
Introduction
When it comes to conquering the data analytics landscape in Databricks, two heavyweights, Python and PySpark, take centre stage. Python, the versatile darling of data scientists and analysts, and PySpark, the powerhouse built on Apache Spark, join forces to tackle distributed computing challenges. In this post, we’ll dive into a practical comparison of Python and PySpark in the Databricks environment, showcasing their strengths through practical code examples.
Python: The Jack-of-All-Trades
Python has long been cherished for its readability, simplicity, and extensive library support, making it a go-to language for various data-related tasks. In Databricks, Python can be seamlessly integrated into the analytics workflow, allowing users to leverage its rich ecosystem for data manipulation, analysis, and visualisation.
The following Python code snippet demonstrates a basic data manipulation operation using the pandas library. It calculates the total amount spent by each customer.
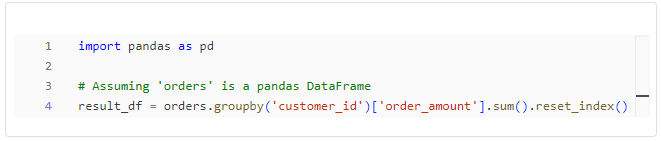
Code Snippet 1: Basic Python DataFrame Operation
PySpark: Scaling Python to the Clouds
PySpark, a mix of Python and Apache Spark, allows us to tackle big data with ease.
The main benefit of using PySpark over traditional Python for big data processing tasks lies in its ability to leverage the distributed computing capabilities of Spark. PySpark allows users to seamlessly transition from working with small datasets in Python to processing massive datasets across a Spark cluster.
This PySpark code mirrors the functionality of the Python example but operates on a PySpark DataFrame. The agg function is used to apply aggregate functions like sum, showcasing the seamless integration of Python syntax with PySpark’s distributed computing capabilities.
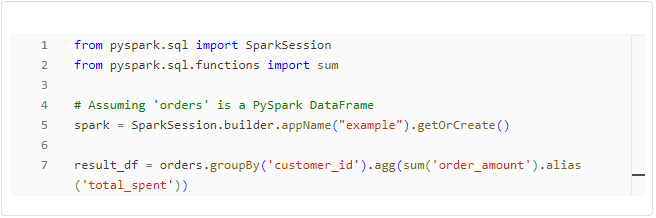
Code Snippet 2: Basic PySpark DataFrame Operation
Exploring Delta Lake Operations
We’ve seen two powerful tools we can utilise in the Databricks environment, so let’s look at a practical example of what each one brings to the table. To do that, we are going to explore Delta Lake operations using both Python and PySpark – but what is the Delta Lake?
The Delta Lake is an open-source storage layer used for managing big data workloads in Apache Spark environments. Serving as a cornerstone for data engineers and analysts, Delta Lake brings ACID transactions to large-scale data processing.
Delta Tables and Managed Databases
Before diving into the comparison, let’s establish a foundational understanding of Delta Tables and managed databases. Delta Tables, a cornerstone of Delta Lake, provide ACID transactions, schema enforcement, and time travel capabilities. Managed databases, on the other hand, are saved in the Hive metastore, with a default database named “default.”
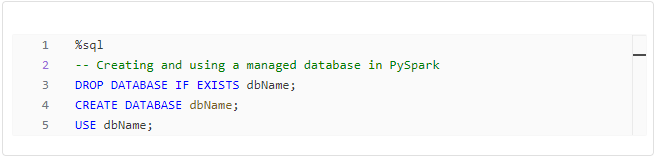
By using managed databases, you can avoid the hassle of specifying the database name every time, streamlining your queries.
Querying Delta Tables
Querying Delta Tables is a fundamental operation in data analytics. PySpark provides two ways to reference Delta Tables: by table name and by path. The preferred method is by table name as it leverages the Hive Metastore, ensuring that when a named table is dropped, the associated data is also removed.
