I’ve recently been spending quite a bit of time on the Azure Databricks platform, and while learning decided it was worth using it to experiment with some common data warehousing tasks in the form of data cleansing. As Databricks provides us with a platform to run a Spark environment on, it offers options to use cross-platform APIs that allow us to write code in Scala, Python, R, and SQL within the same notebook. As with most things in life, not everything is equal and there are potential differences in performance between them. In this blog, I will explain the tests I produced with the aim of outlining best practice for Databricks implementations for UDFs of this nature.
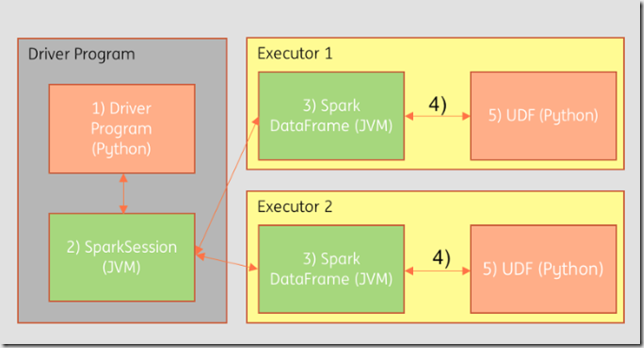
Scala is the native language for Spark – and without going into too much detail here, it will compile down faster to the JVM for processing. Under the hood, Python on the other hand provides a wrapper around the code but in reality is a Scala program telling the cluster what to do, and being transformed by Scala code. Converting these objects into a form Python can read is called serialisation / deserialisation, and its expensive, especially over time and across a distributed dataset. This most expensive scenario occurs through UDFs (functions) – the runtime process for which can be seen below. The overhead here is in (4) and (5) to read the data and write into JVM memory.

Using Scala to create the UDFs, the execution process can skip these steps and keep everything native. Scala UDFs operate within the JVM of the executor so we can skip serialisation and deserialisation.

Experiments
As part of my data for this task I took a list of company names from a data set and then run them through a process to codify them, essentially stripping out characters which cause them to be unique and converting them to upper case, thus grouping a set of companies together under the same name. For instance Adatis, Adatis Ltd, and Adatis (Ltd) would become ADATIS. This was an example of a typical cleansing activity when working with data sets. The dataset in question was around 2.5GB and contained 10.5m rows. The cluster I used was Databricks runtime 4.2 (Spark 2.3.1 / Scala 2.11) with Standard_DS2_v2 VMs for the driver/worker nodes (14GB memory) with autoscaling disabled and limited to 2 workers. I disabled the autoscaling for this as I was seeing wildly inconsistent timings each run which impacted the tests. The goods news is that with it enabled and using up to 8 workers, the timings were about 20% faster albeit more erratic from a standard deviation point of view.
The following approaches were tested:
- Scala program calls Scala UDF via Function
- Scala program calls Scala UDF via SQL
- Python program calls Scala UDF via SQL
- Python program calls Python UDF via Function
- Python program calls Python Vectorised UDF via Function
- Python program uses SQL
While it was true in previous versions of Spark that there was a difference between these using Scala/Python, in the latest version of Spark (2.3) it is believed to be more of a level playing field by using Apache Arrow in the form of Vectorised Pandas UDFs within Python.
As part of the tests I also wanted to use Python to call a Scala UDF via a function but unfortunately we cannot do this without creating a Jar file of the Scala code and importing it separately. This would be done via SBT (build tool) using the following guide here. I considered this too much of an overhead for the purposes of the experiment.
The following code was then used as part of a Databricks notebook to define the tests. A custom function to time the write was required for Scala whereas Python allows us to use %timeit for a similar purpose.
Scala program calls Scala UDF via Function
// Scala program calls Scala UDF via Function %scala def codifyScalaUdf = udf((string: String) => string.toUpperCase.replace(" ", "").replace("#","").replace(";","").replace("&","").replace(" AND ","").replace(" THE ","").replace("LTD","").replace("LIMITED","").replace("PLC","").replace(".","").replace(",","").replace("[","").replace("]","").replace("LLP","").replace("INC","").replace("CORP","")) spark.udf.register("ScalaUdf", codifyScalaUdf) val transformedScalaDf = table("DataTable").select(codifyScalaUdf($"CompanyName").alias("CompanyName")) val ssfTime = timeIt(transformedScalaDf.write.mode("overwrite").format("parquet").saveAsTable("SSF"))
Scala program calls Scala UDF via SQL
// Scala program calls Scala UDF via SQL %scala val sss = spark.sql("SELECT ScalaUdf(CompanyName) as a from DataTable where CompanyName is not null") val sssTime = timeIt(sss.write.mode("overwrite").format("parquet").saveAsTable("SSS"))
Python program calls Scala UDF via SQL
# Python program calls Scala UDF via SQL pss = spark.sql("SELECT ScalaUdf(CompanyName) as a from DataTable where CompanyName is not null") %timeit -r 1 pss.write.format("parquet").saveAsTable("PSS", mode='overwrite')
Python program calls Python UDF via Function
# Python program calls Python UDF via Function from pyspark.sql.functions import * from pyspark.sql.types import StringType @udf(StringType()) def pythonCodifyUDF(string): return (string.upper().replace(" ", "").replace("#","").replace(";","").replace("&","").replace(" AND ","").replace(" THE ","").replace("LTD","").replace("LIMITED","").replace("PLC","").replace(".","").replace(",","").replace("[","").replace("]","").replace("LLP","").replace("INC","").replace("CORP","")) pyDF = df.select(pythonCodifyUDF(col("CompanyName")).alias("CompanyName")).filter(col("CompanyName").isNotNull()) %timeit -r 1 pyDF.write.format("parquet").saveAsTable("PPF", mode='overwrite')
Python program calls Python Vectorised UDF via Function
# Python program calls Python Vectorised UDF via Function from pyspark.sql.types import StringType from pyspark.sql.functions import pandas_udf, col @pandas_udf(returnType=StringType()) def pythonCodifyVecUDF(string): return (string.replace(" ", "").replace("#","").replace(";","").replace("&","").replace(" AND ","").replace(" THE ","").replace("LTD","").replace("LIMITED","").replace("PLC","").replace(".","").replace(",","").replace("[","").replace("]","").replace("LLP","").replace("INC","").replace("CORP","")).str.upper() pyVecDF = df.select(pythonCodifyVecUDF(col("CompanyName")).alias("CompanyName")).filter(col("CompanyName").isNotNull()) %timeit -r 1 pyVecDF.write.format("parquet").saveAsTable("PVF", mode='overwrite')
Python Program uses SQL
# Python Program uses SQL sql = spark.sql("SELECT upper(replace(replace(replace(replace(replace(replace(replace(replace(replace(replace(replace(replace(replace(replace(replace(replace(CompanyName,' ',''),'&',''),';',''),'#',''),' AND ',''),' THE ',''),'LTD',''),'LIMITED',''),'PLC',''),'.',''),',',''),'[',''),']',''),'LLP',''),'INC',''),'CORP','')) as a from DataTable where CompanyName is not null") %timeit -r 1 sql.write.format("parquet").saveAsTable("SQL", mode='overwrite')
Results and Observations

