Origins
Dan Linstedt is the inventor of the Data Vault Modelling Technique. His journey started in the 90s whilst building a sizeable Enterprise Data Warehouse (EDW) for a large US defence contractor. He was well versed in the traditional modelling techniques (Third Normal Form and Dimensional Modelling). However, the cost of refactoring these models, especially as business requirements evolved, become problematic.
As a result, he set out to find a more proficient way of modelling data that provided him the flexibility he needed. He spent a decade, between 1990 and 2000, during which he was able to create the Data Vault modelling technique. In 2001, he published a series of blogs introducing the world to data vault.
What is the Data Vault Modelling Technique?
- Hubs
- Links and
- Satellites
Hub – Narrow tables that list key business identifiers, including the business key – which sits at the heart of a Data Vault. They allow you to uniquely and reliably identify a given entity over time. A true business key has real-world meaning. Not only does it maintain its meaning from one source system to another, but its grain is also consistent across source systems. This allows you can create a single Hub object in the data vault model from which you can integrate data from different source systems.
Links – Tables which instantiate all the relationships between entities.
Satellite – Tables which store descriptive attributes related to either a Hub or a Link.
The Data Vault methodology adheres to Codd’s theory of normalisation. The first normal form requires a table to have a primary key whose value determines the value of every other attribute in the table. In Data Vault, the hub object holds the keys for all the objects and the satellites have the attributes that are fully dependent on that key.
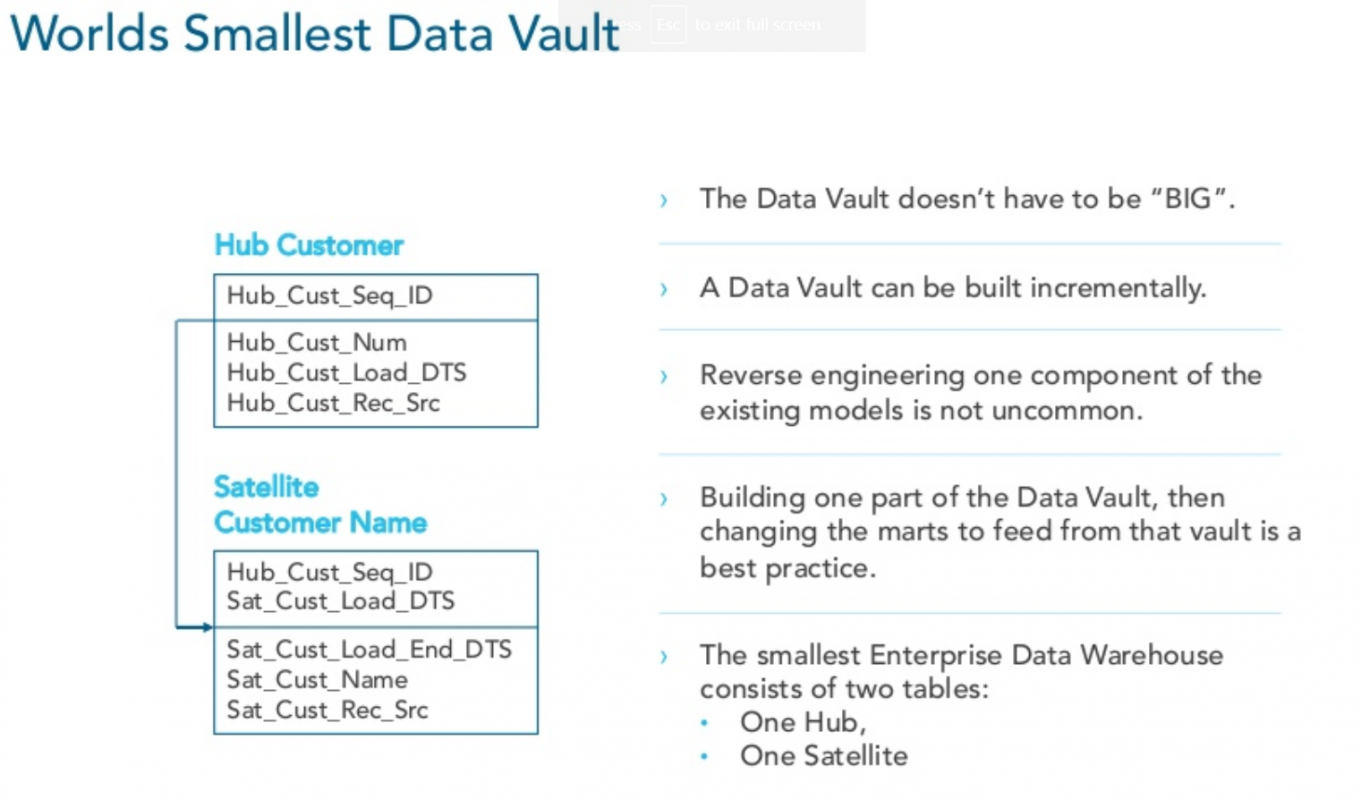
Example of a Data Vault taken from Kent Graziano’s blog
Brief overview of Traditional Modelling Techniques
Dimension Modelling, according to Ralph Kimball (2003), divides
“the world into measurements and context. Measurements are usually numeric and taken repeatedly. Numeric measurements are facts. Facts are always surrounded by mostly textual context that’s true at the moment the fact is recorded.”