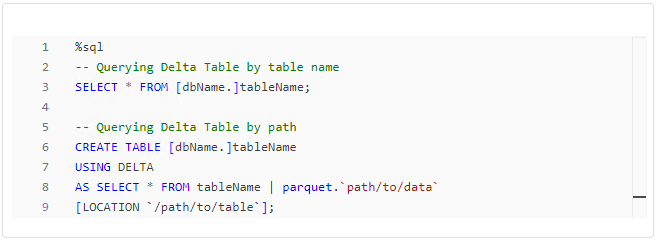
Choosing the appropriate method depends on your use case, with named tables offering better manageability and data integrity.
Converting Parquet Tables to Delta Lake Format
Converting existing Parquet tables to Delta Tables is a common scenario, to leverage the enhanced performance and flexibility of the Delta format. Both Python and PySpark offer ways to accomplish this task.
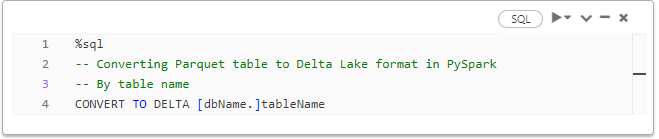
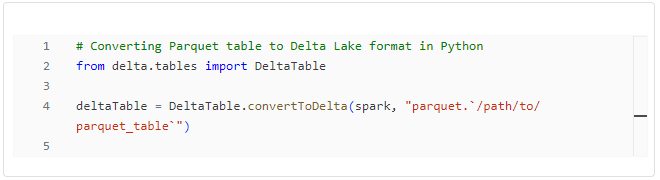
Both approaches offer flexibility, allowing you to choose based on your workflow and requirements. In my own experience, PySpark is a bid easier to read and understand. That, of course, depends on your personal taste and programming experience.
Creating Delta Tables with Python and PySpark
Creating Delta Tables involves defining schemas, and both Python and PySpark offer different approaches.
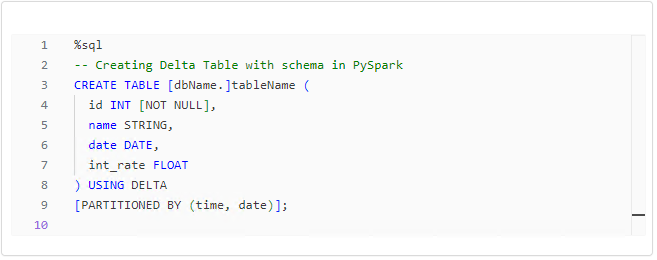
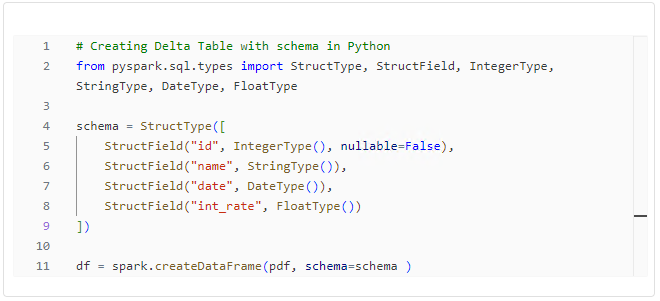
Choosing between the two approaches depends on your preference and the complexity of your schema. Its also important to note that using PySpark to create a table will actually create a table in the Hive metastore, which can be used outside the notebook.
On the other hand, if we create a data frame using Python it will be available only within the notebook, so we might need to use an extra command to store the data frame into a delta or parquet file for later use.
Copying Data into Delta Tables
Efficiently copying data into Delta Tables is crucial for maintaining data consistency. Both Python and PySpark offer methods to achieve this goal.
