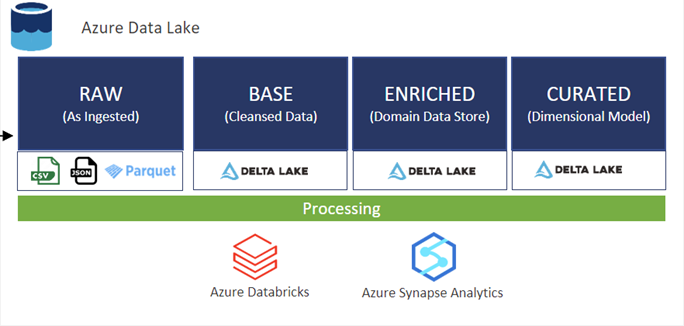
For later transformations, Spark Notebooks provide similar benefits when used in conjunction with Azure Synapse Analytics – the cloud-based analytics service provided by Microsoft. The major advantage of this notebook is the seamless integration with the Azure platform, including Azure Data Lake Storage, Azure Databricks and Azure Machine Learning. These services allow leverage for storage, processing and ML tasks in a familiar environment.
Other benefits include: scalability, multi-language support, Pause and Resume Cost Management and the ability to integrate with traditional SQL-based analytics, warehousing and big data processing for both structured and unstructured data.
3. Alternative Products
So, are there alternative products that could be tested as part of the framework? Let’s discuss.
Hex
Hex is a platform primarily designed for collaborative data science and machine learning, providing a workspace where data professionals can work on projects together to share code and results. It has version control, integration with popular data science tools, integrated SQL for fast and secure queries and a built-in app builder to share work with an interactive interface.
Hex is a versatile platform that can be useful in various scenarios where collaborative, interactive and exploratory data analysis is required. Its main focus is on data science, where it can be used for building and testing machine learning models with data scientists who are able to develop and train these using various machine learning libraries and frameworks available in the platform.
Hyperquery
Hyperquery is another collaborative platform, focusing on making SQL analysis more accessible to teams. It provides a web-based workspace for querying data, making it easy for non-technical users to work with. The interface is SQL-based with collaborative features for sharing queries and results, support for connecting to various data sources and features such as query versioning, access control and data governance.
It is a cost-effective solution for lightweight data analytics and engineering tasks where users can write SQL queries and visualise results in a collaborative environment. This is especially beneficial for data analysts and business analysts who work with structured data.
Deepnote
Deepnote has a similar approach to Hex, with a focus on data science and machine learning, but is a Jupyter based notebook environment. It allows teams to simultaneously work on notebooks together, share insight and deploy models. Like Databricks, SQL and Python, Deepnote can be used in the same notebook interface with version control, real time collaboration and integration of popular data science libraries.
Other features include: data visualisation and sharing capabilities, automation of data processing through scheduling, AI model support and code autocompletion.
Its flexibility, collaboration features, and integrated environment for data analysis and machine learning therefore make it a versatile tool that can be adapted to various data-related use cases.
4. Summary
Below is a table summary for each of these workspaces against our current architecture:
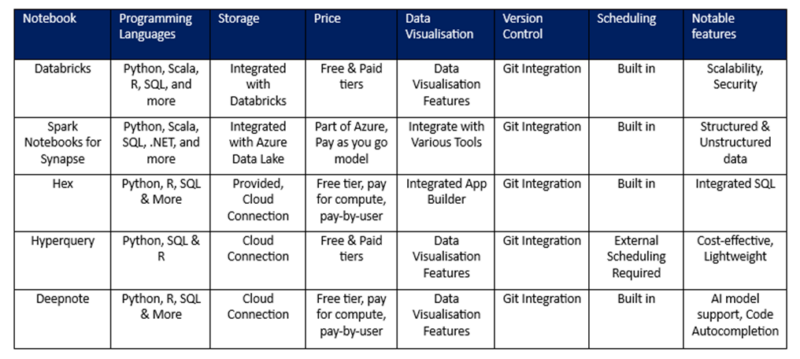
Table comparison of each tool
As shown by the table above, the alternative products perform well against the current framework approach, with multiple programming languages, git integration, tiered pricing models and visualisation options. However, with little obvious benefit over Databricks and Spark notebooks for Synapse Analytics, it would be difficult to recommend testing these products in the current architecture at present, as they lack the fundamental integration with Azure that the current model provides.
Where these products may be of benefit are when looking at data science and machine learning extensions to the framework. In this scenario, Deepnote and Hex may provide enhanced functionality.
For any further thoughts or questions please reach out to me, Thomas Dickson, at t_d@adatis.co.uk
Introduction to Data Wrangler in Microsoft Fabric
What is Data Wrangler? A key selling point of Microsoft Fabric is the Data Science
Jul
Autogen Power BI Model in Tabular Editor
In the realm of business intelligence, Power BI has emerged as a powerful tool for
Jul
Microsoft Healthcare Accelerator for Fabric
Microsoft released the Healthcare Data Solutions in Microsoft Fabric in Q1 2024. It was introduced
Jul
Unlock the Power of Colour: Make Your Power BI Reports Pop
Colour is a powerful visual tool that can enhance the appeal and readability of your
Jul
Python vs. PySpark: Navigating Data Analytics in Databricks – Part 2
Part 2: Exploring Advanced Functionalities in Databricks Welcome back to our Databricks journey! In this
May
GPT-4 with Vision vs Custom Vision in Anomaly Detection
Businesses today are generating data at an unprecedented rate. Automated processing of data is essential
May
Exploring DALL·E Capabilities
What is DALL·E? DALL·E is text-to-image generation system developed by OpenAI using deep learning methodologies.
May
Using Copilot Studio to Develop a HR Policy Bot
The next addition to Microsoft’s generative AI and large language model tools is Microsoft Copilot
Apr