So here we are – you’ve designed your target distribution, you’re scaling your warehouse appropriately and you’ve set up Polybase to access raw data outside of the system. You are now ready to bring data into the warehouse itself so we can start working on it.
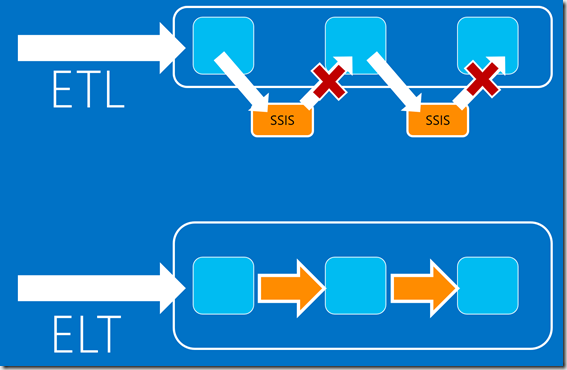
Firstly, you should be aware that we’re building using ELT not ETL, ie: we design to allow for the warehouse itself to do the work as it is the powerful processing option available to us. When first introducing Polybase, I described how it is the only method of loading data into SQLDW that does not get bottlenecked through the control node. Well the same limitations will be present if we try and transform our data using traditional ETL tools tool. If we used an SSIS data flow, for example, this would extract data out, pull it across to the SSIS server, perform the transformation and then attempt to reinsert the data. Not only are we introducing network latency, but we are also ignoring the power of the MPP engine AND encountering the throughput limits of the control node.

In order to utilise SQLDW effectively, we write SQL for our transformations, rather than relying on external tools such as SSIS. This ensures the work is being done by our compute nodes and, therefore, can be scaled up to increase performance.
General best practice, therefore, would be write stored procedures for each of the data movements we want to occur. This allows us to add in auditing, logging etc. But what we’re interested in here is the core data movement itself.
Writing a traditional INSERT statement isn’t the fastest way to get data into a table. There is a special syntax which creates a new table and inserts into it, that is automatically configured for optimal bulk loading, this is the CTAS, or “Create Table as Select” statement.
CREATE TABLE [dbo].[MyTable] WITH ( HEAP, DISTRIBUTION = ROUND_ROBIN ) AS SELECT * FROM [dbo].[MySourceTable]
As it is the only minimally-logged, bulk insert method within SQLDW, it’s the fastest way to get data into a table. If you have the table already exists and you want to wipe it and fill it with data, the fastest way to do so is to delete the table and recreate it using a CTAS. Performing a truncate/insert combination would be slower, as each row insert causes a write to the transaction log. SQLDW performs all standard actions as a transaction by default, so if you have a huge insert statement and something goes wrong, be prepared for a lengthy rollback process.
The table creates by a CTAS statement infers the schema from the query, so you need to be explicit with ISNULLs, CASTs and anything needed to point the query in the right direction. This is where the bulk of the data processing happens – the select part of the CTAS both defines the destination table and carries out the data transformations, all as a single step.
If you’ve ever used “SELECT field, field2 INTO [dbo].[NewTable] FROM [dbo].[SourceTable]” then you’ll have a pretty good idea of how it’ll work. But if you ran the two side by side, CTAS would perform faster as, again, it is specifically treated differently by the SQLDW engine.
What does this mean to our traditional ETL pattern? If you’re following the standard approach of having intermediary tables between data processing steps (ie: Staged data, cleaned data, transformed data and so on), these transient tables can actually be deleted between loads. They won’t exist in your database project. They won’t exist until your load process has been run.
A CTAS to ‘Clean’ our fact table would be:
BEGIN TRY --Primary CTAS to insert data from external table into strongly typed Clean table CREATE TABLE Clean.MyTable WITH( HEAP, DISTRIBUTION = ROUND_ROBIN) AS SELECT ISNULL(CAST(Column_0 as INT),-1) TableId, CAST(Column_1 as VARCHAR(50)) SomeTextField, CAST(Column_2 as DECIMAL(12,5)) SomeNumber FROM SRC.MySourceTable OPTION (LABEL = 'Clean.LoadMyTable.CTAS'); END TRY BEGIN CATCH --CTAS Failed, mark process as failed and throw error SET @ErrorMsg = 'Error loading table "MyTable" during Cleaning CTAS: ' + ERROR_MESSAGE() RAISERROR (@ErrorMsg, 16, 1) END CATCH
By including the CAST and ISNULL statements, I’m controlling the schema of the created tables. The resulting table would have the following definition:
CREATE TABLE [Clean].[MyTable] WITH ( HEAP, DISTRIBUTION = ROUND_ROBIN ) ( [TableId] INT NOT NULL, [SomeTextField] VARCHAR(50) NULL, [SomeNumber] NUMERIC(12,5) NULL );
By using CTAS wherever possible, you will maintain the speed of your data loads and avoid and issues around long-running transactions. An efficient SQLDW loading process contains ONLY CTAS functions.
For example – there is no such thing as a MERGE statement within SQLDW. In order to merge the results of one table into another, you can write a CTAS that selects a union of the two tables and inserts them into a new table. You then drop the old table and rename your newly created table in it’s stead.
There are many similar patterns that will help you around any data movement problem – we’ll discuss them in later posts in this series.
For more information about the CTAS statement, see the Microsoft Docs.
Introduction to Data Wrangler in Microsoft Fabric
What is Data Wrangler? A key selling point of Microsoft Fabric is the Data Science
Jul
Autogen Power BI Model in Tabular Editor
In the realm of business intelligence, Power BI has emerged as a powerful tool for
Jul
Microsoft Healthcare Accelerator for Fabric
Microsoft released the Healthcare Data Solutions in Microsoft Fabric in Q1 2024. It was introduced
Jul
Unlock the Power of Colour: Make Your Power BI Reports Pop
Colour is a powerful visual tool that can enhance the appeal and readability of your
Jul
Python vs. PySpark: Navigating Data Analytics in Databricks – Part 2
Part 2: Exploring Advanced Functionalities in Databricks Welcome back to our Databricks journey! In this
May
GPT-4 with Vision vs Custom Vision in Anomaly Detection
Businesses today are generating data at an unprecedented rate. Automated processing of data is essential
May
Exploring DALL·E Capabilities
What is DALL·E? DALL·E is text-to-image generation system developed by OpenAI using deep learning methodologies.
May
Using Copilot Studio to Develop a HR Policy Bot
The next addition to Microsoft’s generative AI and large language model tools is Microsoft Copilot
Apr