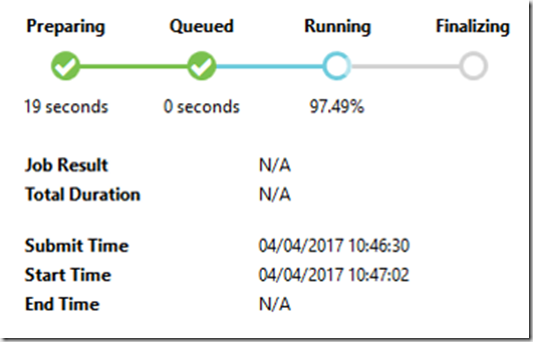
In this blog we will deep dive into the job execution of the Azure Data Lake Analytics (ADLA). If you’ve used ADLA you will have come across the following image:

This is the graphical representation of the job execution. But what is is doing at each stage?
Preparing
The job execution begins with the authoring of the U-SQL script. The U-SQL script itself is the logical plan of how you intend to transform input data into output data. The script gets compiled, which will translate your U-SQL script primarily into C#, as well as a few other items such as XML- which will contain metadata information and the job graph. Once compiled it will create an initial plan – which will then be optimised thus producing an optimised plan. If it fails at this stage it will mostly be down to your U-SQL script failing to compile successfully. Fortunately, the error codes at this stage are fairly helpful and will indicate the line in question.
Queued
Once compiled and optimised the job progresses to the queued stage. There are a few things which can cause the a job to queue and these are:
- Running Jobs
- The default setting per subscription is 3. So if you or someone else in your subscription is already running a series of jobs, your job will be queued until at least one of them completes
- Higher priority jobs
- As the queue is ordered by job priority, with loser numbers having a higher priority, other jobs can jump to the top of the queue thus forcing your job to queue for longer
- Lack of resources
- Even if there are no running jobs and there are no jobs ahead of yours in the queue, your job will continue to queue if there are not enough Azure Data Lake Analytic Units (ADLAUs) to start the job.
Running
Once the job has finished queuing it will run. The Job Manager allocates vertexes, which are collections of data to be processed, to the ADLAUs and uses YARN to orchestrate it. The vertexes will then execute. At this stage, if there is a vertex failure you can download the vertex locally and debug in visual studio.
When the vertexes have successfully completed you will be able to consume the end product – either locally, if you have run the job locally, or in the Azure Data Lake Store.
Conclusion

The above process can be visualised in this graph. Knowing how ADLA executes your job is the first of many steps to being able to write performant U-SQL and debug effectively. Be on the look out for more blogs on the technical deep dive into ADLA!
Introduction to Data Wrangler in Microsoft Fabric
What is Data Wrangler? A key selling point of Microsoft Fabric is the Data Science
Jul
Autogen Power BI Model in Tabular Editor
In the realm of business intelligence, Power BI has emerged as a powerful tool for
Jul
Microsoft Healthcare Accelerator for Fabric
Microsoft released the Healthcare Data Solutions in Microsoft Fabric in Q1 2024. It was introduced
Jul
Unlock the Power of Colour: Make Your Power BI Reports Pop
Colour is a powerful visual tool that can enhance the appeal and readability of your
Jul
Python vs. PySpark: Navigating Data Analytics in Databricks – Part 2
Part 2: Exploring Advanced Functionalities in Databricks Welcome back to our Databricks journey! In this
May
GPT-4 with Vision vs Custom Vision in Anomaly Detection
Businesses today are generating data at an unprecedented rate. Automated processing of data is essential
May
Exploring DALL·E Capabilities
What is DALL·E? DALL·E is text-to-image generation system developed by OpenAI using deep learning methodologies.
May
Using Copilot Studio to Develop a HR Policy Bot
The next addition to Microsoft’s generative AI and large language model tools is Microsoft Copilot
Apr