
Previously, I provided a quick overview of what is currently available in the Microsoft Fabric public preview. Today, I’ll present how to build a lambda architecture using Synapse Analytics and Microsoft Fabric.
Before starting, here’s some basic information. Synapse Analytics is a platform as a service (PaaS) offering that combines enterprise data warehousing with Big Data analytics. It was Microsoft’s first attempt to unify Data Factory, Data Warehousing, Data Science and Power BI under a single platform.

@Credit: Microsoft
Lambda architecture is a data driven architecture designed to process massive quantities of data that consists of three distinct layers, batch, serving and speed. The batch and serving layer represent the traditional batch-processing data pipelines, while the speed layer provides access to stream-processing methods to handle real-time data.

Microsoft’s Fabric and the Future of Synapse Analytics
Now that the basics are covered, let’s dissect the architecture below. Please bear in mind that there are different alternatives to deliver a lambda architecture, however, for the sake of this article, we will suggest a Synapse Analytics based design, so that we have a like for like comparison with Fabric.
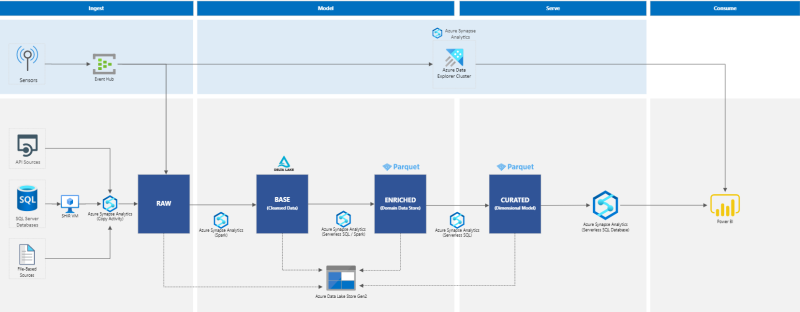
In light blue we have the stream-processing layer and in light grey the batch-processing layer. The fast pacing events are captured by Event Hub and then streamed to ADLS Gen2 for batch processing and into Azure Data Explorer. Using Azure Synapse Data Explorer, Data Analysts can query the fast pacing information and create Power BI visualisations for easy end user consumption.
In the batch layer, master data can be consumed from a variety of sources, including on-prem, and copied to the data lake using Synapse Pipelines. After landing the data in the RAW layer of the data lake, a spark notebook is triggered to validate the data integrity and to perform cleaning operations. At this point, we can follow one of two approaches:
1) store the data in a Dedicated SQL Pool, which follows a more traditional approach where the data is stored in a database and SQL is used to build the dimensional model
or
2) use a Synapse Serverless SQL Pool and take advantage of the cost-effective lakehouse architecture, keeping the data in the lake and use spark notebooks or serverless SQL to transform the data.
The above architecture represents the latter approach. Enriched (contains data close to its final format but without SCDs applied and not yet related using surrogate keys) and Curated (contains the final star-schema dimensional model with surrogate keys and SCD applied) objects are created before serving the data model via a Serverless SQL database to Power BI.
Although Synapse Analytics tackles some of the infrastructure and integration problems, there are still a fair number of challenges that have to be addressed by experienced data engineers, which is why, Microsoft introduced Fabric. There may be fears about what is happening with Synapse in the future, especially for those who built or were planning to build a new platform using Synapse Analytics, however, Microsoft already confirmed they don’t have plans to decommission it and is here to stay for a long time. One caveat to the comment though, is that, given Microsoft’s roadmap is built around Fabric, investment into new Synapse Analytics capabilities is likely not to happen.
Exploring the Lambda Architecture with Microsoft’s Fabric
So, how different/alike is a lambda architected based in Fabric? The first thing to note is that all data residing in Fabric is stored within OneLake (except for shortcuts to external sources). Starting with the speed layer, we introduce the newly Event Stream service, the no-code evolution of Azure Stream Analytics. The streamed data can be stored in a Kusto DB, where Data Analysts can use KQL and SQL (with some limitations) to query the data and build insights that can be exported to Power BI or store the events directly in the Lakehouse as a Delta table.

