
Databricks is an organisation and industry-leading commercial cloud-based data engineering platform for processing and transforming big data. The is an open-source, distributed processing system used for big data workloads. It utilises in-memory caching and optimised query execution for fast queries on data of any size. Simply put, Spark is a fast and general engine for large-scale data processing. The service provides three environments for data-intensive applications:
- Databricks SQL
- Databricks Data Science & Engineering
- Databricks Machine Learning
So where does Databricks come from?
To answer that we have to go back to 2003 when Google released ‘Google File System Papers’ (the predecessor to the Hadoop file system). This took data and spread it across lots of small, cheap commodity discs with the intention of avoiding buying expensive hard-disks and instead buying many smaller hard-disks and spreading the data across them. The following year in 2004 Google released ‘Google MapReduce Papers’ which was essentially doing the same for compute: taking a compute query and spreading that workload across many cheap computers, each of which are communicating with a Hadoop file system. These two things together mean that one can have an incredibly large-scale system without having specialist hardware, leading to the creation of the ‘Apache Hadoop project’ in 2006.
In 2012 Matei Zaharia, alongside his colleagues at UC Berkeley, created the Spark project; this took the idea of parallel processing from Google’s MapReduce and Hadoop but did it in memory. Consequently, a lot of the i/o and disk rewrites were circumvented making the process more efficient. This idea was then donated to the Apache Foundation in 2013 and became what we now know as Apache Spark.
Following this donation, Matei Zaharia and his colleagues at UC Berkeley founded the company Databricks. The company aimed to accompany the open-source project by adding a management layer around Spark. This essentially made it the User interface / front end , making it the easiest and best way to work with Spark.
What is Apache Spark?
At a glance, Apache Spark is made up of its core and 4 components. The Apache Spark core is the underlying execution engine for which all of the other functionality is built upon. It provides the whole mechanism of having data spread across lots of different parallel servers without losing any data and without any corruption (providing in-memory computing and referencing datasets in external storage systems).
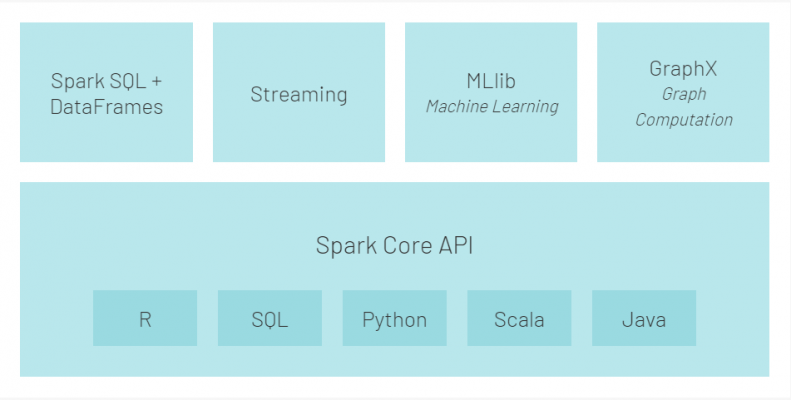
Spark SQL + DataFrames is Apache Spark’s module for working with structured data. DataFrames are essentially objects with an API on top of the central distributed layer which allows data manipulation and transformations using languages that are fairly accessible. The interface offered by SparkSQL offers more information about the data itself and the computations being performed.
Spark streaming allows Spark to process real-time streaming data. This data is then processed using complex algorithms and pushed out into file systems, databases and live dashboards.
Apache Spark is equipped with a library devoted to machine learning, MLlib. This library contains a plethora of machine learning algorithms including, but not limited to, classification, regression, clustering, and collaborative filtering. It also includes other tools for constructing, evaluating, and tuning Machine Learning Pipelines. All these functionalities help Spark scale out across a cluster.
The final component is GraphX, this is a library used to manipulate graph databases and perform computations. GraphX also unifies the ETL (Extract, transform and load) process, exploratory analysis, and iterative graph computation within a single system.
