Data Science can fit seamlessly within the ecosystem of the data lake, whether this is through HDInsight or the extensibility of Azure Data Lake Analytics and U-SQL. This blog will give a brief overview of what Data Science is; how to link Data Science toolkits to the Azure Data Lake; and best practices for managing the data output from experiments.
Data Science
Data Science is the relatively new kid on the block. One way to consider data science is as an evolutionary step in interdisciplinary fields like business analysis that incorporate computer science, modelling, statistics, analytics, and mathematics.
At its core, data science involves using automated methods to analyse massive amounts of data and to extract insight from them. Data science is helping to create new branches of science, and influencing areas of social science and the humanities. The trend is expected to accelerate in the coming years as data from mobile sensors, sophisticated instruments, the web, and more, grows.
Data Science In The Data Lake
The nature of the Azure Data Lake Store lends itself to Data Science in that it can hold any data, which the data scientist will want to access, transform and analyse.
HDInsight contains many implementations for data science, such as Spark, R Server and others. Hooking HDInsight to Azure Data Lake Store is pretty simple and follows these steps:
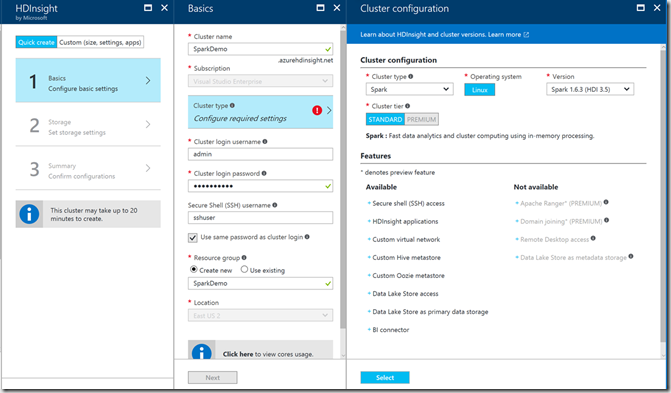
In the Azure Portal Marketplace, select HDInsight which will bring up a series of blades. In this blog, I will be using Spark as my cluster type on HDInsight.

In the storage settings you can then link your HDInsight cluster to Azure Data Lake Store

Confirm your configuration on the next blade and wait around 20 minutes for your cluster to deploy and you’re good to go!
With Azure Data Lake Analytics, you incorporate data science by extending the capabilities of U-SQL and you do this by installing a series of files.
Open up your Azure Data Lake Analytics account and click on Sample Scripts at the top. This will bring forward the following blade

From there you’ll want to click on the U-SQL Advanced Analytics tab, which will copy about 1.5GB of files to the default Azure Data Lake Store associated to your ADLA account. This will take about 3 minutes to complete.
When it’s finished copying the files it will then call a job to register the extension, which can be found in the assemblies folder of the master database.

More resources about extensibility of U-SQL can be found here:
https://blogs.msdn.microsoft.com/azuredatalake/2017/03/10/using-custom-python-libraries-with-u-sql/
The Laboratory
Within Azure Data Lake Store, Folder and File Management is incredibly important for a well running data lake. See my blogs on Storage and Best Practices and Shaping The Lake for more information on how to set up your Azure Data Lake Store.
The Laboratory is an area to be exclusively used by a data scientist. It’s an area where they can persist the results of experiments and data sets without impacting the day-to-day operations within the data lake or other data scientists. The laboratory is organised in to two broad area: Desks and Exhibits.
Desks contain personal workspaces, the contents of which can be organised however the person wishes. It can be as well organised, or disorganised, as the person themselves. The Exhibit contains data sources produced in the Laboratory which are ready to be consumed by other users or systems. Both of which are laid out below.

As always, if you have any feedback or comments do let me know!
Introduction to Data Wrangler in Microsoft Fabric
What is Data Wrangler? A key selling point of Microsoft Fabric is the Data Science
Jul
Autogen Power BI Model in Tabular Editor
In the realm of business intelligence, Power BI has emerged as a powerful tool for
Jul
Microsoft Healthcare Accelerator for Fabric
Microsoft released the Healthcare Data Solutions in Microsoft Fabric in Q1 2024. It was introduced
Jul
Unlock the Power of Colour: Make Your Power BI Reports Pop
Colour is a powerful visual tool that can enhance the appeal and readability of your
Jul
Python vs. PySpark: Navigating Data Analytics in Databricks – Part 2
Part 2: Exploring Advanced Functionalities in Databricks Welcome back to our Databricks journey! In this
May
GPT-4 with Vision vs Custom Vision in Anomaly Detection
Businesses today are generating data at an unprecedented rate. Automated processing of data is essential
May
Exploring DALL·E Capabilities
What is DALL·E? DALL·E is text-to-image generation system developed by OpenAI using deep learning methodologies.
May
Using Copilot Studio to Develop a HR Policy Bot
The next addition to Microsoft’s generative AI and large language model tools is Microsoft Copilot
Apr