Moving to the batch layer, we have a few differences. Data can be ingested via Dataflow Gen2 (equivalent to Mapping Data Flows) or Data Pipelines. The newly Data Factory workload is being built from the ground, so I won’t make much fuss about what is missing, however, here are a couple of features that could impact your workflow if you’re planning to use Data pipelines:
- It is not possible to connect to on-premises data sources (in the future it will be available via on-premises data gateway). The workaround is to copy the data to a data lake and use Shortcuts
- MVNet and Private Endpoints are not supported and not in the roadmap
- It is not possible to schedule a pipeline and dynamically pass parameters like it happens with ADF/Synapse Pipelines triggers. If necessary, these will have to be hardcoded in the pipeline
- It is not possible to dynamically execute different notebooks from the pipeline. Each activity requires the notebook to be hardcoded
- The backend json in the pipeline is read-only. To duplicate a pipeline, a Save option can be used, however, it is not as flexible as the alternative offered in ADF/Synapse pipelines
Exploring Data Storage and Security in Microsoft’s Fabric
Just like Synapse Analytics, data can be stored in Fabric using a Synapse Warehouse or a Lakehouse. The first approach is equivalent to the Dedicated SQL Pool, except there’s no need to worry about partitioning and distribution strategies and the data is persisted in OneLake as a delta table. The Lakehouse is suitable for data engineers who don’t want to be restricted to a single language and prefer the flexibility of the notebooks. The latter is the approach represented in the architecture above.
The batch data can be stored in single or multiple lakehouses and as Files or Tables. The newly ingested data can be stored as Files using the original format, however, from this point it is advised that the entities are stored as delta tables to take advantage of the performance and interoperability between the services. To allow notebooks to access the data from Kusto DB, a shortcut can be used; the data will be added to the lakehouse as parquet files and not as a delta table.
Although the architecture represents BASE, ENRICHED and CURATED as separate boxes, in reality, all tables live under the same dbo schema. It is recommended that a proper naming convention is adopted to correctly identify the different curation layers. As opposed to ADLS Gen2 where it is possible to set RBAC policies as granular as at file level, Fabric security is set at workspace level (full details can be found here).
A user added as a Viewer will only have access to the data in the lakehouse via the SQL endpoint, which means, access to entities stored in the File area will not be available. For a more granular access, SQL permissions are required. (E.g. create enriched schema, create enriched views and deny access to dbo schema).
If with Synapse Analytics the question of using Power BI Premium or Azure Analysis Services to store the enterprise semantic model was still open for discussion, with Fabric, that becomes a moot point. Having that said, although the Fabric entry level pricing can be very appealing, small organisations might struggle to afford a Power BI Premium capacity, which could hinder Fabric’s adoption. One possible alternative could be the combination of PPU licenses with Fabric capacities, however, that comes with the known PPU limitations.
I hope you found this article helpful. If you have any questions please feel free to drop me a message. If you are interested to know how you can leverage Fabric to your business, please get in touch and learn more about our Microsoft Fabric offerings.
Introduction to Data Wrangler in Microsoft Fabric
What is Data Wrangler? A key selling point of Microsoft Fabric is the Data Science
Jul
Autogen Power BI Model in Tabular Editor
In the realm of business intelligence, Power BI has emerged as a powerful tool for
Jul
Microsoft Healthcare Accelerator for Fabric
Microsoft released the Healthcare Data Solutions in Microsoft Fabric in Q1 2024. It was introduced
Jul
Unlock the Power of Colour: Make Your Power BI Reports Pop
Colour is a powerful visual tool that can enhance the appeal and readability of your
Jul
Python vs. PySpark: Navigating Data Analytics in Databricks – Part 2
Part 2: Exploring Advanced Functionalities in Databricks Welcome back to our Databricks journey! In this
May
GPT-4 with Vision vs Custom Vision in Anomaly Detection
Businesses today are generating data at an unprecedented rate. Automated processing of data is essential
May
Exploring DALL·E Capabilities
What is DALL·E? DALL·E is text-to-image generation system developed by OpenAI using deep learning methodologies.
May
Using Copilot Studio to Develop a HR Policy Bot
The next addition to Microsoft’s generative AI and large language model tools is Microsoft Copilot
Apr