So, what are the benefits of Apache Spark?
Firstly, the speed. Due to Apache Spark being the successor of technologies like Google’s MapReduce and Hadoop, engineered from the bottom-up for performance, building on the flaws of its predecessor, Spark can be 100x faster than Hadoop for large scale data processing.
Secondly, the ease of use of Apache Spark. It has easy-to-use APIs for operating on large datasets. It offers more than 80 high-level operators that make it easy to build parallel apps.
Finally, and possibly the best thing about Apache Spark is its immense open-source community. Anyone can inspect, modify, or enhance the source code that has been made available to the public. This gives the community the opportunity to be a part of and contribute to something bigger.
Benefits for using Apache Spark through Databricks:
Familiar programming languages and environments
Although Databricks is Spark-based it still allows the use of commonly used programming languages like Python, R and SQL. These languages are then converted in the backend through API’s to interact with Spark. This makes the system easier to use and it does not limit it to one language; it allows users to work with languages they may already know. Even though these languages are available to use, they have slight modifications (like package names) which are needed for the language to interact with Spark.
Additionally, upon launching a Notebook (a web-based interface to a document that contains runnable code, visualizations, and narrative text) on Databricks, users are greeted with Jupyter like Notebooks, which is widely used in the world of big data and machine learning. These fully functional Notebooks mean outputs can be viewed after each step, unlike alternatives to Azure Databricks where only a final output can be viewed.
Higher productivity and collaboration
Production Deployments: Deploying work from Notebooks into production can be done almost instantly by just tweaking the data sources and output directories. Workspaces: Databricks creates an environment that provides workspaces for collaboration, deploys production jobs (including the use of a scheduler), and has an optimized Databricks engine for running. These interactive workspaces allow multiple people to collaborate in parallel.
Version Control: Version control is automatically built-in, with very frequent changes by all users saved. It also allows the user to use the revision history to revert to previous versions. To support the best practices for data engineering and data science code development, Databricks now provides repository-level integration with Git providers including:
- GitHub
- Bitbucket
- GitLab
- Azure DevOps
For more information on this visit: Databricks Repos – What it is and how we can use it
Extensive documentation and support available
Extensive documentation and support are available for all aspects of Databricks, including the programming languages needed.
To summarise Databricks is a powerful and affordable tool for organisations or individuals looking to work with big data in a world of ever-growing data. As the current digital revolution continues, using big data technologies will become a necessity for many organisations. Databricks is extremely flexible and intuitive which makes distributed analytics much easier to use. This blog is merely the tip of the iceberg, Databricks has a lot of fantastic documentation available. For more, have a read of some of the documentation linked below:
Getting Started With Databricks on Azure
Databricks Repos – What it is and how we can use it
Power BI with Azure Databricks for Dummies (in 15 minutes)
Introduction to Data Wrangler in Microsoft Fabric
What is Data Wrangler? A key selling point of Microsoft Fabric is the Data Science
Jul
Autogen Power BI Model in Tabular Editor
In the realm of business intelligence, Power BI has emerged as a powerful tool for
Jul
Microsoft Healthcare Accelerator for Fabric
Microsoft released the Healthcare Data Solutions in Microsoft Fabric in Q1 2024. It was introduced
Jul
Unlock the Power of Colour: Make Your Power BI Reports Pop
Colour is a powerful visual tool that can enhance the appeal and readability of your
Jul
Python vs. PySpark: Navigating Data Analytics in Databricks – Part 2
Part 2: Exploring Advanced Functionalities in Databricks Welcome back to our Databricks journey! In this
May
GPT-4 with Vision vs Custom Vision in Anomaly Detection
Businesses today are generating data at an unprecedented rate. Automated processing of data is essential
May
Exploring DALL·E Capabilities
What is DALL·E? DALL·E is text-to-image generation system developed by OpenAI using deep learning methodologies.
May
Using Copilot Studio to Develop a HR Policy Bot
The next addition to Microsoft’s generative AI and large language model tools is Microsoft Copilot
Apr