The last time I gave a SQLDW conference talk, one of the audience members commented that I probably like Polybase a little bit too much. But I disagree, I love it just as much as it deserves!
In a nutshell:
“Polybase is by far the fastest way to import/export data from SQLDW. If you’re loading any reasonably sized data volume, you should be using Polybase”
That’s not a quote – I just thought it would be more impactful looking like one!
For those of a traditional “Big Data” background, Polybase is essentially the same as an external Hive table, embedded into a traditional relational database.
For everyone else – Polybase is a special kind of SQL table. It looks like a table, it has columns and you can run normal T-SQL on it. However, instead of holding any data locally, your query is converted into map-reduce jobs against flat files – even those in sub-folders. For me, this is mind-bogglingly cool – you can query thousands of files at once by typing “select * from dbo.myexternaltable”.
Why Use It?
Polybase has some limitations, it’s true. I’ve included a section below discussing these. However, the other data import options are more limited.
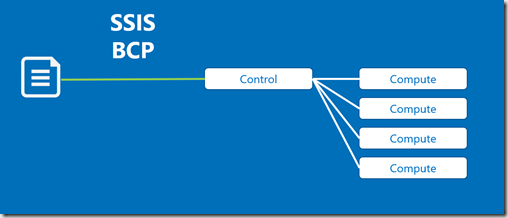
SQLDW has two different types of server within its architecture – a single Control node that orchestrates and aggregates, and a variable number of Compute nodes linked to your current DWU level.
Any data loading method that ‘pushes’ data to the SQLDW will be handled by the control node. This includes all current ETL tools – SSIS dataflows, the staple diet of MS BI developers for many years now – will encounter a row throughput bottleneck when inserting rows because of this.
Whether you’re using BCP, SSIS or a high-performance ETL solution – you’re going to his this bottleneck:

Because of this – it doesn’t matter how you scale the warehouse. No matter how many compute nodes you have, the initial data throughput won’t go any faster.
What we want is a data import method that scales – one that has a predictable increase in performance as we add compute nodes (or DWUs). This is where Polybase comes in.

Each compute node has a Hadoop File System (HDFS) bridge – essentially a map-reduce engine – included. This gives it external reader threads. For each compute node, you can be reading 8 different flat files. Raising the DWU level, adds additional external readers, speed import speed increases. This is the ONLY scalable data loading approach.
Polybase Performance Patterns
We’re settled on Polybase then – but how do you get the most out of Polybase?
To properly optimise Polybase, you should consider how it accesses files. Whether you’re using Blob Storage (HDFS) or Data Lake Store (WHDFS), both systems are splitting your files up and storing it across a range of disks. This means that we can be reading separate parts of the file in parallel, without causing any kind of I/O contention.
A standard, uncompressed file will be split into its component parts – essentially each 512mb is a separate extent to be accessed.

Whether this is a single file split into parallel chunks, or separate files, the Polybase table pulls the results of each thread together into a single data set that is returned by the query.
Another option is to compress the file – traditionally this speeds things up as we’re reducing the amount of data retrieved from disk, which is usually our largest bottleneck. However, Polybase cannot multi-thread a compressed file, so this reduces it to a single thread, which is inevitably slower.

If you’re really trying to optimise the performance, then you can get the best of both worlds. You can predict the number of threads that will be read in the file (ie: the number of 512mb chunks within the uncompressed file). If you then split the file into this number of separate flat files, then compress each file individually, you are both maintaining the level of parallelism whilst simultaneously reducing I/O impact.

Conclusions
Hopefully this has helped you to understand the part that Polybase plays in the SQLDW architecture. For further information, see the Azure CAT team’s guide to SQLDW loading patterns & best practices – http://bit.ly/2tezjxP
In the next post, we’ll discuss some of the limitations with the current Polybase implementation and ways that I’d like to see it improved.
Pareto Charts in Power BI and the DAX behind them
The Pareto principle, commonly referred to as the 80/20 rule, is a concept of prioritisation.
Apr
Databricks: Cluster Configuration
Databricks, a cloud-based platform for data engineering, offers several tools that can be used to
Apr
AI Assistance in Microsoft Fabric
The exponential growth of Large Language Models (LLMs) couples with Microsoft’s close partnership with OpenAI
Apr
10 reasons why it’s worth the effort to understand the value of your data
“If leaders really want to create a data driven culture, the journey starts with them!
Apr
Content Safety in Azure AI Studio
Azure AI Content Safety is a solution designed to identify harmful content, whether generated by
Apr
Model Benchmarks in Azure AI Studio
In the constantly changing field of artificial intelligence (AI) and machine learning (ML), choosing the
Apr
Celebrating International Women’s Day: from Classroom to Code
As we celebrate International Women’s Day, I want to share my journey of breaking stereotypes
Mar
Pretty Power BI – Adding Pagination to Bar Charts
Good User Experience (UX) design is crucial in enabling stakeholders to maximise the insights that
Feb