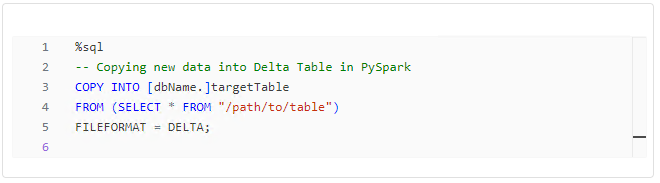
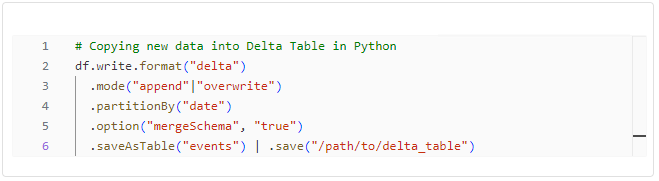
Whether you prefer SQL-like commands or a programmatic approach in Python, both options can accomplish the task.
Streaming Operations with Delta Tables
Streaming operations are gaining prominence in the data processing realm. PySpark and Python provide ways to read and write Delta Tables in a streaming fashion.
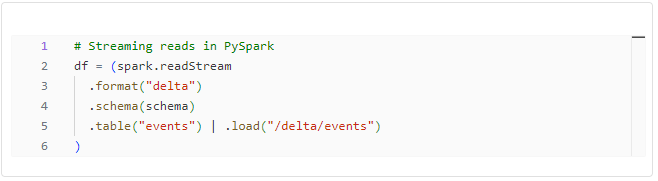
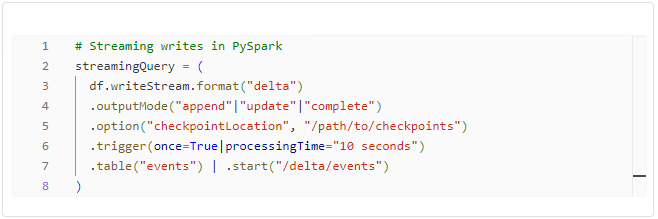
The Python counterpart provides a similar streamlined experience for streaming operations.
Conclusion
In the landscape of Delta Tables, the pivotal factor that will determine success in analytics and ML workflows is finding the tool that seamlessly blends flexibility, ease of use, and top-notch performance. Drawing from the examples explored, it’s evident that both Python and PySpark present robust solutions, each carrying its unique strengths. However, from my personal experience, PySpark wins this competition, because of its flexibility and ability to handle large-scale data engineering tasks.
Conversely, Python distinguishes itself with a concise and expressive syntax, making it the language of choice for data scientists and analysts seeking a streamlined workflow.
The decision between Python and PySpark ultimately depends on the specific needs of your data pipeline and the preferences and existing skill set of your team.
As we delve into Part 2 of this blog series, we will further explore additional functionalities within Databricks, including leveraging Python/PySpark for DDL commands, diving into Databricks Timetravel, and uncovering some performance optimisation tricks. Stay engaged for deeper insights into maximizing the potential of Delta Tables in your analytics and ML workflows!
Introduction to Data Wrangler in Microsoft Fabric
What is Data Wrangler? A key selling point of Microsoft Fabric is the Data Science
Jul
Autogen Power BI Model in Tabular Editor
In the realm of business intelligence, Power BI has emerged as a powerful tool for
Jul
Microsoft Healthcare Accelerator for Fabric
Microsoft released the Healthcare Data Solutions in Microsoft Fabric in Q1 2024. It was introduced
Jul
Unlock the Power of Colour: Make Your Power BI Reports Pop
Colour is a powerful visual tool that can enhance the appeal and readability of your
Jul
Python vs. PySpark: Navigating Data Analytics in Databricks – Part 2
Part 2: Exploring Advanced Functionalities in Databricks Welcome back to our Databricks journey! In this
May
GPT-4 with Vision vs Custom Vision in Anomaly Detection
Businesses today are generating data at an unprecedented rate. Automated processing of data is essential
May
Exploring DALL·E Capabilities
What is DALL·E? DALL·E is text-to-image generation system developed by OpenAI using deep learning methodologies.
May
Using Copilot Studio to Develop a HR Policy Bot
The next addition to Microsoft’s generative AI and large language model tools is Microsoft Copilot
Apr