It was interesting to note the following:
- The hypothesis above does indeed hold true and the 2 methods which were expected to be slowest were within the experiment, and by a considerable margin.
- The Scala UDF performs consistently regardless of the method used to call the UDF.
- The Python vectorised UDF now performs on par with the Scala UDFs and there is a clear difference between the vectorised and non-vectorised Python UDFs.
- The standard deviation for the vectorised UDF was surprisingly low and the method was performing consistently each run. The non-vectorised Python UDF was the opposite.
To summarise, moving forward – as long as you adopt to writing your UDFs in Scala or use the vectorised version of the Python UDF, the performance will be similar for this type of activity. Its worth noting to definitely avoid writing the UDFs as standard Python functions due to the theory and results above. Over time, across a complete solution and with more data, this time would add up.
Introduction to Data Wrangler in Microsoft Fabric
What is Data Wrangler? A key selling point of Microsoft Fabric is the Data Science
Jul
Autogen Power BI Model in Tabular Editor
In the realm of business intelligence, Power BI has emerged as a powerful tool for
Jul
Microsoft Healthcare Accelerator for Fabric
Microsoft released the Healthcare Data Solutions in Microsoft Fabric in Q1 2024. It was introduced
Jul
Unlock the Power of Colour: Make Your Power BI Reports Pop
Colour is a powerful visual tool that can enhance the appeal and readability of your
Jul
Python vs. PySpark: Navigating Data Analytics in Databricks – Part 2
Part 2: Exploring Advanced Functionalities in Databricks Welcome back to our Databricks journey! In this
May
GPT-4 with Vision vs Custom Vision in Anomaly Detection
Businesses today are generating data at an unprecedented rate. Automated processing of data is essential
May
Exploring DALL·E Capabilities
What is DALL·E? DALL·E is text-to-image generation system developed by OpenAI using deep learning methodologies.
May
Using Copilot Studio to Develop a HR Policy Bot
The next addition to Microsoft’s generative AI and large language model tools is Microsoft Copilot
Apr