Dimensional modelling is optimised for analytics, its time variant nature allows you to view changes over time.
By comparison, the third normal form is optimised for transactions (Insert, Update, Delete) within OLTP databases. They struggle to track change over time. OLTP databases are not designed to handle all the data amassed for analytics, which tend to store the same record multiple times whenever there is a change event.
Moreover, if you try to run a report using OLTP and want all the history that goes along with it, (captured using snapshot dates), with all the joins you’ll have to perform, you’d struggle to deliver insights in a performant way.
It’s clear that the dimensional modelling technique and the third normal form serve different purposes. We’ll soon see what purpose a data vault serves, as well as, where it fits within an organisation’s EDW. We’ll start by looking at the ways in which the data vault methodology seeks to address some of the limitations of the traditional modelling techniques.
Data Vault addresses limitations within Traditional Modelling Techniques
The Data Vault methodology addresses a common limitation that relates to the third normal form approach. More specifically, tracking changes within a model in the third normal form through snapshot dates demands increasingly complex and hard to maintain queries when obtaining a “single point in time” view of the data, e.g. last week. This is especially truly when data changes at different rates in different tables.
This problem is further compounded when integrating data from various source systems into said model. There is potential for the source table to change structure, e.g. new attributes being added. Thus making it expensive and time consuming to refactor the model.
The Data Vault methodology also addresses a common limitation that relates to the dimensional model approach. There are many good things to say about dimensional modelling, it’s a perfect fit for doing analytics, it’s easy for business analysts to understand, it’s performant over large sets of data, the list goes on.
That said, the data vault methodology addresses the limitations of having a “fixed” model. Dimensional modelling’s resilience to change or “graceful extensibility”, as some would say, is well documented. It’s capable of handling changing data relationships which can be implemented without affecting existing BI apps or query results. For example, facts consistent with the grain of an existing fact table can be added by creating new columns. Moreover, dimensions can be added to an existing fact table by creating new foreign key columns, presuming they don’t alter the fact table’s grain.
However, say you have a fact table linked to 5 dimensions all coming from a single source system, and suppose one of those dimensions is a customer table that has 10 attributes. In addition, suppose there’s a new business requirement that involves integrating a 2nd source system. This time, the customer table has 20 attributes, some of which might be equivalent to the 10 that you already have, but the other 10 are new, how would you handle that in a dimensional model?
Assuming all columns are required, you’d need to refactor the dimension by modifying your ETL process in order to take in the new attributes. You must then decide which source system to report on where an attribute appears in both systems. This adds a degree of complexity which is compounded as you increase the number of source systems.
The data vault approach was designed to eliminate this refactoring giving you the ability to integrate new sources more quickly than traditional models. It serves its purpose as a business-aligned resilient model. Business-aligned in its use of business/natural keys which maintain their meaning/grain across systems. Resilient in its ability to use those keys in integrating across multiple sources, based on a common set of attributes that you can align on, as business requirements evolve.
From a performance point of view, the data vault approach does necessitate the creation of more tables, more than what you’d typically see in a dimensional model. As such, writing reports on top of a data vault is not a best practice. It is best practice to project your data vault into several data marts, each transformed into a star schema. In this way, your data is optimised for reporting and analytics. Placing a view on top of a data vault is another pattern you might see; in this instance the views maintain the look and feel of a dimensional model.
Where does a Data Vault fit?
