In my last posts, I’ve spoken about using Polybase as a basic data loading mechanism for Azure SQLDW, some of the ways to maximise performance and some of the limitations that exist within the current implementation. But we haven’t gone into specific implementation designs… until now.
The key ideas we will discuss are:
- File Loading structures
- Fast-Moving Entities
Data Loading
As discussed in the Polybase Limitations post – it is difficult to get file lineage from records extracted from a Polybase external table. Therefore, when I am using Polybase to load a strict warehouse, I want to be able to quickly switch the context of the external table.
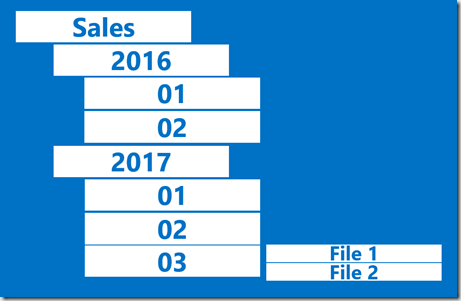
Let’s assume we have a vertically partitioned file within an Azure Data Lake structure – files are loaded into separate date folders. If multiple files are loaded in the same day, they will be placed in the same “day” folder.

One of Polybase’s major benefits is that is can loop through all subfolders within the root folder. The first and most obvious use case is to point Polybase at the root folder. This brings back all records from files within any folder – essentially we can load all records that exist anywhere within that whole structure.

This is useful as a validation technique, using the full history of our data loads to check against what has currently been loaded through to the warehouse.
However – as there is no push-down predicate support in Polybase, we don’t want to be using this for regular loads otherwise each query will be reading ALL files, then discarding anything except the latest. Our loads would slow down over time.
The next progression is to separate files that have not yet been loaded into a loading or “active” folder. This means you can have a single definition for your external table and only query the files you are interested in. However, it does mean you have to manage the archiving of these files once the load has finished successfully, it’s another step in the process.

The process I have settled on recently is a little more complicated but much more flexible. As a part of my usual metadata structures, I keep a table of files that require loading into the warehouse. This allows for tracking lineage, progress, history etc and is something I include in most systems regardless.
A simplified version would look something like this:

Given this exists, we can use it to programmatically recreate the External Table, changing the [LOCATION] setting to point to the relevant file to be loaded using our [Source Path] column. Our pattern now looks like this:

We can then use a WHILE loop to run through the files to be loaded, bringing the rows from each into the warehouse. This has the added advantage of also allowing us to track exactly which file has been loaded from each query.
This isn’t the most efficient use of Polybase – we gain much more efficiency by loading lots of files at once. However – we can be running data loads from many different file types at once, using the available external readers from our SQLDW compute nodes as effectively as possible.
This technique has added benefits however – if we had to perform a historical load, or do a one-off checksum, we can use this same technique to re-point the loading External Table at a mid-level folder.
We do this by simply adding a dummy record pointing at the upper path:

If we put this through our usual process, the External Table would be recreated at load and pointed to the 2017 folder:

This provides a nice, easy historical loading mechanism, as well as a flexible daily load process. It does, however, require writing a little Dynamic SQL to do the external table recreation.
Fast-Moving Entities
That’s enough about data loading for now, there’s another major use case for Polybase that we haven’t yet discussed. Many data processing solutions have a huge, unwieldy overnight batch job that performs aggregates, lookups, analytics and various other calculations.
However, it is often the case that this is not timely enough for many business requirements. This is where Polybase can help.
If we have an External Table over the newest files, this will read these new records at query time. We can write a view that combines the External Table with our batch-produced table. This will obviously go a little slower than usual, given it has to read data from flat files each time, however the results returned will be up to date.
This isn’t always going to be possible – sometimes the transformations and calculations applied to the source files are too complex to be replicated on the fly. But it is worth bearing in mind as a simple design pattern for providing near real-time reports without over-engineering your solution.

If you’re familiar with the Lambda Architecture (one of the key movements within traditional Big Data architectures) – this is akin to using the Azure SQL DataWarehouse as the “Serving Layer” component, unifying the batch and speed processes.
As usual, if you have any questions, please get in touch!








Can we create external table structure dynamically by reading files from ADLS Gen 1?