Azure SQL DataWarehouse has had a lot of attention recently as a super-scalable SQL Server in Azure, But there’s not too much understanding about what is actually is. I could tell you it’s the cloud version of PDW/APS, although that requires a fair bit of background knowledge. Technically it’s a cloud-scalable T-SQL-based MPP platform… does that clear things up? No? Well let’s break that down – first let’s look at what MPP means…
MPP
I like to play this game at the start of Azure SQLDW sessions. I ask who has used an MPP system before, a couple of hands go up. I ask who has used an SMP system, a few hesitant hands are raised. I ask who has used a SQL Server before and suddenly we have a room full of waving hands.
Traditional SQL Server IS an SMP system. SMP stands for Symmetric Multi-Processing – so without really knowing it, we’re using SMP systems all the time. I’m hoping I can stop playing the wavy-hands game soon when everyone either knows this or has used SQLDW…
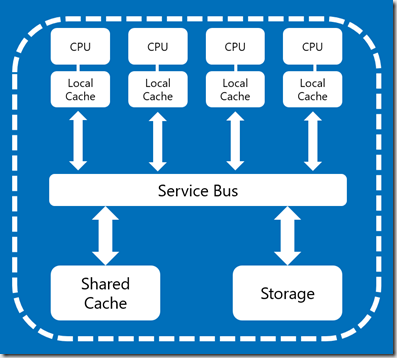
What SMP means is that you have one data store that is shared between all CPUs and a service bus to manage interactions. If you have a particular record in a table, each of the CPUs can access that at any time. If they all try to access it at once, then we need locking and queue management in the middle. Sure, you can be clever with your FileGroup/File structures and have parallel I/O reads, but all that storage is still shared across the CPUs.

Now we can add more and more compute to this solution, but there comes a point where the service bus is working too hard to try and balance everything out. Essentially you get diminishing returns on your hardware investment as it has to manage more complex interactions with your storage.
MPP, or Massively Parallel Processing, on the other hand, separates storage and aligns it to specific compute. What this means is each CPU can only access a certain set of records – but we know that there is no competition from other CPUs to access that storage. The idea being that each compute node does its job in isolation, then we can add the various results together to get our answer.

That’s an important point to remember – a single record is only held on ONE of the storage buckets (In most scenarios currently… we’ll get onto that in later posts)
The way we scale this is to add more compute notes and associated buckets. For example, if we had 4 Tbs of data, each of our storage buckets in the above example would be looking after 1.33Tb of data. If we add a further compute & storage combination and spread our data out, then each would be holding 1Tb of data. We can keep going – at 8 compute & storage combinations, each of our nodes will only be querying 500Gb of data and we will see performance increase as a result!
Our scaled-up MPP would look something like this:

The overall storage volume is the same, however it’s spread across more compute. So each compute finishes the job quicker, meaning we get our results faster!
Cloud Scalable
That’s the MPP part – so what about Cloud Scalable? Well we know that we can make it go faster by adding more compute nodes and spreading the data out across those nodes. But we can take this a step further in Azure – the compute nodes can be allocated to storage rather than redistributing data, so we can add and remove compute nodes dynamically.
Essentially, you take the compute to the storage – it’s a fundamental approach in big data to get real scalability. Moving data is expensive and slow, moving compute is quick, efficient and cheap if you have the right hardware setup. This also means that you can take compute away entirely when you’re not using it – you’ll still pay for the storage, but it’s a lot cheaper than having a server you’re not using!
Want your server to go faster for the next hour? Double the compute nodes! Not using it overnight? Turn it off! Doing a big data load over night? Turn the server back on at a high rate, blast through the processing then pause the compute again!

T-SQL Based
Finally – yes, it is indeed a SQL Server. However, it uses a specific version of the SQL Server engine, evolved from SQL Server PDW edition. This means that a lot of your favourite functionality is still there and works fine, however there are certain feature limitations due to the system’s parallel nature. They’re slowly going through and adding these features, but we won’t ever achieve full engine parity!
So – CTEs, window functions, aggregations, stored procs, views – these are all present and accounted for!
Identity columns, @@Rowcount, table-valued functions are a few which are not.
It’s a very familiar environment to anyone who develops in T-SQL, but it’s not exactly the same.
There we go. So now we can happily say that Azure SQL DataWarehouse is a cloud-scalable T-SQL-based MPP platform and not be left reeling.
Introduction to Data Wrangler in Microsoft Fabric
What is Data Wrangler? A key selling point of Microsoft Fabric is the Data Science
Jul
Autogen Power BI Model in Tabular Editor
In the realm of business intelligence, Power BI has emerged as a powerful tool for
Jul
Microsoft Healthcare Accelerator for Fabric
Microsoft released the Healthcare Data Solutions in Microsoft Fabric in Q1 2024. It was introduced
Jul
Unlock the Power of Colour: Make Your Power BI Reports Pop
Colour is a powerful visual tool that can enhance the appeal and readability of your
Jul
Python vs. PySpark: Navigating Data Analytics in Databricks – Part 2
Part 2: Exploring Advanced Functionalities in Databricks Welcome back to our Databricks journey! In this
May
GPT-4 with Vision vs Custom Vision in Anomaly Detection
Businesses today are generating data at an unprecedented rate. Automated processing of data is essential
May
Exploring DALL·E Capabilities
What is DALL·E? DALL·E is text-to-image generation system developed by OpenAI using deep learning methodologies.
May
Using Copilot Studio to Develop a HR Policy Bot
The next addition to Microsoft’s generative AI and large language model tools is Microsoft Copilot
Apr