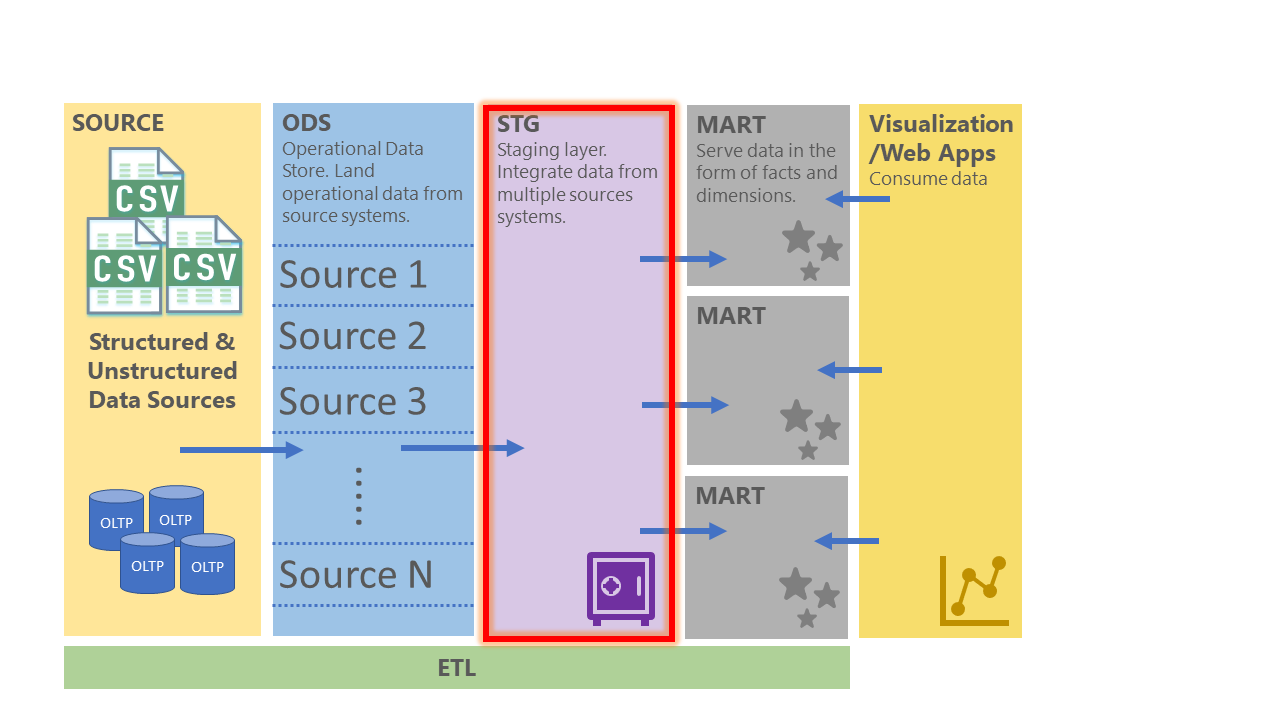
The below data architecture should give a clearer picture of where a data vault fits within the EDW. For landing your operational data you have the operational database store where data from your source systems is stored. The ODS layer is the data source for the EDW. The Staging (STG) layer is where a Data Vault would sit, right at the core of your EDW storing the history of all the time variant data. The Marts serve the data in the form of facts and dimensions which feed into the Visualization layer.
Conclusion
By now we should be familiar with the different roles played by traditional modelling techniques (third normal form’s support for transactions and dimensional modelling’s support for analytics). We’ve also seen that the data vault methodology is really about responding to changing business requirements faster whilst removing the cost of refactoring experienced within dimensional modelling. The key takeaway is that each modelling technique is optimised for serving a specific purpose. It goes without saying, therefore, that choosing one technique over another and the benefit you’ll reap, to a large extent, depends on the business requirements.
For more information about the services and industries Adatis can help with, please visit our main website here
Introduction to Data Wrangler in Microsoft Fabric
What is Data Wrangler? A key selling point of Microsoft Fabric is the Data Science
Jul
Autogen Power BI Model in Tabular Editor
In the realm of business intelligence, Power BI has emerged as a powerful tool for
Jul
Microsoft Healthcare Accelerator for Fabric
Microsoft released the Healthcare Data Solutions in Microsoft Fabric in Q1 2024. It was introduced
Jul
Unlock the Power of Colour: Make Your Power BI Reports Pop
Colour is a powerful visual tool that can enhance the appeal and readability of your
Jul
Python vs. PySpark: Navigating Data Analytics in Databricks – Part 2
Part 2: Exploring Advanced Functionalities in Databricks Welcome back to our Databricks journey! In this
May
GPT-4 with Vision vs Custom Vision in Anomaly Detection
Businesses today are generating data at an unprecedented rate. Automated processing of data is essential
May
Exploring DALL·E Capabilities
What is DALL·E? DALL·E is text-to-image generation system developed by OpenAI using deep learning methodologies.
May
Using Copilot Studio to Develop a HR Policy Bot
The next addition to Microsoft’s generative AI and large language model tools is Microsoft Copilot
Apr